Many actions in the Rapid Recovery Core Console require you to enter account credentials.
After accounts have been added to the Credentials Vault, when prompted to authenticate, you can view the list of accounts and select an account with one click, rather than manually entering your account user name and password.
Follow this procedure to use an account from the Credentials Vault.
- From a location on the Rapid Recovery Core Console in which you are asked for credentials, click the downward-facing arrow
 in the User name field to expand the view.
in the User name field to expand the view.
The Credentials Vault drop-down grid appears. Each row shows the user name and description associated with an account held in the vault.
- If necessary, scroll through the list to identify the account for which you want to enter credentials. Then click on the row for the appropriate account.
The grid closes, and the account information is passed to the window or dialog box. Since passwords are hidden, the password field is not shown.
- Complete the function requiring credentials.
This section provides conceptual and procedural information to help you understand and configure replication in Rapid Recovery.
Replication is the process of copying recovery points from one Rapid Recovery Core and transmitting them to another Rapid Recovery Core for disaster recovery purposes. The process requires a paired source-target relationship between two or more Cores.
The source Core copies the recovery points of selected protected machines, and then asynchronously and continually transmits that snapshot data to the target Core.
Unless you change the default behavior by setting a replication schedule, the Core starts a replication job immediately after completion of every backup snapshot, checksum check, mountability check, and attachability check. Log truncation of any type also triggers a replication job, as does checking the integrity of recovery points or of an Oracle database. If any of these actions are included in nightly jobs, then completion of nightly jobs also triggers a replication job. For more information, see Scheduling replication.
|
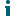
|
NOTE: When you replicate data for a cluster, you must replicate the entire cluster. For example, if you select a node to replicate, the cluster is automatically selected. Likewise, if you select the cluster, all nodes in that cluster are also selected. |
For optimum data security, administrators usually use a target Core at a remote disaster recovery site. You can configure outbound replication to a company-owned data center or remote disaster recovery site (that is, a “self-managed” target Core). Or, you can configure outbound replication to a third-party managed service provider (MSP) or cloud provider that hosts off-site backup and disaster recovery services. When replicating to a third-party target Core, you can use built-in work flows that let you request connections and receive automatic feedback notifications.
Replication is managed on a per-protected-machine basis. Any machine (or all machines) protected or replicated on a source Core can be configured to replicate to a target Core.
Possible scenarios for replication include:
- Replication to a local location. The target Core is located in a local data center or on-site location, and replication is maintained at all times. In this configuration, the loss of the Core would not prevent a recovery.
- Replication to an off-site location. The target Core is located at an off-site disaster recovery facility for recovery in the event of a loss.
- Replication to Microsoft Azure. The target Core is located in an Azure-hosted virtual machine and the repository is located in an Azure Blob Container. For more information, see Azure repositories.
- Mutual replication. Two data centers in two different locations each contain a Core and are protecting machines and serving as the off-site disaster recovery backup for each other. In this scenario, each Core replicates the protected machines to the Core that is located in the other data center. This scenario is also called cross replication.
- Hosted and cloud replication. Rapid Recovery MSP partners maintain multiple target Cores in a data center or a public cloud. On each of these Cores, the MSP partner lets one or more of their customers replicate recovery points from a source Core on the customer’s site to the MSP’s target Core for a fee.
|
|
NOTE: In this scenario, customers only have access to their own data. |
Possible replication configurations include:
- Point-to-point replication. Replicates one or more protected machines from a single source Core to a single target Core.
Figure 1: Point-to-point replication configuration
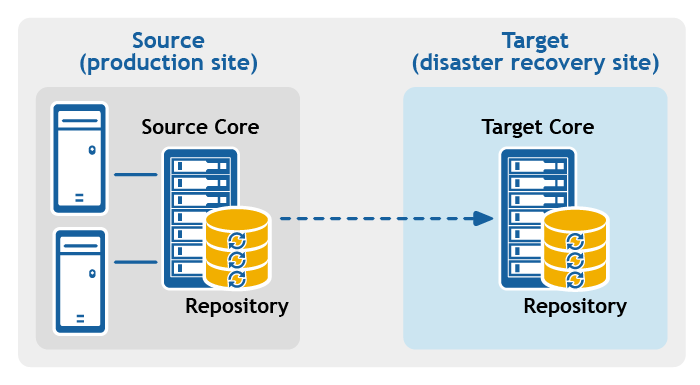
- Multipoint-to-point replication. Replicates protected machines from multiple source Cores to a single target Core.
Figure 2: Multipoint-to-point replication configuration
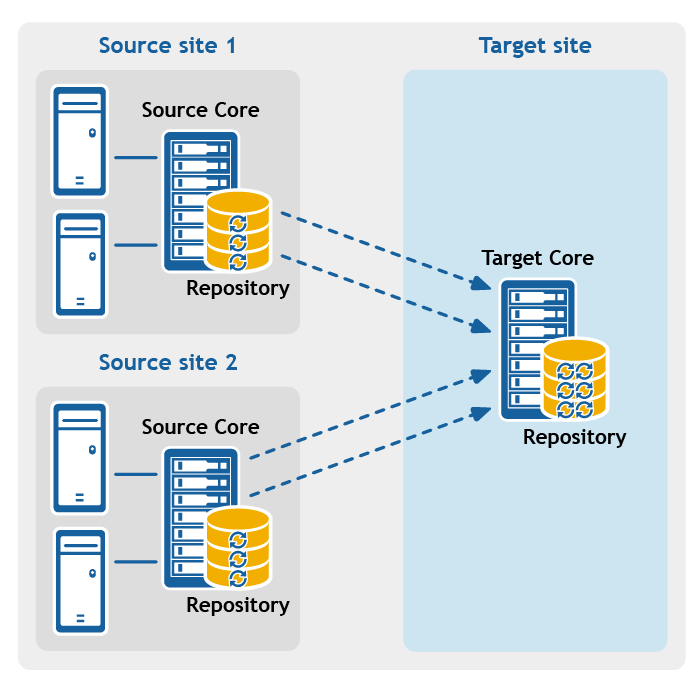
- Point-to-multipoint replication. Replicates one or more protected machines from a single source Core to more than one target Core.
Figure 3: Point-to-multipoint replication configuration
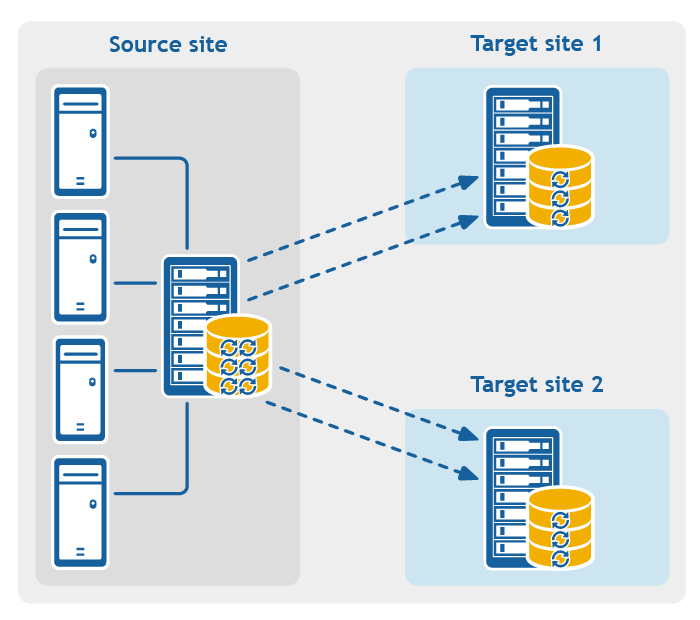
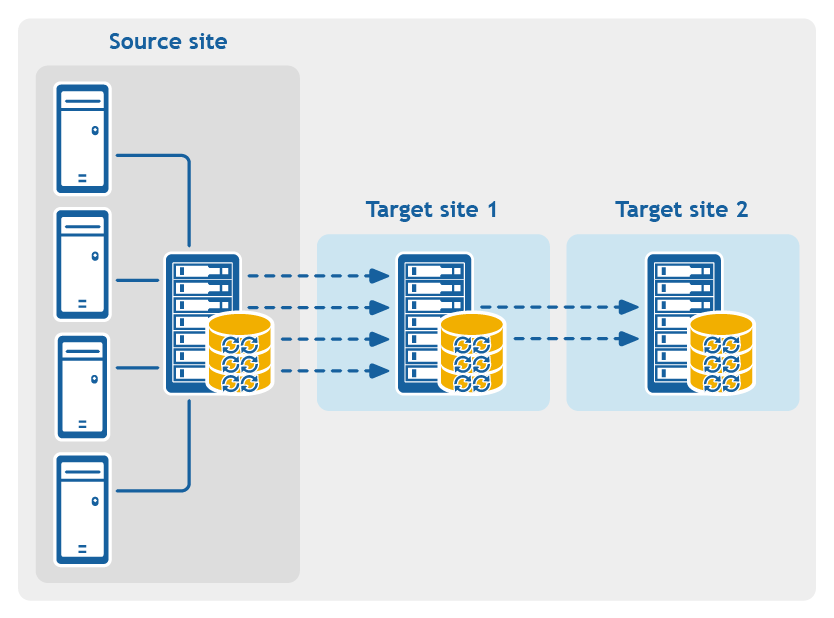
- Multi-hop replication. Replicates one or more protected machines from one target Core to another target Core, producing additional failover or recovery options on the replicated Core.
Figure 4: Multi-hop replication configuration
Rapid Recovery captures snapshots of a protected machine, and saves the data to a repository as a recovery point. The first recovery point saved to the Core is called a base image. The base image includes the operating system, applications, and settings for each volume you choose to protect, as well as all data on those volumes. Successive backups are incremental snapshots, which consist only of data changed on the protected volumes since the last backup. The base image plus all incremental snapshots together form a complete recovery point chain.
From a complete recovery point chain, you can restore data with ease and confidence, using the full range of recovery options available to Rapid Recovery. These options include file-level restore, volume-level restore, and bare metal restore.
Since logically you cannot restore from data that does not exist, in the case of an incomplete recovery point chain, you cannot restore data at the volume level or perform a bare metal restore. In such cases, you can still restore any data that does exist in a recovery point at the file level.
If the information you want to restore from a recovery point is in a previous backup that is not available to the Core (an earlier incremental snapshot or the base image), the recovery point is said to be orphaned. Orphaned recovery points are typical in some replication scenarios.
For example, when you first establish replication, your options for restoring data from the replicated recovery points are limited. Until all backup data from the source Core is transmitted to the target Core, creating full recovery point chains from the orphans, you can only perform file-level restore.
