
Configure horizontally partitioned replication
Use horizontally partitioned replication to divide the rows of a table into separate processing streams. You can use horizontally partitioned replication to:
- Replicate a subset of rows to a target, while retaining the rest of the rows in the source.
- Replicate different subsets of rows to different targets.
- Divide the replication of a source table into parallel Post queues for faster posting to the target table.
Supported sources
Oracle
Supported targets
All
Overview of horizontally partitioned replication
To configure horizontally partitioned replication for a table, the steps are:
-
Define row partitions and link them to a partition scheme.
-
A row partition is a subset of rows in a source table that you want to replicate as a group.
-
A partition scheme is a logical container for row partitions.
-
- Specify the name of the partition scheme in the SharePlex configuration file to include the partitions in replication.
Partition types
The row partitions in a partition scheme can be based on one of the following:
- Columns: A column-based partition scheme contains row partitions defined by a column condition. A column condition is a WHERE clause that defines a subset of the rows in the table.
- Hash: A hash-based partition scheme contains row partitions defined by a hash value that directs SharePlex to distribute rows evenly across multiple queues.
About column-based partition schemes
You can use row partitions based on column conditions for the following purposes:
- Use a single row partition to replicate only a subset of the rows of a table. For example, you can replicate only those rows where the value of the YEAR column is greater than 2014. The partition scheme in this case could be named "Since2014" or "Recent."
-
Use multiple row partitions to divide the rows of a table so that each set of rows replicates to a different target. For example, a table named CORPORATE.SALES could have two row partitions named "East" and "West." The column conditions are defined accordingly, where the rows that satisfy REGION = EAST replicate to one location and the rows that satisfy REGION = WEST replicate to a different location. The partition scheme could be named "Sales_by_region."
-
Use multiple row partitions to divide the rows of a table into parallel processing streams (parallel Export-Import-Post streams) for faster posting to a target table. For example, you can improve the flow of replication to a heavily updated target table. The use of column conditions for this purpose is appropriate only if the table contains a column that enables you to split the processing evenly among parallel Post processes.
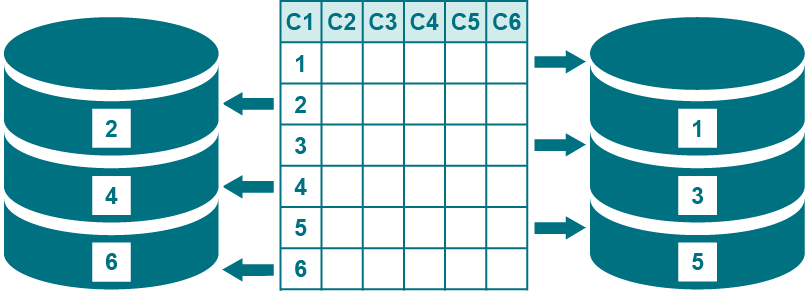
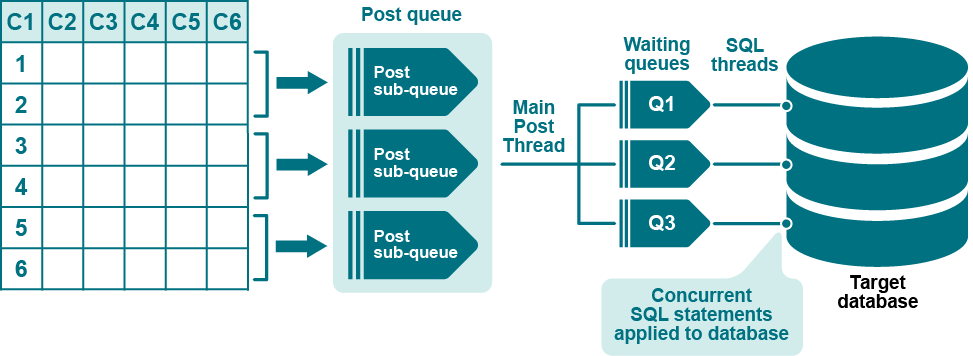
About hash-based partition schemes
You can use row partitions based on a hash value to divide the rows of a table into parallel processing streams (parallel Export-Import-Post) for faster posting to a target table. The advantage of using a hash value over column conditions to create partitions is that the rows are divided evenly and automatically by SharePlex, without the need to reference table columns in WHERE clauses. However, unlike column-based partition schemes, you cannot use the SharePlex compare or repair commands for hash-based partition schemes.
Combine partitioned replication with full-table replication
You can combine horizontally partitioned and vertically partitioned replication for maximum control over how information is distributed.
For example:
- A corporate headquarters maintains a master corporate database.
- Each of the corporation's four regional offices maintains its own database.
- Corporate headquarters uses vertically partitioned replication to share some column data of a table with the regional offices, but does not share any columns that contain sensitive data.
- The rows of the table are horizontally partitioned into four groups (East, West, North, South) for replication, so that each region receives only the record changes that apply to it.
Horizontally partitioned replication can be used in conjunction with full-table replication for the same table, for example to route groups of rows to different reporting systems and all rows to a backup system.
Limitations of use
Hash-based partitioning does not support the following:
- The compare and repair commands.
- Index-organized tables (IOT) and tables that contain LOBs or LONGs.
- Operations that delete or update a key value and then reinsert the same key value. This can cause unique constraint violations because of different rowids.
- Column-based partitioning on the same table.
Hash-based partitioning also does not support operations that cause rows to migrate into a different partition. Examples of such operations are:
- Update a value so that it moves to a new row partition
- Table reorganization
- Split a table partition or combine two partitions
- Export or import the table
- ALTER TABLE with the MOVE option
- ALTER TABLE with the SHRINK SPACE option
- FLASHBACK TABLE
- Redefine a table by using dbms_redefinition
- UPDATE to a non-partitioned table that changes row size so that the data does not fit into the current block
- DELETE of a row in a non-partitioned table and then re-insert.
Define partition schemes and row partitions
Use the add partition command to create row partitions and assign them to a partition scheme.
To partition rows based on column conditions
Issue add partition for each row partition that you want to create in a given partition scheme. When you create the first row partition, SharePlex creates the partition scheme as well.
sp_ctrl> add partition to scheme_name set condition = column_condition and route = routing_map [and name = name] [and tablename = owner.table] [and description = description]
To partition rows based on a hash value
Issue add partition once to specify the number of hash partitions to create.
sp_ctrl> add partition to scheme_name set hash = value and route = value
add partition command syntax
Note: After you specify add partition with to scheme_name and the set keyword, all other components can be in any order.
| Component | Description |
|---|---|
| to scheme_name |
to is a required keyword indicating the row partition is being added to scheme_name. scheme_name is the name of the partition scheme. The partition scheme is created by the first add partition command that you issue, which will also specify the first set of rows to partition. If you are making heavy use of horizontal partitioning, it may help to establish naming conventions for your partition schemes. |
|
set |
Required keyword that starts the definition of the row partition. |
| condition = column_condition |
Creates a row partition based on a column condition. The condition must be in quotes. Use standard WHERE conditional syntax such as ((region_id = West) and region_id is not null). The condition and hash components are mutually exclusive. |
| hash = value |
Creates a row partition based on a hash value. The specified value determines the number of row partitions in the partition scheme. The condition and hash components are mutually exclusive. |
| route = routing_map |
The route for this partition. This can be one of the following: Partition based on a column condition: Specify any standard SharePlex routing map, for example: sysB@o.myora or sysB:q1@o.myora or sysB@o.myora+sysC@o.myora (compound routing map). If the target is JMS, Kafka, or a file, then the target should be specified as x.jms, x.kafka, or x.file, for example: sysA:hpq1@x.kafka. To route a partition to multiple target tables that have different names, do the following:
Partition based on a hash: Use the following format to direct SharePlex to create a named post queue for each partition: host:basename|#{o.SID | r.database} where:
|
| name = name |
(Recommended) A short name for this partition. This option is only useful for partitions based on column conditions. A name eliminates the need to type out long column conditions in the event that you need to modify or drop the partition in the future. |
| tablename = owner.table |
(Optional) Use this option when there are multiple target tables and one or more have different names. Issue a separate add partition command for each name. The table name must be fully qualified. If case-sensitive, the name must be specified in quotes. Example: add partition to scheme1 set name = p1 and condition = "C1 > 200" and route = sysb:p1@o.orasid and tablename = myschema.mytable |
| description = description | (Optional) Description of this partition. |
Examples
Partitions based on a column condition
Route different sets of rows through different post queues:
sp_ctrl> add partition to scheme1 set name = q1 and condition = "C1 >= 200" and route = sysb:q1@o.orasid
sp_ctrl> add partition to scheme1 set name = q2 and condition = "C1 < 200" and route = sysb:q2@o.orasid
Route different sets of rows to different target systems and different table names from the source:
sp_ctrl> add partition to scheme1 set name = east and condition = "area = east" and route = sys1e@o.orasid and tablename = ora1.targ
sp_ctrl> add partition to scheme1 set name = west and condition = "area = west" and route = sys2w@o.orasid and tablename = ora2.targ
Partitions based on a hash
Divide rows into four partitions, each processing through a different post queue:
sp_ctrl> add partition to scheme1 set hash = 4 and route = sysb:hash|#@o.ora112
How to create a valid column condition
The following are guidelines for creating column conditions. These guidelines do not apply to row partitions that are created with a hash value.
Choose appropriate columns
The types of columns on which you base your column conditions vary per datasource:
Base column conditions on columns whose values will not change, such as PRIMARY or UNIQUE key columns. The objective is to avoid a partition shift, where changes made to the conditional columns of a partition can cause the underlying data to satisfy the conditions of a different (or no) partition.
Partition shift case 1: The column value is updated so that the new value no longer satisfies any column condition:
- SharePlex performs the operation, but future operations on that row are not replicated. The reason: the row no longer satisfies a column condition.
- The source and target tables of the original partition are now out of synchronization, but Post returns no errors.
Partition shift case 2: A row that satisfies one column condition gets updated to meet a different condition:
- Post cannot find a matching target row. The reason: the original change was not replicated because it did not meet the column condition.
- Post returns an out-of-sync error.
You can use the following method to repair the out-of-sync rows that are caused by changes to the values of column conditions:
- Use the compare command to repair the out-of-sync rows. For more information about this command, see the SharePlex Reference Guide.
Additionally, you can ensure that data is replicated properly by setting the following parameter on the source prior to activating the configuration file.
- Set the SP_ORD_HP_IN_SYNC parameter to a value of 1. When this parameter is enabled, if an UPDATE changes a column (conditional column) value resulting in a row that no longer satisfies the correct condition, SharePlex corrects the row. Enabling this parameter causes some performance degradation, depending on how many tables are configured for horizontally partitioned replication. See the SharePlex Reference Guide for more information and a list of conditions corrected by this parameter.
Note: If you are using a column other than a key to base the column condition on, and you notice reduced performance with horizontally partitioned replication enabled, add a log group for that column.
Use supported data types
SharePlex supports the following data types in column conditions:
- NUMBER
- DATE
- CHAR
- VARCHAR
- VARCHAR2
- LONG VARCHAR
Notes:
-
For the dates, SharePlex uses MMDDSYYYYHH24MISS. For example:
hiredate<‘1111 2011000000’
-
Horizontally partitioned replication does not support the following:
- data types other than the ones listed in this section. This also excludes large types like LOBs and object types such as VARRAYs and abstract data types.
- Oracle TO_DATE function
- UPDATEs or INSERTs on LONG columns larger than 100k
- Sequences
- TRUNCATEs of an Oracle partition
Use standard conditional syntax
The following list shows the conditional syntax that SharePlex supports in a column condition, where:
- value can be a string or a number. Enclose strings and dates within single quote marks (‘west’). Do not use quote marks for numbers .
- column is the name of a column in the table that you are configuring to use horizontally partitioned replication.
|
column = value
not (column = value)
column > value
value > column
column < value
column <= value
column >= value
column <> value
column != value
column like value
column between value1 and value2
not (column between value1 and value2 )
column is null
column is not null |
Conditions can be combined into nested expressions with parentheses and the AND, OR, and NOT logical connectives.
Example column conditions
Additional guidelines
- NULLs are replicated by SharePlex in cases such as this one: not (department_id = 90). If department_id is NULL, it is replicated. To avoid replicating records with NULLs, include the column is not null syntax as part of the condition, for example: not (department_id = 90) and department_id is not null.
- If parentheses are not used to indicate operator precedence, SharePlex supports operator precedence in the same order that SQL does. For example, a condition not x and y behaves the same way as (not x) and y. A condition x and y or z behaves the same as (x and y) or z. When a condition includes parentheses, the explicit precedence is respected.
- If the condition column is a VARCHAR column and the values used to define the partitions are string literals, the entire condition must be enclosed in double quotes, as in the following example: add partition to scheme set route=route and condition="C2 = 'Fred'"
- If the column name must be enclosed in quotes, then the entire condition must be enclosed in quotes, as in the following example: add partition to scheme set route=route and condition="\"c2\" > 0"
-
Do not:
- include references to other tables in the column condition.
- exceed the 1024 bytes maximum defined storage.
- During the activation of a configuration that refers to partition schemes, SharePlex verifies the syntax in the column conditions of those schemes. If any syntax is incorrect, the activation fails. SharePlex prints an error to the Event Log that indicates where the error occurred.
Specify partition schemes in the configuration file
Use one configuration file for all of the data that you want to replicate from a given datasource, including tables that will have full-table replication and those that will use partitioned replication. To configure entries for horizontally partitioned replication, use the following syntax.
| Datasource: o.SID | ||
| src_owner.table | tgt_owner.table |
!partition_scheme |
| ! | routing_map | |
| Component | Description |
|---|---|
|
o.database |
The datasource designation. Use the o. notation for an Oracle source. For database, specify the ORACLE_SID. |
| src_owner.table and tgt_owner.table | The specifications for the source and target tables, respectively. |
| !partition_scheme |
The name of the partition scheme to use for the specified source and target tables. The ! is required. The name is case-sensitive. Compound routing of multiple partition schemes is not supported, for example !schemeA+schemeB. Create a separate entry for each partition scheme that you want to use for the same source table. See Examples. |
| ! routing_map |
A placeholder routing map. It is required only if a route that you used in a partition scheme is not listed somewhere in the configuration file. SharePlex requires every route to be in the configuration file even if it is listed in a partition scheme.
See Examples. |
Examples
To specify a partition scheme:
| Datasource: o.mydb | ||
| scott.emp | scott.emp_2 | !partition_emp |
To specify multiple partition schemes for the same source table:
| Datasource: o.mydb | ||
| scott.emp | scott.emp_2 | !partition_schemeA |
| scott.emp | scott.emp_3 | !partition_schemeB |
To specify a placeholder routing map:
| ! targsys1 |
| ! targsys2@o.ora2+targsys3@o.ora3 |
This placeholder is only required for partitions based on column conditions.
View the partitions and schemes
Use the view partitions command to view the row partitions in one partition scheme or all partition schemes in a horizontally partitioned replication configuration.
To view row partitions
- Run sp_ctrl on the source system.
-
Issue the following command with either option, depending on whether you want to view all partitions or just those for a particular partition scheme.
sp_ctrl> view partitions for {scheme_name | all}
The following example shows both a hash-based partition scheme and a column-based partition scheme.
sp_ctrl> view partitions all
Scheme Name Route Hash Condition ----------- ------------- ------------------------------ ------ --------------- HASH4 hash sys02:hash|#@o.ora112 4 ROWID TEST_CT highvalues sys02:highvalues@o.ora112 sales>=10000 TEST_CT lowvalues sys02:lowvalues@o.ora112 sales<10000
Hash4 hash-based partition scheme
- The Scheme column shows a partition scheme named HASH4.
- The Name column shows that the name for the partition definition is hash.
- The Route column shows that the partitions are created automatically and that the target is o.ora112.
- The Hash column has a value of 4, which indicates that this is a hash-based partition scheme with four partitions.
- The Condition column shows that the type of hash algorithm that is being used is the default of rowid, rather than block.
TEST_CT column-based partition scheme
- The Scheme column shows a partition scheme named TEST_CT. There are two entries for this name, indicating that it contains two partitions.
- The Name column shows the name of each partition, which by default is the name of the post queue or the value set with the Name option of the add partition command.
- The Route column shows that the names of the post queues are based on the parition name and that the target is o.ora112.
- The Hash column is empty for a column-based partition scheme.
- The Condition column shows the column condition that creates the row partition.
To view partition post queues
The qstatus command on the target shows the post queues that are associated with horizontally partitioned replication.
Queues for TEST_CT column-based partition scheme
sp_ctrl sys02> qstatus
Queues Statistics for sys02
Name: highvalues (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: lowvalues (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Queues for HASH4 hash-based partition scheme:
Queues Statistics for sys02
Name: hash1 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash2 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash3 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash4 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Make changes to partition schemes
The following commands or parameters are available to manage partition schemes. For more information, see the SharePlex Reference Guide.
|
Task |
Command/Parameter |
Description |
|---|---|---|
|
Modify a partition |
modify partition command |
Modifies any of the attributes of a row partition definition. |
|
Remove a partition scheme |
drop partition scheme command |
Removes the partition scheme and all row partitions within it. |
|
Change hash algorithm |
SP_OCF_HASH_BY_BLOCK |
Change the hash algorithm from the default of rowid-based to block-based. Set to 1 to enable block-based algorithm. |