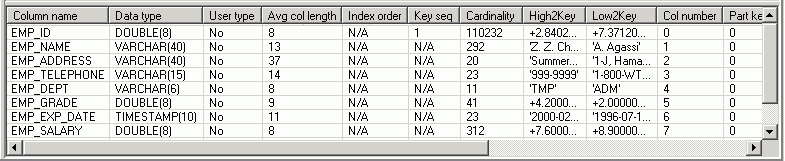
The Column Statistics pane is displayed on the Access Plan tab in the SQL Optimizer window. It lists information about each column in the object highlighted in the Object Statistics or Index Statistics pane. This information is retrieved from the SYSCAT.COLUMNS catalog view excepted for the Index order statistic, which is obtained from SYSCAT.INDEXCOLUSE catalog view.
The average length of the values in the column.
This information is based on the AVGCOLLEN value for the column in SYSCAT.COLUMNS.
The number of rows in a database table.
This information is based on the COLCARD value for the column in SYSCAT.COLUMNS.
The numerical position of the column in the table or view, beginning at zero.
This information is based on the COLNO value for the column in SYSCAT.COLUMNS.
The name of the column.
This information is based on the COLNAME value for the column in SYSCAT.COLUMNS.
The data type of the column along with the length and scale (if applicable).
This information is based on the TYPENAME, LENGTH and possibly the SCALE value for the column in SYSCAT.COLUMNS.
The column’s default value appropriate for the column’s data type. This value can be the keyword NULL.
This information is based on the DEFAULT value for the column in SYSCAT.COLUMNS.
The second highest value in this column.
This information is based on the HIGH2KEY value for the column in SYSCAT.COLUMNS.
The order of the values in this column within the index. Statistic values include:
|
Value |
Description |
|
Ascending |
Ascending order |
|
Descending |
Descending order |
|
Include |
INCLUDE column (ordering ignored) |
The column’s numerical position within the primary key for the table or view. The value N/A appears if the column is not part of the primary key.
This information is based on the KEYSEQ value for the column in SYSCAT.COLUMNS
The second lowest value in this column.
This information is based on the LOW2KEY value for the column in SYSCAT.COLUMNS.
The number of NULL values in the column.
This information is based on the NUMNULLS value for the column in SYSCAT.COLUMNS.
Indicator as to whether the column can contain a NULL value.
|
Value |
Description |
|
Yes |
The column is nullable. |
|
No |
The column is not nullable. |
The column’s numerical position within the table’s partitioning key for the table or view. The value 0 or NULL is displayed if the column is not part of the partitioning key. Additionally, if the table is a hierarchy table or a subtable in a hierarchy, the value NULL is displayed.
This information is based on the PARTKEYSEQ value for the column in SYSCAT.COLUMNS.
The qualified name of the data type if the type is user defined (or distinct). A user-defined type has a qualified name other than SYSIBM. If the data type is not distinct (that is, its qualified name is SYSIBM), the value No appears.
This information is based on the TYPESCHEMA value for the column in SYSCAT.COLUMNS.
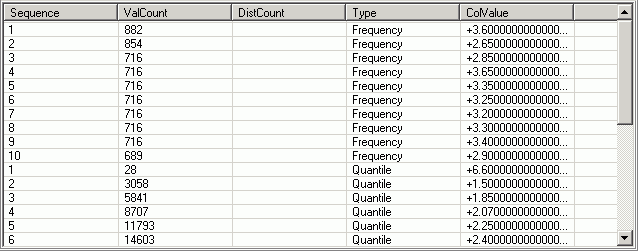
The Column Values Distribution Statistics pane is displayed on the Access Plan tab in the SQL Optimizer window. It lists statistics used by DB2's SQL optimizer to handle non-uniform distribution of column values. For the column highlighted in the Column Statistics pane, this pane describes the position of column values in the order of most frequently used values or in quantile order. SQL Optimizer obtains this information from the SYSCAT.COLDIST catalog view. The DB2's SQL optimizer uses this information to estimate more accurately the number of rows in a column that satisfy the specified equality or range predicates.
The position of the column value (listed for ColValue) within the order of most frequently used values or within the quantile order.
If Type is Frequency, the sequence number n identifies the column value as the nthe most frequent value for the column.
If Type is Quantile, the sequence number n identifies the column value as the nth quantile value for the column.
The count for the column value listed for ColValue. The meaning of this count depends on the type of statistics collected for the column value: frequency or quantile.
If Type is Frequency, the value count is the number of rows that contain this value in the column.
If Type is Quantile, the value count is the number of rows containing values in the column that are less than or equal to ColValue.
In a partitioned database, ValCount is the estimated value of the count at the database partition multiplied by the number of database partitions. However, when Type is Frequency and the column is the single-column partitioning key of the table, ValCount is simply the count at the database partition.
The number of distinct values in the column that are less than or equal to the column value listed under ColValue.
Note: This count is collected only for columns that are the first key column in an index.
The type of distribution statistics collected for the column value listed under ColValue:
|
Value |
Description |
|
Frequency |
The statistics show the values for the highest number of duplicate values in the column. The number of rows displayed is dependent upon the num_freqvalues database configuration parameter or the value that was specified when the table statistics were updated. |
|
Quantile |
Statistics about value’s quantile position in the column are collected. The number of rows displayed is dependent upon the num_quantiles database configuration parameter or the value that was specified when the table statistics were updated.. |
The value of data in the column displayed as a character literal or as a NULL value.
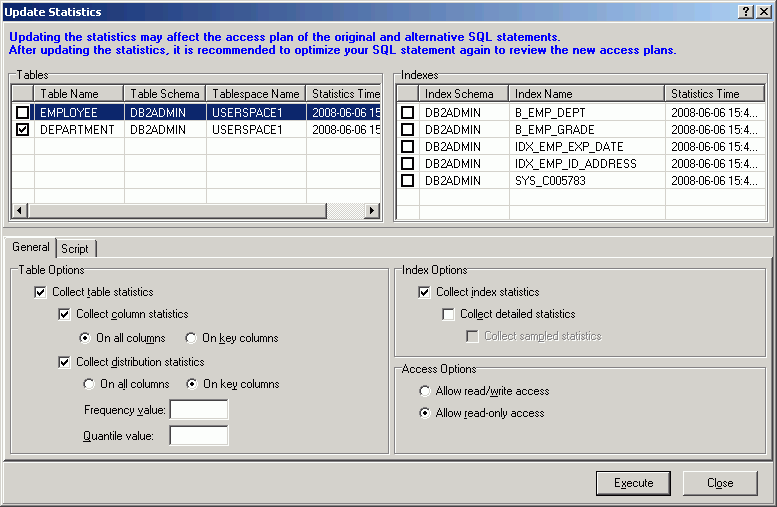
You can update the statistics for the tables and their indexes when you are viewing the Access Plan tab.
To update the statistics for a table
Right-click the table in the Table Statistics pane. and select Update Statistics.
In the Update Statistics window, select one or more tables to update.
In the Table Options section, select the specific options for updating the table statistics.
Note: This table only covers unfamiliar information. It does not include all field descriptions.
|
Frequency value |
Specify the maximum number of frequency values to collect for columns values distribution.
If you do not specify a value, the num_freqvalues database configuration parameter is used. |
|
Quantile value |
Specify the maximum number of quantile values to collect for columns values distribution.
If you do not specify a value, the num_quantiles database configuration parameter is used. |
Check the indexes to update for each table you have checked.
In the Index Options section, select the specific options for updating the index statistics.
Click the Script tab and review the RUNSTATS command.
Click Execute.
Note: In order to update statistics, you must have these privileges:
SYSADM
SYSCTRL
SYSMAINT
DBADM
CONTROL privilege on the table
LOAD authority
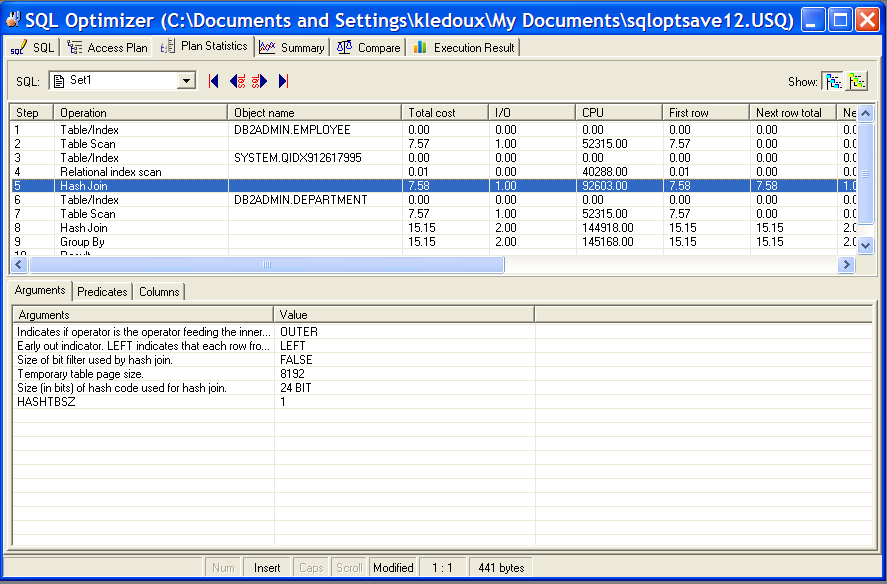
The Plan Statistics tab in the SQL Optimizer window displays the cost for each step in the access plan for the currently selected SQL or index-set alternative, along with the plan's arguments and values, its predicates, and the columns involved in the data stream.
The Cost Statistics pane provides detailed descriptions of each operation used in the access plan.
The following statistics are shown for each row of the access plan:
| Statistic | Description |
|---|---|
| Buffers | The estimated cumulative number of logical read requests for data pages that have gone through the buffer pool. This value is expressed in 4KB page units. |
| Communication | The estimated cumulative communication cost of executing the access plan up to and including the operation specified in the selected step. This value is expressed in TCP/IP frame units. |
| CPU | The estimated cumulative number of CPU instructions required to execute the access plan up to and including the operation specified in the selected step. |
| First row | The estimated cumulative cost of fetching the first row of data for the access plan up to and including the operation specified in the selected step. This statistic is expressed in timeron units. |
| First row comm. | The estimated cumulative communication cost of fetching the first row of data for the plan up to and including the operation specified in the selected step. This statistic is expressed in TCP/IP frame units. |
| I/O | The estimated total number of I/Os required for the access plan, up to and including the operation specified in the selected step. This value is expressed in units of 4KB pages. |
| Next row CPU | The estimated cumulative number of CPU instructions required to fetch the second row of data for the plan up to and including the operation specified in the selected step. |
| Next row I/O | The estimated cumulative number of I/Os required to fetch the second row of data for the plan up to and including the operation specified in the selected step. This statistic is expressed in timeron units. |
| Next row total | The estimated cumulative cost of fetching the second row of data up to and including the operation specified in the selected step. This statistic is expressed in timeron units. |
| Object name | The name of the table, view, or alias involved in the operation. |
| Operation | A brief description of the operation performed on the data, as specified in the selected access plan step. |
| Remote comm. | The estimated cumulative communication cost of executing the remote access plan up to and including this operator. This statistic is expressed in TCP/IP frame units. |
| Remote total | The estimated cumulative cost of performing operations on a remote database for this access plan up to and including the operation specified in the selected step. This statistic is expressed in timeron units. |
| Step | The number of the step within the sequence of steps performed in the access plan. |
| Total cost | The estimated cumulative cost of executing the access plan up to and including the operation specified in the selected step. This statistic is expressed in timeron units. |
To see the Argument, Predicate, and Column information for a specific step
The Arguments tab lists the arguments and their values that are used in the access plan operation highlighted in the Statistic pane.
The Predicates tab provides information about the SQL predicates that the operation highlighted in the Statistic pane is processing.
The following information shows for each predicate:
The text of the predicate as interpreted by the SQL compiler.
The estimated fraction of rows that the predicate qualifies.
The label specifying how the predicate is used in the operation:
| Value | Description |
|---|---|
| JOIN | Used to join tables |
| RESID | Evaluated as a residual predicate |
| SARG | Evaluated as a sargable predicate for index or data pages |
| START | Used as a start condition |
| STOP | Used as a stop condition |
The label specifying when the subquery used in this predicate is evaluated:
| Value | Description |
|---|---|
| blank | The predicate does not contain a subquery. |
| EAA | (Evaluated at application) The subquery is re-evaluated each time the operation applies the predicate to a row. |
| EAO | (Evaluated at open) The subquery is evaluated once for the operation. The subquery results are reused each time the operation applies the predicate to a row. |
| MUL | (Multiple) More than one type of subquery exists for this predicate. |
The label specifying the type of relational operator used in the predicate:
| Value | Description |
|---|---|
| blank | Not applicable |
| EQ | Equals |
| GE | Is greater than or equal to |
| GT | Is greater than |
| IN | Is in list |
| LE | Is less than or equal to |
| LK | Is like |
| LT | Is less than |
| NE | Is not equal to |
| NL | Is null |
| NN | Is not null |
The flag indicating whether or not the predicate requires a data stream from a subquery:
| Value | Description |
|---|---|
| N | No subquery stream is required. |
| Y | One or more subquery streams are required. |
The Columns tab lists the table columns involved in the data stream for the access plan operation highlighted in the Cost Statistics pane.