Reviewing Foglight for SQL Server Alarms
Alarms are the warnings that Foglight for SQL Server raises when a metric falls outside its “normal” range of values, which is defined by setting thresholds and severities for the metric within the Metric editor. A new alarm is raised whenever the severity for a metric changes. When the severity returns to normal, the alarm is canceled.
Several alarms can be investigated using the home page’s Sessions pane and network packet flows, as follows:
The Response Time alarm becomes active when the execution time of the Response Time SQL exceeds a threshold.
Response time is the full time (in milliseconds) it has taken a query (select 1, by default) to get from the application to SQL Server and back. Every time a real-time sampled interval starts (by default: 20 seconds), a query is sent and its response time value is displayed. Any value higher than 20 ms may indicate a performance issue, which should then be investigated to detect its source, identify the possible bottleneck, and take correcting measures.
The Response Time SQL is a user-defined Transact-SQL batch that can be used for indicating application response time.
To change the query used for determining response time, edit the Response time section in the Agent properties.
The Packet Errors alarm becomes active when the rate at which SQL Server is encountering network packet errors exceeds a threshold.
When this alarm is fired, investigate what is causing the packet errors on the network.
Alarms Displayed in the SQL Processes Panel
Several alarms can be investigated using the SQL Processes panel, as follows:
The Blocking alarm is raised when at least one SQL Server session is waiting on a lock held by another session. The waiting user is said to be “blocked” by the one holding the lock, and waits until one of the following scenarios realizes:
Following any of these scenarios, the blocked command is cancelled.
Excessive blocking can be a major cause of poor application performance, as users of an application often do not realize they are waiting on a lock held by another user. From their point of view, it often seems like their application has stopped responding.
When this alarm occurs, look at:
|
• |
The Blocking panel on the SQL Activity drilldown, to see who is blocking whom, and what resources are involved (for example, database and table names). In the case of multiple blocks, where blocked sessions are also blocking others, this panel displays the sessions at the top of the tree (those that do not have a “parent” in the tree). These sessions, by being at the head of the blocking chain, are the root blockers. This panel also shows how many sessions were blocked over time. |
|
• |
The Sessions panel on the SQL Activity drilldown, to view the most recent SQL for the sessions involved in the blocking. This can help track down sub-optimal SQL that may contribute to the locking problem. |
|
• |
The Locks panel on the SQL Activity drilldown, to view all locks in the system. This panel displays all SQL Server locks currently granted or requested. |
The Deadlocks alarm becomes active when the number of deadlocks per second exceeds a threshold.
A Deadlock occurs when multiple SQL Server sessions request conflicting locks in such a way that two locks are blocked by one another.
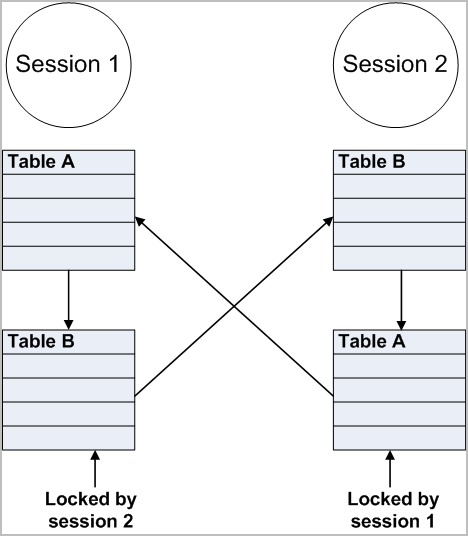
In this scenario, Session 1 is waiting on a lock held by Session 2, and Session 2 is waiting on one held by Session 1. In this example, to prevent both sessions from waiting forever, SQL Server enables only one session to continue and aborts the other session, by killing its connections and rolling back its updates. The user whose session is rolled back often receives an error message.
This scenario is relatively simple to resolve. However, deadlocks can involve many more sessions, which make it extremely difficult to track down the root cause of all the trouble. When this alarm occurs, review the Locks panel on the SQL Activity drilldown, to view the Deadlocks/sec counter on the Lock Types chart. This counter displays the frequency of deadlocks in the currently monitored system.
The Recompiles alarm becomes active when the ratio between the number of recompiles and the total number of compiles exceeds a threshold. This highlights when more than a certain percentage of compilations are due to run-time recompiles.
A compile can be a relatively time-consuming, CPU-intensive process, especially when the query or stored procedure is large or complex. For this reason, SQL Server stores execution plans in the Plan Cache, so that they would satisfy future I/O requests, thereby saving the need for physical reads from the disk.
A Recompile takes place when SQL Server Optimizer determines that the execution plan for a stored procedure that is currently executing may no longer be the optimal plan. SQL Server pauses the query execution and compiles the stored procedure again. This not only slows down the process that is executing the procedure, but adds extra CPU load on the server.
When many recompiles take place, the SQL Server’s CPU can become overloaded, thereby slowing down everything running on that computer. Therefore, it is advisable to keep the number of recompiles as low as possible.
A stored procedure can be recompiled by the SQL Server for various reasons, the most common of which are as follows:
|
• |
The use of the WITH RECOMPILE clause in the CREATE PROCEDURE or EXECUTE statement. |
|
• |
Running sp_recompile against any table referenced in the stored procedure. |
|
• |
On the SQL Activity drilldown, click SQL Instance Summary and view the Call Rates graph to determine if this is a persistent problem. Consistently high percentage of the Re-Compiles rate within the total Compiles rate requires further investigation. |
It is advisable to review the code of each of the stored procedures. Consider changing the stored procedures to remove coding practices that can cause recompiles.
The Error Log alarm becomes active when Foglight for SQL Server, which scans the error logs at the configured frequency, detects messages that could indicate potential problems in the SQL Sever error log or SQL Agent error log.
When this alarm occurs, look at the Error Log drilldown to view the errors.
To select which error logs generated by the SQL Server database are displayed in the Error Log drilldown, use the Error Log Scanning view in the Databases Administration dashboard. For details, see Defining Error Log Filtering .
Alarms Displayed in the SQL Memory Panel
Several alarms can be investigated using the SQL Memory panel, as follows:
The Buffer Cache Hit Ratio alarm becomes active when the ratio of physical reads to logical reads falls below a threshold.
SQL Server holds recently accessed database pages in a memory area called the Buffer Cache. If an SQL process needs to access a database page, finding this page in the buffer cache saves SQL Server the need to read the page from disk, thereby significantly reducing the amount of disk I/O and, in most probability, speeding up queries.
Buffer Cache Hit Ratio is the ratio of logical reads to physical reads. It indicates the percentage of database page I/O requests that were satisfied from the Buffer Cache and therefore did not have to perform disk reads. This ratio measures how efficiently SQL Server is using the memory allocated to its buffer cache.
A low Buffer Cache hit rate indicates that SQL Server is finding fewer pages already in memory, and therefore has to perform more disk reads. This is often caused by either lack of SQL Server memory or use of inefficient SQL queries, which are accessing a very large number of pages in a non-sequential manner. The best figure varies from one application to another, but ideally this ratio should be above 90%.
|
• |
View the Buffer Cache panel on the Memory drilldown to see the largest objects in the Buffer Cache. |
|
• |
Use the Sessions panel on the SQL Activity drilldown to identify inefficient SQL queries. Look for currently active sessions that are generating a lot of I/O. Such sessions can be traced also by using the Session Trace pane on the Sessions panel. |
The Free Buffers alarm becomes active when the amount of SQL Server memory available for immediate reuse drops below a threshold.
The Lazy Writer Process periodically scans all SQL Server caches, and maintains a list of “free” pages that are available for immediate reuse.
When SQL Server needs a free memory page (for example, when reading a database page from disk into the buffer cache), and no free pages are immediately available, the connection needing the free page must wait while SQL Server makes buffers available. This results in slower performance. In the worst case, the connection has to wait while SQL Server writes a modified page out to disk, in order to make a free buffer.
This alarm does not always indicate a problem with SQL Server, especially if the alarm is not active for more than 10-20 seconds.
|
• |
On the Memory drilldown, select the Summary panel. Check the Memory Areas chart to determine the amount of time for which the Free List has been very low. This alarm normally only indicates a problem if the Free List has been very low for more than a few minutes. |
|
• |
Check the Configuration drilldown to view the currently set recovery interval parameter. Setting this too high can cause the Checkpoint process to run infrequently, which can in turn cause the Lazy Writer process to perform the majority of the I/O that the Checkpoint process normally does. This can keep the Lazy Writer so busy that it does not maintain the Free List efficiently. |
The Page Life Expectancy alarm becomes active when the page life expectancy falls below a threshold.
Page life expectancy is the length of time in seconds that a database page will stay in the buffer cache without being accessed, before it is flushed out. Microsoft recommends keeping this value greater than five minutes (300 seconds).
Values smaller than 300 indicate that pages are being flushed out of the cache within a small period of time. The resulting lack of pages in the buffer cache requires SQL Server to carry out more disk reads, thereby degrading its performance.
This alarm is often invoked by memory shortage (either memory on the system or memory configured for SQL Server’s use) or use of inefficient SQL queries, which are accessing a very large number of pages in a non-sequential manner.
The Procedure Cache Hit Ratio alarm is raised when the ratio between the number of times SQL Server looks for a plan in the plan Cache, and the number of times it finds the requested plan in the plan Cache, falls below a threshold.
A low plan cache hit rate indicates that SQL Server is finding fewer of the query execution plans it needs already in memory, and therefore has to perform more compiles. These extra compilations degrade SQL Server performance by causing extra CPU load.
To prevent this alarm being caused by adhoc SQL requests (which often produce non-reusable execution plans), Foglight for SQL Server removes adhoc plan statistics from this metric.
|
• |
Check the Call Rates chart on the SQL Instance Summary panel of the SQL Activity drilldown for a high number of Re-Compiles. Follow the suggestions listed under the Recompiles alarm. |
|
• |
On the Memory drilldown, select the Plan Cache panel and then use the Hit Rate and Use Rate counters on the Object Types chart to identify which types of objects are causing the problem. |
Alarms Displayed in the Background Processes Panel
Several alarms can be investigated using the Background Processes panel, as detailed in the following sections:
The Cluster Server Down alarm is raised when Foglight for SQL Server detects that at least one cluster node (server) is not currently running as part of the cluster.
When this alarm is active, take these measures:
|
• |
Check the Cluster Services panel of the Support Services drilldown to determine which cluster node is unavailable. |
The log shipping alarm is invoked when the out-of-sync threshold has been exceeded for any log-shipping pairs, that is, when the time between the last backup of the source database and the restore in the target database has exceeded the allowed length specified. Because the log shipping operation comprises copy, backup and restore phases, the log shipping alarm can be invoked as a result of a failure to:
When the alarm is raised, it is accompanied by a prompt to go to the Log Shipping panel of the Support Services drilldown. For details, see Tracking the Status of the Mirroring Operation .
The Non-preferred Cluster Node alarm is raised when Foglight for SQL Server detects that SQL Server is not running on its preferred cluster node.
This alarm can be raised only when the currently connected SQL Server is running as part of a Microsoft Cluster Server (MSCS).
In a Windows cluster, each SQL Server instance belongs to a single cluster group. Preferred cluster nodes are allocated to each group. Normally, the group should run on these preferred cluster nodes.
The SQL Agent Alerts alarm is activated when Foglight for SQL Server detects that at least one SQL Agent alert has occurred in the last few minutes.
|
• |
On the Support Services drilldown, view the SQL Agent Alerts page to determine which alerts have occurred recently. This page displays the last occurrence time for each alert, and the alert history for the specified time range. |
The SQL Agent Job Failure alarm is activated when Foglight for SQL Server detects that at least one SQL Agent job has failed in the last few minutes.
|
• |
View the SQL Agent Jobs panel, on the Support Services drilldown, to determine which jobs have failed recently. Double-click any job to view the messages that it logged during its last run. This page displays the last run time and completion status of each job, as well as a graph showing which jobs ran recently, and the completion status for each run. |
The SQL Server I/O Errors Per Second alarm is raised when I/O errors are encountered by SQL Server.
The majority of I/O errors reported by SQL Server are caused by hardware failures, such as disk or controller failures.
The Support Services alarm becomes active when any of SQL Server's supporting services are installed, but not active.
The services currently monitored are detailed in the following list.
The Table Lock Escalation alarm is raised when the number of times page locks are escalated to table locks per second exceeds a threshold.
Lock escalation is not necessarily a problem by itself; however, it can cause concurrency issues and lock conflicts and can be a major contributor to blocking problems.
In certain cases, this alarm may also indicate use of inefficient SQL queries, which leads to a large number of page locks instead of enforcing one table lock, and therefore forces the SQL Server to escalate the lock to a table lock.
