How to restore Oracle archive logs
How to Restore Oracle Archive Logs
If you decide to restore the archive logs to enable SharePlex to resume capture and replication, use the following procedure to determine the required archive logs.
Perform the following steps to determine the required archive logs:
-
Determine the sequence number that Capture needs to resume processing from. Capture stops when it encounters a log wrap and prints a message to the Event Log (event_log) containing the redo log sequence number it needs. You also can find out this number by querying the SHAREPLEX_ACTID table and looking at the SEQNO column, as shown in the following example:
SQL> select * from splex.shareplex_actid;
| ACTID |
SEQNO |
OFFSET |
AB_FLAG |
QUE_SEQ_NO_1 |
QUE_SEQ_NO_2 |
COMMAND |
| ----- |
------ |
-------- |
-------- |
------------- |
-------------- |
------------ |
| 14 |
114 |
9757200 |
0 |
672101000 |
0 |
|
-
Query the Oracle V$LOG_HISTORY table to find out when that sequence number was archived, then copy the logs from that point forward to the source system.
SQL> select * from V$LOG_HISTORY;
| RECID |
STAMP |
THREAD# |
SEQUENCE# |
FIRST_CHANGE# |
FIRST_TIM NEXT_CHANGE# |
| ----- |
------ |
-------- |
-------- |
------------- |
-------------- |
| 111 |
402941650 |
1 |
111 |
2729501 |
14-JUL-00 2729548 |
| 112 |
402941737 |
1 |
112 |
2729548 |
14-JUL-00 2729633 |
| 113 |
402941930 |
1 |
113 |
2729633 |
14-JUL-00 2781791 |
| 114 |
402942019 |
1 |
114 |
2781791 |
14-JUL-00 2836155 |
| 115 |
402942106 |
1 |
115 |
2836155 |
14-JUL-00 2890539 |
How to release semaphores after process failure
If database corruption or other system problem forced you to shut down SharePlex, verify that SharePlex released the semaphores and shared memory that it was using.
To verify and release semaphores:
-
Look for any SharePlex processes that did not shut down, and kill them.
$ ps -ef | grep sp_
$ kill -9 PID
-
Change directories to the rim sub-directory of the SharePlex variable-data directory, then issue the od -x command for the shmaddr.loc and the shstinfo.ipc files.
# od -x shmaddr.loc
0000000 0000 00e1 ed40 0000 4400 9328 0080 0000
0000020 0002 0021
0000024
# od -x shstinfo.ipc
0000000 0000 00e0 ee90 0000 4100 9328 0010 0000
0000020 0002 0020
0000024
-
Make a note of the following values:
- The first 32-bit word of each of the files above reveals the hexadecimal equivalent of the ID of the shared memory segment. Convert this value to decimal. For example, in the shmaddr.loc file shown in step 2, the first word is 0000 00e1, which equates to a decimal value of 225. In the shstinfo.ipc file, the first word is 0000 00e0, which equates to a decimal value of 224.
- The third word of the shmaddr.loc and the shstinfo.ipc files reveals the hexadecimal equivalent of the KEY of the shared memory segment and the semaphore. (Each set has the same key value.) Do not convert this value to decimal. For example, in the shmaddr.loc file, the third word is 4400 9328. In the shstinfo.ipc file, the third word is 4100 9328.
- The fifth word of each file is the SEMAPHORE ID. Convert this value to decimal. The semaphore IDs in the examples are hex 0002 0021 and 0020 0020, which in decimal are 131105 and 131104, respectively.
-
Issue the ipcs -smaa command to view all of the shared memory segments and semaphores. (Shared memory segments are listed first and are denoted with an “m.” Semaphores are denoted with an “s.”) The display looks similar to the following, but will be more extensive.
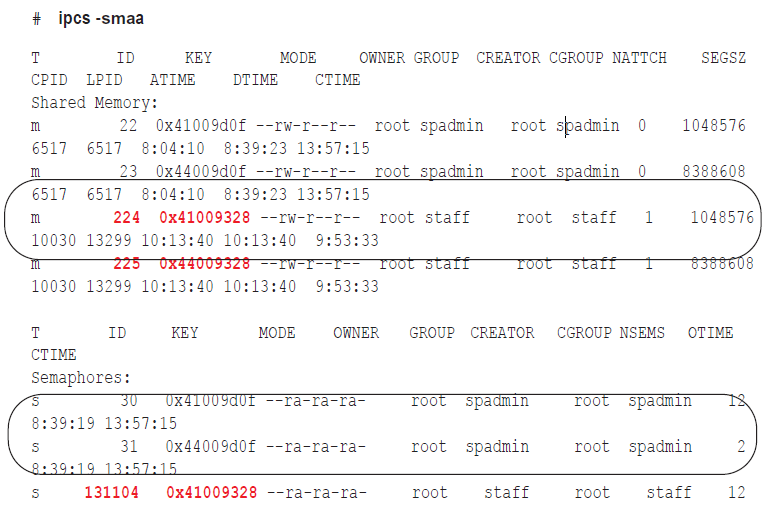
-
Verify that the shared memory IDs from the shmaddr.loc and shstinfo.ipc are in the list and that the keys match.
-
For each shared memory segment, verify that the value in the NATTCH column is 0. This ensures that the SharePlex processes that you killed released their memory segments.
-
For the semaphores, verify that the semaphore IDs and keys match the file values.
-
As root, issue the ipcrm -m command for the ID values (224 and 225 in the examples) to remove the memory segments.
# ipcrm -m 224
# ipcrm -m 225
-
As root, issue the ipcrm -s command for the key values (131104 and 131105 in the examples) to remove the semaphores.
# ipcrm -s 131104
# ipcrm -s 131105
How to resolve disk space shortage
This topic helps you resolve disk space issues that can occur when something interferes with replication. See Solve Replication Problems for possible causes.
How to conserve disk space on the target
SharePlex captures and processes data much faster than it posts it with SQL statements on the target system, so the target is where most disk problems can occur, assuming the network is operational and data is being sent from the source. If you think the post queue may exceed its disk space, there may be enough free space on the source system to store the data temporarily until the Post queue clears out.
To conserve the disk space on the target:
- Stop the Import process.
- Let the data accumulate on the source system until Post processes enough messages to clear the post queue.
- Start Import.
- Continue to stop and start Import until the amount of data accumulating in the post queue levels out.
When you implement this method, monitor the replication services and disk usage on the source system. On Unix and Linux systems, you can use the sp_ps script to monitor processes and the sp_qstatmon monitoring script to monitor the queues.
How to restore disk space
If a queue disk runs out of disk space, you may see messages similar to this in the Event Log:
11/22/07 14:14 System call error: No space left on device bu_wt.write [sp_mport(que)/1937472]
11/22/07 14:14 System call error: No space left on device bu_rls.bu_wt [sp_mport(que)/1937472]
11/22/07 14:14 Error: que_BUFWRTERR: Error writing buffer to file que_writecommit(irvspxuz+P+o.a920a64z-o.a102a64z) [sp_mport(rim)/1937472] 11/22/07 14:14 Error: sp_mport: rim_writecommit failed 30 - exiting [sp_mport/ 1937472]
11/22/07 14:14 Process exited sp_mport (from irvspxuz.domain.com queue irvspxuz) [pid = 1937472] - exit(1)
If a queue disk is almost out of free space, you might be able to add disk space without the need to resynchronize the data.
To restore disk space:
- Stop SharePlex on the affected system.
- Add more disk space.
- Start SharePlex.
-
View the Event Log and look for the messages "queue recovery started" and "queue recovery complete."
- If both messages are there, SharePlex resumes processing where it stopped and the recovery succeeded. If your applications generate high volumes of transactions, there may be numerous backlogged messages in the queues. Depending on the nature of the transactions, how well the target database and the Post process are tuned, and your tolerance for latency, it might be more practical to resynchronize the data instead of waiting for replication to regain parity with transactional activity.
- If one or more queues is corrupted, the Event Log records a message like this: Bad header magic... or peekahead failure. Or, you will see the message queue recovery started, but you will not see the queue recovery complete message that signifies successful queue recovery. In this case, you must restore replication an initial state.
To restore replication to an initial state:
- Run db_cleansp to restore the variable-data directory and SharePlex tables. It must be run on all systems in the affected replicationconfiguration. See the utilities documentation in theSharePlex Reference Guide.
- Synchronize the data using your method of choice, then reactivate the configuration. For more information, see Start Replication on your Production Systems.
- You can prevent this problem from occurring again by using the SharePlex monitoring utilities to start unattended monitoring of key replication events, including queue volume alerts. For more information, see Monitor SharePlex.
How to find the ORACLE_SID and ORACLE_HOME
When setting up SharePlex to work with an Oracle database, you provide the ORACLE_SID and then SharePlex gets the ORACLE_HOME from the oratab file on Unix/Linux. Both values are stored in the SharePlex environment. SharePlex uses the Oracle libraries that are in the location specified with ORACLE_HOME.
To determine the ORACLE_SID and ORACLE_HOME being used by SharePlex:
Issue the orainfo command in sp_ctrl.
sp_ctrl (mysysl11:2101)> orainfo
Oracle instance #1:
Oracle SID ora12
Oracle HOME /oracle/products/12
Oracle Version 12
Oracle instance #2:
Oracle SID ora12
Oracle HOME /oracle/products/12
Oracle Version 12
To determine the default ORACLE_SID and ORACLE_HOME on UNIX and Linux:
On most Unix and Linux systems the oratab file is under /etc/oratab. On Oracle Solaris systems, it is under /var/opt/oracle, but sometimes there is an oratab file in the /etc directory as well.
The entry in the file looks like the following example:
qa12:/qa/oracle/ora12/app/oracle/product/12.0
In the example, qa12 is the ORACLE_SID and /qa/oracle/ora12/app/oracle/product/12.0 is the ORACLE_HOME.
