
With the introduction of failover slots in PostgreSQL 17, logical replication can now be effectively utilized in high-availability environments. This feature ensures that logical replication continues seamlessly even if the publisher node fails and its physical standby is promoted as the new publisher.
When a primary server fails, the failover slot on the standby can take over, ensuring that logical replication continues without data loss. By setting the following parameters, the SharePlex capture process should proceed seamlessly without manual intervention in the event of a failover, and the slot will be managed by the cluster setup. To configure HA failover with SharePlex, users need to set the SP_CAP_MAX_RETRY_COUNT_PG and SP_CAP_RETRY_INTERVAL_PG parameters.
The following steps are useful for enabling failover in high-availability (HA) environments, both in AWS RDS and on-premises deployments:
-
Define the logical slots property: failover = true`.
-
Add the streaming replication slot to the new parameter synchronized_standby_slots.`
-
Set up a PostgreSQL cluster manager, such as Patroni, repmgr, or CrunchyData, to manage and orchestrate the PostgreSQL cluster. (Applicable only for on-premises environment)
Note: The HA failover capability is also compatible with AWS RDS PostgreSQL Multi-AZ DB deployments.
Auto-restart the PostgreSQL Capture
This feature ensures that the PostgreSQL capture process continues seamlessly in the event of disconnections from the database, by retrying based on parameter values without manual intervention.
SP_CAP_MAX_RETRY_COUNT_PG
This parameter controls the maximum number of times the PostgreSQL Capture process will attempt an automatic restart when it encounters a disconnection with the PostgreSQL database. The same parameter value will be used to retry the database recovery check during the CAPTURE automatic restart.
Default: 0
Range of valid values: any positive integer between 0 to 65535
Takes effect: Immediately
SP_CAP_RETRY_INTERVAL_PG
This parameter controls how often CAPTURE attempts an auto-restart.
NOTE: Set the retry count and interval values based on how long the PostgreSQL instance takes to become ready for use.
Default: 2
Range of valid values: any positive integer between 0 to 65535
Takes effect: Immediately
Capture and Event Log Example for Capture Auto-Restart
On the SharePlex source, when the SP_CAP_MAX_RETRY_COUNT_PG parameter is set to 20 and the SP_CAP_RETRY_INTERVAL_PG parameter is set to 5, users can observe the following log entries in the Capture and Event logs indicating the auto-restart of Capture.
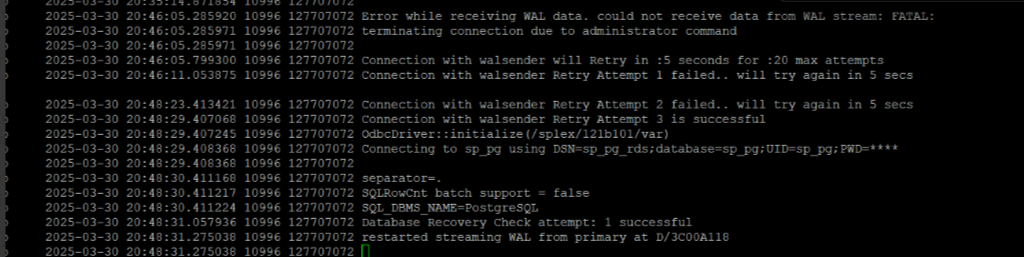
Note: The values of the SP_CAP_MAX_RETRY_COUNT_PG and SP_CAP_RETRY_INTERVAL_PG parameters can be configured according to the specific needs of the customer's environment.