About source and target data
SharePlex replication uses the concepts of source and target.
- The source data is the primary data that is to be replicated. This data resides on the source system.
- The target data is a full or subset copy of the primary data. This data resides on the target system.
The object of replication is to keep the source and target data synchronized, or in-sync, which means that the state of the source data is reflected accurately by the target data, adjusting for any transformation that is performed and for any time lag in the replication stream.
The target data can take the form of any of the SharePlex-supported target types: tables in a database, messages in a messaging queue or topic, or XML or SQL records in a file that can be consumed by other software programs.
About SharePlex architecture
This topic explains the default configuration of SharePlex. You can customize the SharePlex configuration to add additional queues and processes for the purpose of isolating data streams or improving performance.
SharePlex Directories
SharePlex uses two main directories:
The product directory: This is the SharePlex installation directory, where the SharePlex programs and libraries are stored.
The variable-data directory: This is the SharePlex working directory, where the queue files, log files and other components that comprise the current replication environment are stored.
Note: These directories are often referred to as productdir and vardir, respectively.
Do not remove, rename or edit any files or directories installed by SharePlex. Some directories contain hidden files that are essential for replication. Some files appear empty but must exist under their original names because they are referenced by one or more SharePlex processes. Some items in the directories are for use only under the supervision of Quest Technical Support.
Programs meant for general use in a production environment are documented in the published SharePlex documentation. If you do not find documentation for a program in a SharePlex directory, do not attempt to run it. Contact Quest Technical Support first.
The directory structure and files within the two main SharePlex directories differs slightly between the UNIX and Windows platforms. Files and directories can vary from version to version of SharePlex, but the basic structure appears as follows.
SharePlex product directory
| BACKUP |
Uninstall information |
| bin |
SharePlex executable files |
| config |
Internally used content. |
| data |
Default parameter settings |
| doc |
Catalog of exception messages |
| install |
(Unix and Linux only) Scripts related to installation, licensing and upgrades |
| lib |
SharePlex shared libraries |
| log |
SharePlex log files |
| mks_oe |
Runtime installation files for third-party software used by SharePlex. |
| util |
SharePlex utilities |
| .app-modules |
(Unix and Linux only) Hidden internal directory that contains raw executables. Do not use the contents of this directory to launch processes. |
| .meta-inf |
(Unix and Linux only) Hidden internal directory that contains meta information used during the installation process. |
SharePlex variable-data directory
| config |
Configuration files for this installation of SharePlex. |
| data |
Status Database, configuration activation information, user-defined parameter settings, and other user-defined files that direct replication activities. |
| db |
Configuration internal database for each activation of a configuration file. |
| downgrd |
Information about SharePlex targets that are a lower version than the source. |
| dump |
Core files (if a process fails) |
| log |
SharePlex log files |
| rim |
Queue files (working data files) |
| save |
Information about active and inactive configurations. |
| state |
Information about the current state of SharePlex when a configuration is active, such as the object and sequence caches. |
| temp |
Used by the copy and append features and other SharePlex sync-related processes. |
| oos |
Stores the transactions that contain out-of-sync operations when the SP_OPO_SAVE_OOS_TRANSACTION parameter is enabled. |
The sp_cop process
The sp_cop program coordinates the SharePlex replication processes: (Capture, Read, Export, Import, Post) and the SharePlex queues, and it initiates all of the other background processes that perform specific tasks. It also maintains communication with other systems in the replication network. In general, most SharePlex users have little interaction with sp_cop other than to start and stop it. Once started, sp_cop runs in the background.
- Only a SharePlex Administrator (member of the SharePlex admin group) can start or stop sp_cop.
- sp_cop must be started on all source and target systems involved in replication.
- Start sp_cop as soon as (or before) applications access the data on the source system, so that all of the SharePlex processes are ready to start processing transactions. That way, Capture can keep pace with the changes that are made to the source data.
The sp_ctrl process
Use sp_ctrl to issue the commands that start, stop, configure, direct and monitor SharePlex activities. The sp_ctrl program interacts internally with the sp_cnc (command and control) process, which is the child process of sp_cop that executes the commands. Users do not interact with sp_cnc itself.
SharePlex replication processes
SharePlex replicates data through a series of replication processes that are started by the main SharePlex process, sp_cop.
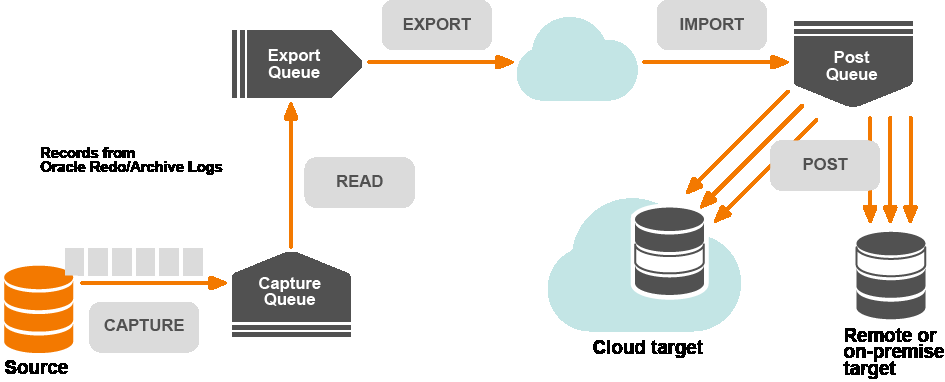
- The Capture process: The Capture process reads the transaction records on the source system for changes to objects that are configured for replication by SharePlex. The Capture process writes the data to the capture queue, where it accumulates until the Read process is ready for it. When data is being replicated from more than one datasource, there is a separate Capture process for each one, each functioning concurrently and independently. The Capture process is named sp_ocap (Oracle Capture).
- The Read process: The Read process operates on the source system to read data from the capture queue and add routing information to it. After processing the data, the Read process sends it to the Export queue. The Read process is named sp_ordr.
- The Export process: The Export process operates on the source system to read data from the export queue and send it across the network to a target system. By default, there is one Export process for each target system. For example, if there are two target systems, there are two Export processes. The Export process is the first part of the Export/Import transport pair, which moves data between systems over a TCP/IP network. The Export process is named sp_xport.
-
The Import process: The Import process is the second half of the Export/Import transport pair. The Import process operates on a target system to receive data and build a post queue. There is one Import process on a target system for each Export process that sends data to that target. For example, if there are two source systems (each with an Export process) replicating data to a single target system, there are two Import processes on that target. The Import process is named sp_mport.
Note: It is possible to replicate data between databases on the same system. In this case the Export and Import processes are not created. The Read process places data directly into a post queue on that system.
- The Post process: The Post process operates on a target system to read the post queue and apply the replicated operations to the target database, file, message queue or topic. There is a Post process for each post queue on a target system. Multiple Post processes can operate simultaneously on a system. The Post process is sp_opst_mt (Oracle Post) or sp_xpst (Open Target Post).
All communication and movement of data by SharePlex is handled by an internal messaging and transport system, using an asynchronous stream protocol with TCP/IP connections that is very efficient for large data transfers. This method ensures optimal performance, reliability and restart capabilities, while conserving communication bandwidth. SharePlex can replicate over any TCP/IP network.
SharePlex queues
Queues store the replicated data as it is transported from the source system to the target system. Queues are part of a checkpoint recovery system that facilitates safe, asynchronous transport of data. Data travels through the queues in the sequence in which it was generated.
Data is not read-released (deleted) from one queue until it is written to the next one. Data accumulates in the queues on the source and target systems if the network, system, or database slows down or fails, or when a replication process stops. When the problem or outage is resolved, SharePlex resumes processing from the point where it stopped.
SharePlex replication uses the following queues:
- Capture Queue: The capture queue resides on the source system and stores captured data for further processing by SharePlex. There is one capture queue for each datasource that is being replicated. A capture queue is identified by the datasource, for example o.fin1.
- Export Queue: The export queue resides on the source system. It holds data that has been processed by SharePlex and is ready for transport to the target system. By default, there is one export queue on a source system regardless of the number of active configurations or target systems. A default export queue is identified by the name of the source system on which it resides, for example, SysA. You can instruct SharePlex to create additional namedexport queues for more complex replication strategies.
- Post Queue: The post queue resides on the target system. It holds data that is ready for Post to write to the target database, file, or message queue or topic. On each target system, there is one post queue for the replication stream between a datasource and its target. For example, if DatabaseA and DatabaseB are both replicating to DatabaseC, there are two post queues. A default post queue is identified by the name of the source system plus the datasource and the target, for example SysA (o.DatabaseA-o.DatabaseB). You can instruct SharePlex to create additional named post queues for more complex replication strategies.
Note: All SharePlex queue files are created and maintained in the rim sub-directory of the SharePlex variable-data directory.
SharePlex Installed Objects
Much of the replication process is controlled and tracked through a series of internal objects that are installed into the source or target database during the installation of SharePlex. They are essential for SharePlex to operate, so do not alter them in any way.
NOTE: Not all objects are used for all databases. Most are used for Oracle databases. If you do not see an object in your database, it is not relevant to the database, or the information is stored internally within the SharePlex configuration. If you see an object that is in your database but not in this list, it is not being used in the current release.
| DEMO_SRC |
Table |
Used as the source table for the SharePlex demonstrations. |
| DEMO_DEST |
Table |
Used as the target table for the SharePlex demonstrations. |
| SHAREPLEX_ACTID |
Table |
Used by Capture to checkpoint its state. |
| SHAREPLEX_ANALYZE |
Table |
Used by the analyze command. |
| SHAREPLEX_CHANGE_OBJECT |
Table |
Used by users to stop and resume replication for an object. |
| SHAREPLEX_COMMAND |
Table |
Used for the flush, abort and purge commands. |
| SHAREPLEX_CONFIG |
Table |
Used by the activation and Capture processes to mark the start of a new activation. |
| SHAREPLEX_DATA |
Table |
Used by the SharePlex wallet for Oracle TDE replication. |
| SHAREPLEX_DATAEQUATOR |
Table |
Used by the compare and repair commands and the Post process to synchronize their operations. |
| SHAREPLEX_DATAEQUATOR_INSERT_TEMP |
Table |
Used as a temporary table by the compare and repair commands. |
| SHAREPLEX_DATAEQUATOR_UPDATE_TEMP |
Table |
Used as a temporary table by the compare and repair commands. |
| SHAREPLEX_DATAEQUATOR_DELETE_TEMP |
Table |
Used as a temporary table by the compare and repair commands. |
| SHAREPLEX_DDL_CONTROL |
Table |
Used to refine control of DDL that is enabled for replication by the SP_OCT_REPLICATE_ALL_DDL parameter. |
|
SHAREPLEX_JOBID |
Sequence |
Used by the sp_cnc process and the compare, repair, and copy commands to provide a unique job ID. |
| SHAREPLEX_JOBS |
Table |
Used by the sp_cnc process and the compare, repair, and copy commands to store information about a job. |
| SHAREPLEX_JOB_STATS |
Table |
Used by the sp_cnc process and the compare, repair, and copy commands to store information about a job. |
| SHAREPLEX_JOBS_CONFIG |
Table |
Used by the disable jobs and enable jobs commands. |
| SHAREPLEX_LOB_CACHE |
Table |
Used by the Capture process when processing VARRAYs stored as LOB. |
| SHAREPLEX_LOBMAP |
Table |
Used by the Capture process to map LOBIDs and rows when a table with LOB columns does not have PK/UK logging enabled. |
| SHAREPLEX_LOGLIST |
Table |
Used by the Capture process to track inactive RAC instances. |
| SHAREPLEX_MARKER |
Table |
Used by the Read process when PK/UK logging is not enabled. |
| SHAREPLEX_OBJMAP |
Table |
Used by the activation and Capture processes to define the objects in replication. |
| SHAREPLEX_PARTITION_CACHE |
Table |
Used by the Capture process to map Oracle partition IDs to tables in replication. |
| SHAREPLEX_SYNC_MARKER |
Table |
Used by the copy command and the Read and Post processes to sync their operations. |
|
SHAREPLEX_TRANS
or
SHAREPLEX_OPEN_TRANS |
Table |
Used by the Post process to store checkpoints and to mark transactions that were applied in a primary-to-primary configuration. |
How SharePlex replication works
To replicate data, SharePlex reads the stream of transaction data on the source system and captures changes that are made to objects that are specified in a configuration file. In the configuration file, you specify which data to replicate and the target to which it is applied.
You activate a configuration file to start replication. This is done by means of the activate config command in sp_ctrl within a sequence of steps that also includes synchronizing the source and target data for the first time. When a configuration is active, SharePlex replicates only the changes that are made to the objects specified in the configuration file, not entire data records, which provides a fast and reliable replication solution.
For more information see:
From the information that it has about a transaction operation, SharePlex creates one or more messages that are sent from the source system to the target system. A message can reflect a SQL operation or an internal SharePlex operation, but most of the time it is an INSERT, UPDATE, DELETE, COMMIT, TRUNCATE or a supported DDL operation.
Note: Large operations like those on LONG or LOB columns can require more than one message because a message has a size limitation. Other operations, such as array inserts of small records, have the inverse effect: There could be one record for numerous operations. For example, an array insert of 70,000 rows might be recorded in the transaction stream as only 700 messages, depending on the data. In general, unless you are replicating numerous changes to those kinds of data types, you can assume that the number of messages shown in the status output for a process or queue approximately corresponds to the same number of SQL operations.
The Post process reads messages from the post queue and applies the replicated data changes to the target. In the case of a database target, Post constructs SQL statements to apply the data. In the case of non-database targets, Post outputs data records in the format required by the target, for example a file or messaging queue or topic.
The following explains the default ways that SharePlex builds SQL statements on the target system.
- If the change is an INSERT, SharePlex uses all of the columns in the row to build an INSERT statement.
- If the change is a DELETE, SharePlex uses only the key to build a WHERE clause to locate the correct row. In the case of Oracle, if a table lacks a key, SharePlex simulates one by using the values of all of the columns, except LONG and LOB columns. You can specify columns to use as a key when you create the configuration file. In the case of SQL Server, all configured objects must have a primary key.
- If the change is an UPDATE, SharePlex uses the key plus the values of the changed columns to build a WHERE clause to locate the correct row. Before applying changes to the database, the Post process compares a pre-image of the values of the source columns to the existing values of the target columns. The pre-image (also known as the before image) is the value of each changed column before the UPDATE. If the pre-image and the existing target values match, confirming a synchronized state, Post applies the changes. If not, then Post logs the operation to an error file and SharePlex returns an “out-of-sync” error.
- If the change is an UPDATE or DELETE statement that affects multiple rows on the source machine, SharePlex issues multiple statements on the target to complete the task. For example, an UPDATE tableA set name = ‘Lisa’ where rownum < 101 statement actually sends 100 UPDATE statements to the target, even though only one statement was issued on the source.
Understanding the concept of synchronization
The concept of synchronization applies mainly to table-to-table replication, where Post performs integrity checks to make certain that only one row in the target matches the row change that is being replicated. It does not apply to file, messaging targets, and change-history targets, which contain a record of every operation replicated by Post, some of which may be identical over time. The Post process does not perform integrity checks on those targets.
Characteristics of synchronized tables
The basic characteristics of synchronized source and target tables are as follows (unless the transformation feature is used).
- If a row exists in the source database, it exists in the target.
- Corresponding columns in source and target tables have the same structure and data types.
- Data values in corresponding rows are identical, including the values of the key.
Ensuring data integrity is the responsibility of the Post process. Post applies a WHERE clause to compare the key values and the before values of the SQL operations that it processes. Post uses the following logic to validate synchronization between source and target tables:
-
Post applies a replicated INSERT but a row with the same key already exists in the target. Post applies the following logic:
- If all of the current values in the target row are the same as the INSERT values, Post considers the rows to be in-sync and discards the operation.
- If any of the values are different from those of the INSERT, Post considers this an out-of-sync condition.
Note: You can configure Post so that it does not consider non-key values when posting an INSERT. See the SP_OPO_SUPPRESSED_OOS parameter in the SharePlex Reference Guide.
-
Post applies a replicated UPDATE but either cannot find a row in the target with the same key value as the one in the UPDATE or Post finds the correct row but the row values do not match the before values in the UPDATE. Post applies the following logic:
- If the current values in the target row match the after values of the UPDATE, Post considers the rows to be in-sync and discards the operation.
- If the values in the target row do not match the before or after values of the UPDATE, Post considers this an out-of-sync condition.
Note: You can configure Post so that it returns an out-of-sync message if the current values in the target row match the after values of the UPDATE. See the SP_OPO_SUPPRESSED_OOS parameter in the SharePlex Reference Guide.
- A DELETE is performed on the source data, but Post cannot locate the target row by using the key. When Post constructs its DELETE statement, it includes only the key value in its WHERE clause. If the row does not exist in the target, Post discards the operation.
Hidden out-of-sync conditions
Post only verifies the integrity of the rows that are being changed by its current SQL operation. It does not verify whether other rows in that table, or in other tables, are out of synchronization in the target database. A hidden out-of-sync condition may not show up until much later, when a change to the affected row is eventually replicated by SharePlex or a discrepancy is detected in the course of using that data.
Example of a detectable out-of-sync condition
Someone logs into the target and updates the COLOR column in the target table from “blue” to “red” in Row1. Then, an application user on the source system makes the same change to the source table, and SharePlex replicates it to the target. In the WHERE clause used by Post, the pre-image for the target table is “blue,” but the current value in the target row is “red.” Post generates an out-of-sync error alerting you to the out-of-sync condition.
Example of a hidden out-of-sync condition
Someone logs into the target and updates the COLOR column in the target table from “blue” to “red” in Row2, but the change is not made to the source table and is not replicated. The two tables are now out-of-sync, but Post does not return an error message, because there is no replication performed on that row. No matter how many subsequent updates are made to other columns in the row (SIZE, WEIGHT), the hidden out-of-sync condition for the COLOR column persists (and users on the target have inaccurate information) until someone updates the COLOR column in the source table. When that change is replicated, only then does Post compare the pre-images and return an error message.
The majority of time, the cause of out-of-sync data is not anything done wrong by replication, but rather DML applied on the target, an incomplete backup restore, or some other hidden out-of-sync condition, which goes undetected until replication affects the row. Solving out-of-sync conditions can be time-consuming and disruptive to user activity. Once replication is started, it is recommended that you:
- Prevent write access to the target tables, so that DML and DDL cannot be applied to them.
- Use the compare command to compare source and target data regularly to verify synchronization and detect hidden out-of-sync conditions. You can use the repair command to repair any out-of-sync rows. For more information about these commands, see the SharePlex Reference Guide.
How SharePlex responds to an out-of-sync condition
You can decide how you want SharePlex to respond to transactions that generate an out-of-sync error:
-
The default Post behavior when a transaction contains an out-of-sync operation is to continue processing other valid operations in the transaction to minimize latency and keep targets as current as possible. Latency is the amount of time between when a source transaction occurs and when it is applied to the target. Different factors affect the amount of latency in replication, such as unusually high transaction volumes or interruptions to network traffic.
Post logs the SQL statement and data for the out-of-sync operation to the ID_errlog.sql log file, where ID is the database identifier. This file is in the log sub-directory of the variable-data directory on the target system.
-
You can configure Post to stop when it encounters an out-of-sync condition by setting the following parameter to 1:
- Oracle targets: SP_OPO_OUT_OF_SYNC_SUSPEND
- Open Target targets: SP_OPX_OUT_OF_SYNC_SUSPEND
-
You can configure Post to roll back and discard a transaction if any operation in that transaction generates an out-of-sync error. The entire transaction is logged to a SQL file, but not applied to the target.You can edit the SQL file to fix the invalid DML and then run the SQL file to apply the transaction. This feature is enabled by setting the SP_OPO_SAVE_OOS_TRANSACTION to 1.
