
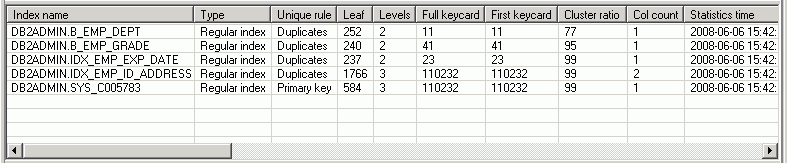
The Index Statistics pane is displayed on the Access Plan tab in the SQL Optimizer window. It lists information about each index that exists for the highlighted object in the Object Statistics pane. Additionally, if the operation in the selected access plan step uses an index, this index is automatically highlighted in the Index Statistics pane. You can do the following in this pane:
Select any index to view statistics about the columns for the index. (The appropriate column rows are highlighted in the Column Statistics pane.)
Right-click a specific index to update its catalog statistics.
Note: If the object highlighted in the Object Statistics pane is a view, then no indexes display in the Index Statistics pane.
For each index listed in the Index Statistics pane, the following information is obtained from the SYSCAT.INDEXES catalog view:
The number of columns that make up the index key for the index, plus any INCLUDE columns, which are additional non-key columns maintained in a unique index.
This information is based on the COLCOUNT value for the index in SYSCAT.INDEXES.
The ratio of the number of table rows that are ordered on data pages in index key sequence to the total number of table rows. This value is expressed as a decimal value between 0 and 1, with a higher precision than the Cluster Ratio. The optimizer uses this statistic to estimate the I/O cost of reading data pages into the bufferpool. The value –1 is used to indicate that no statistics are available.
Note: Either this statistic or the Cluster Ratio—not both—is recorded in the SYSCAT.INDEXES catalog. Generally, only one of the indexes for a table can have a high degree of clustering.
This information is based on the CLUSTERFACTOR value for the index in SYSCAT.INDEXES.
The ratio of the number of table rows that are ordered on data pages in index key sequence to the total number of table rows. This value is expressed as a percentage (a whole number between 0 and 100). The optimizer uses this statistic to estimate the I/O cost of reading data pages into the bufferpool. The value –1 is used to indicate that no statistics are available.
Note: Either this statistic or the Cluster Factor—not both—is recorded in the SYSCAT.INDEXES catalog. Generally, only one of the indexes for a table can have a high degree of clustering.
This information is based on the CLUSTERRATIO value for the index in SYSCAT.INDEXES.
The user who created the index.
This information is based on the DEFINER value for the index in SYSCAT.INDEXES.
The ratio of the Seq Pages value to the total number of pages occupied by the index. This ratio is expressed as a percentage.
This information is based on the DENSITY value for the index in SYSCAT.INDEXES.
The type of table on which the index is based:
|
Value |
Description |
|
Untyped Table |
A regular table or view (or the alias or nickname referring to a regular table). In a regular table, the data type for each column is defined separately in the CREATE TABLE statement. |
|
Typed Table |
A table based on a user-defined structured type. In a typed table, the column definitions are derived from attributes in the structured type on which the table was created. Note that a typed table can be a supertable or a subtable within a table hierarchy. (A subtable inherits its column definitions from the supertable.) |
|
Hierarchy Table |
A hierarchy table, which contains one column for each unique column in the table hierarchy. DB2's SQL optimizer uses this table to generate access plans for queries written against the individual tables in the hierarchy. |
The number of distinct key values based on the first column in the index key.
This information is based on the FIRSTKEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct keys using the first two columns of the index. (The value -1 is used if statistics have never been updated or if this statistic does not apply to the index key.)
This information is based on the FIRST2KEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct keys using the first three columns of the index. (The value -1 is used if statistics have never been updated or if this statistic does not apply to the index key.)
This information is based on the FIRST3KEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct keys using the first four columns of the index. (The value -1 is used if statistics have never been updated or if this statistic does not apply to the index key.)
This information is based on the FIRST4KEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct values for the index key. If the index key is unique, the Full Keycard value is equal to the number of rows in the table, or the table’s cardinality. If the index key is not unique, the Full Keycard value is equal to the number of distinct values available for the key. For example, if the index key is made up of one column called Status, which has three possible values--Paid, Billed, or Late, the Full Keycard value is 3.
This information is based on the FULLKEYCARD value for the index in SYSCAT.INDEXES.
The qualified name of the index.
This information is based on the INDSCHEMA and INDNAME values for the index in SYSCAT.INDEXES.
The internal ID of the index.
This information is based on the IID value for the index in SYSCAT.INDEXES.
The number of leaf pages in the index.
This information is based on the NLEAF value for the index in SYSCAT.INDEXES.
The number of non-leaf and leaf levels in the B+ structure of the index.
This information is based on the NLEVELS value for the index in SYSCAT.INDEXES.
Indicator as whether the index was converted from a non-unique to a unique index to support a unique or primary key constraint. (If you drop the constraint, the index reverts to non-unique.)
|
Value |
Description |
|
Yes |
The index was converted to unique. |
|
No |
The index remains as it was created. |
The minimum percentage of used space allowed before the online index reorganization feature merges index pages. (This number is expressed as an integer between 0 and 99.) This statistic is not available for a nickname.
This information is based on the MINPCTUSED value for the index in SYSCAT.INDEXES.
A list of integer pairs that provide page fetch estimates for different buffer sizes. The first integer in a given pair represents the number of pages in a hypothetical buffer. The second integer in the pair represents the number of pages fetches required to scan the table with the index using the hypothetical buffer. DB2's SQL optimizer uses this information to estimate the cost of reading data pages into the bufferpool when the Cluster Ratio statistic is not available.
This information is based on the PAGE_FETCH_PAIRS value for the index in SYSCAT.INDEXES.
The percentage of space on each leaf page that is available for future inserts. (This value is determined when the index is created.)
This information is based on the PCTFREE value for the index in SYSCAT.INDEXES.
Indicator as to whether the index supports reverse scans, enabling DB2's Index Manager to scan the index in a forward and backward direction to retrieve data:
|
Value |
Description |
|
Yes |
The index supports reverse scan. |
|
No |
The index does not support reverse scans. |
The number of leaf pages located physically located in index key order with few or not large gaps between them.
This information is based on the SEQUENTIAL_PAGES value for the index in SYSCAT.INDEXES.
The timestamp for the last time a change was made to statistics for the index.
This information is based on the STATS_TIME value for the index in SYSCAT.INDEXES.
Indicator as to whether the index is required by the system:
|
Value |
Description |
|
1 |
The index is required for a primary or unique key constraint or is required as the index on the OID column in a typed table. |
|
2 |
The index is required for a primary or unique key constraint and is required as the index on the OID column in a typed table. |
|
3 |
The index is not required. |
The type of index. This value is based on the INDEXTYPE value for the index in SYSCAT.INDEXES.
|
Value |
Description |
|
Block |
A composite block index, which contains the key columns for all dimensions in a multi-dimensional clustering (MDC) table |
|
Clustering |
The table’s clustering index |
|
Dimension block |
An index containing pointers to each occupied extent for a single dimension in a multi-dimensional clustering (MDC) table |
|
Regular* |
A non-clustering index on the table |
|
Virtual (R) |
A recommended virtual index on the table |
|
Virtual (U) |
A user-defined virtual index on the table |
The number of columns that make up the unique key in the index (if the index has a unique key).
This information is based on the UNIQUE_COLCOUNT value for the index in SYSCAT.INDEXES.
The type of unique constraint that the Database Manager enforces using the index key during the execution of any operation--such as an INSERT or UPDATE--that changes data values in the table.
|
Value |
Description |
|
Duplicates |
The index key has no unique constraint. Duplicate key values are allowed in the table. |
|
Primary Index |
The index key enforces a primary key constraint. No two primary key values in the table can be equal. The columns that make up the primary key cannot contain NULL values. |
|
Unique |
The index key enforces a unique constraint on the table. No two unique key values in the table can be equal. The columns that make up the unique key cannot contain NULL values. |
The indicator as to whether the index is user defined (using the CREATE INDEX statement) or system defined.
|
Value |
Description |
|
Yes |
The index is user defined and has not been dropped. |
|
No |
The index is system defined or automatically created at the time when the database was installed. |
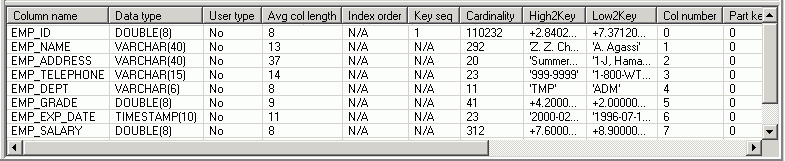
The Column Statistics pane is displayed on the Access Plan tab in the SQL Optimizer window. It lists information about each column in the object highlighted in the Object Statistics or Index Statistics pane. This information is retrieved from the SYSCAT.COLUMNS catalog view excepted for the Index order statistic, which is obtained from SYSCAT.INDEXCOLUSE catalog view.
The average length of the values in the column.
This information is based on the AVGCOLLEN value for the column in SYSCAT.COLUMNS.
The number of rows in a database table.
This information is based on the COLCARD value for the column in SYSCAT.COLUMNS.
The numerical position of the column in the table or view, beginning at zero.
This information is based on the COLNO value for the column in SYSCAT.COLUMNS.
The name of the column.
This information is based on the COLNAME value for the column in SYSCAT.COLUMNS.
The data type of the column along with the length and scale (if applicable).
This information is based on the TYPENAME, LENGTH and possibly the SCALE value for the column in SYSCAT.COLUMNS.
The column’s default value appropriate for the column’s data type. This value can be the keyword NULL.
This information is based on the DEFAULT value for the column in SYSCAT.COLUMNS.
The second highest value in this column.
This information is based on the HIGH2KEY value for the column in SYSCAT.COLUMNS.
The order of the values in this column within the index. Statistic values include:
|
Value |
Description |
|
Ascending |
Ascending order |
|
Descending |
Descending order |
|
Include |
INCLUDE column (ordering ignored) |
The column’s numerical position within the primary key for the table or view. The value N/A appears if the column is not part of the primary key.
This information is based on the KEYSEQ value for the column in SYSCAT.COLUMNS
The second lowest value in this column.
This information is based on the LOW2KEY value for the column in SYSCAT.COLUMNS.
The number of NULL values in the column.
This information is based on the NUMNULLS value for the column in SYSCAT.COLUMNS.
Indicator as to whether the column can contain a NULL value.
|
Value |
Description |
|
Yes |
The column is nullable. |
|
No |
The column is not nullable. |
The column’s numerical position within the table’s partitioning key for the table or view. The value 0 or NULL is displayed if the column is not part of the partitioning key. Additionally, if the table is a hierarchy table or a subtable in a hierarchy, the value NULL is displayed.
This information is based on the PARTKEYSEQ value for the column in SYSCAT.COLUMNS.
The qualified name of the data type if the type is user defined (or distinct). A user-defined type has a qualified name other than SYSIBM. If the data type is not distinct (that is, its qualified name is SYSIBM), the value No appears.
This information is based on the TYPESCHEMA value for the column in SYSCAT.COLUMNS.
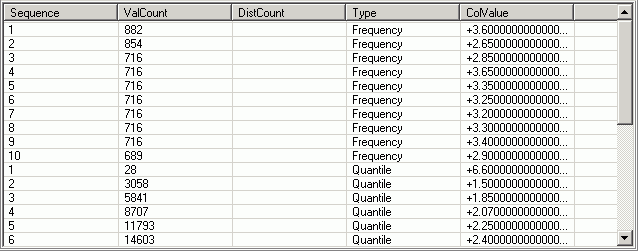
The Column Values Distribution Statistics pane is displayed on the Access Plan tab in the SQL Optimizer window. It lists statistics used by DB2's SQL optimizer to handle non-uniform distribution of column values. For the column highlighted in the Column Statistics pane, this pane describes the position of column values in the order of most frequently used values or in quantile order. SQL Optimizer obtains this information from the SYSCAT.COLDIST catalog view. The DB2's SQL optimizer uses this information to estimate more accurately the number of rows in a column that satisfy the specified equality or range predicates.
The position of the column value (listed for ColValue) within the order of most frequently used values or within the quantile order.
If Type is Frequency, the sequence number n identifies the column value as the nthe most frequent value for the column.
If Type is Quantile, the sequence number n identifies the column value as the nth quantile value for the column.
The count for the column value listed for ColValue. The meaning of this count depends on the type of statistics collected for the column value: frequency or quantile.
If Type is Frequency, the value count is the number of rows that contain this value in the column.
If Type is Quantile, the value count is the number of rows containing values in the column that are less than or equal to ColValue.
In a partitioned database, ValCount is the estimated value of the count at the database partition multiplied by the number of database partitions. However, when Type is Frequency and the column is the single-column partitioning key of the table, ValCount is simply the count at the database partition.
The number of distinct values in the column that are less than or equal to the column value listed under ColValue.
Note: This count is collected only for columns that are the first key column in an index.
The type of distribution statistics collected for the column value listed under ColValue:
|
Value |
Description |
|
Frequency |
The statistics show the values for the highest number of duplicate values in the column. The number of rows displayed is dependent upon the num_freqvalues database configuration parameter or the value that was specified when the table statistics were updated. |
|
Quantile |
Statistics about value’s quantile position in the column are collected. The number of rows displayed is dependent upon the num_quantiles database configuration parameter or the value that was specified when the table statistics were updated.. |
The value of data in the column displayed as a character literal or as a NULL value.
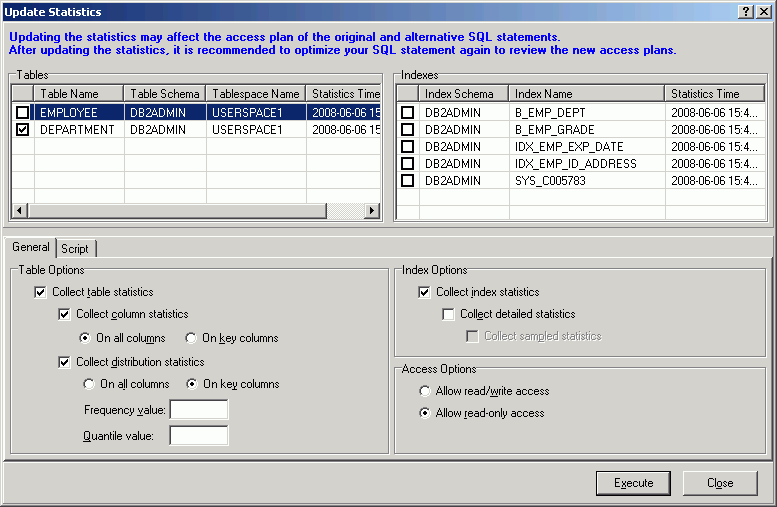
You can update the statistics for the tables and their indexes when you are viewing the Access Plan tab.
To update the statistics for a table
Right-click the table in the Table Statistics pane. and select Update Statistics.
In the Update Statistics window, select one or more tables to update.
In the Table Options section, select the specific options for updating the table statistics.
Note: This table only covers unfamiliar information. It does not include all field descriptions.
|
Frequency value |
Specify the maximum number of frequency values to collect for columns values distribution.
If you do not specify a value, the num_freqvalues database configuration parameter is used. |
|
Quantile value |
Specify the maximum number of quantile values to collect for columns values distribution.
If you do not specify a value, the num_quantiles database configuration parameter is used. |
Check the indexes to update for each table you have checked.
In the Index Options section, select the specific options for updating the index statistics.
Click the Script tab and review the RUNSTATS command.
Click Execute.
Note: In order to update statistics, you must have these privileges:
SYSADM
SYSCTRL
SYSMAINT
DBADM
CONTROL privilege on the table
LOAD authority
