When performing a migration with Archive Shuttle a question which arises and needs to be addressed is whether to migrate leavers data if journal migration is being performed.
Journal archives contain messages from everyone inside the organization, and all inbound and outbound communications. It has messages from everyone in the company now, and everyone that left the company over the preceding years. The tricky part is determining when journal archiving was turned on. That can affect whether or not you need to migrate just the journal archive, or the journal archive and leavers data.
Below are a couple of examples.
Example 1
Lets say Bob works for the organization now, and has been working for the organization for 3 years. Jane doesnt work for the company any more, she joined about 18 months ago and left 3 months ago.
Journal archiving has been in place for 5 years.
In this example, the data which would be in Bobs archive will be in the journal archive. The data which would be in Janes leaver archive will also be in the journal archive. Therefore, the organization could make the decision that they do not need to migrate that leaver archive.
Example 2
Lets say Sarah has been working for the company for 6 months. Lets say David is a leaver, he left 3 months ago, and has been working for the company for 7 years.
Journal archiving has been in place for 5 years.
In this example the data in Sarahs archive will be in the journal archive, but not all of the data in Davids leaver archive will be in the journal archive. Therefore, the organization could make the decision that they do need to migrate Davids data as well as the journal archive.
This comparison would need to be done across all leaver archives before an overall decision could be reached, and ultimately its the organizations decision to migrate the data or not.
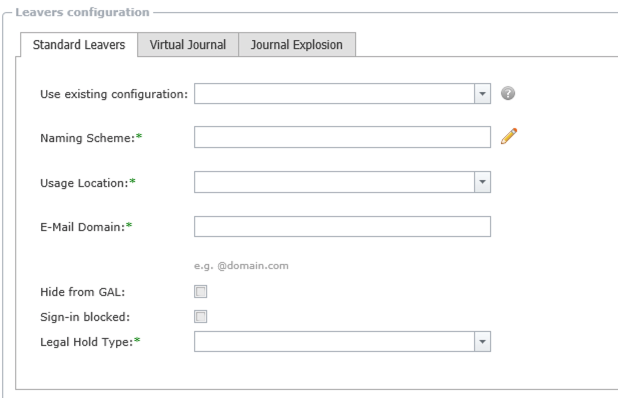
An important consideration when migrating leaver archives with Archive Shuttle is the naming convention (or naming standard) to use for the mailboxes which Archive Shuttle will create.
The above screenshot shows where the configuration / selection is made in Archive Shuttle.
There are many tokens that can be used to help form the name such as:
·Archive ID
·Archive Name
·Container Mapping iD, and more.
It's important to remember that there should not be any overlap or collision with existing names in the target.
In selecting archive name, problems will be encountered when someone exists and a leaver has the same name. For example, if there is already an active mailbox owned by John Smith, and Archive Shuttle tries to process a lever called John Smith.
Ultimately, the naming scheme should be unique. Often the name will have a prefix; they will all appear in the directory in the same sort of place (compared with postfixing a token). Here is an example:
AL-*archivename*
Considerations when using special characters for naming leavers
Archive Shuttle will replace special characters in leaver naming tokens (for example letters with diacritics), with an underscore (_) (for example Aimée to Aim_e), in cloud only mailboxes. For more information, visit "Invalid user name" when you try to create a user name that contains a special character in Microsoft 365 and Microsoft 365 email address contains an underscore character after directory synchronization.
There are many aspects of a migration that can be tuned with Archive Shuttle, some of these are manual tuning mechanisms, others can be automatic if required.
Scheduling module operation
Each Archive Shuttle module can be supplied with a specific schedule. For example, if extraction is allowed only during the evening, so as to lessen the load on the source environment, the export modules can be configured to have an evening-only schedule.
Configuring schedules should be done with careful consideration of the impact on the space requirements on the Staging Area. If exports are occurring all night long, but ingests are not scheduled, the staging area may fill up rapidly.
Tuning module parallelism
Each of the modules used in an Archive Shuttle migration operates on a number of containers in parallel and within that a number of items in parallel. The defaults for each module have been chosen following testing in many different environments. They can be adjusted to higher or lower values in the System Configuration. The changes made will take effect the next time the module checks in with the Archive Shuttle Core (approximately once per minute)
For reference:
Container level parallelism
For example, Office 365 Mailbox Parallelism. This is the number of containers that will be operated on simultaneously by the module
Item level parallelism
For example, EXC Import Item Parallelism. This is the number of items that will be operated on simultaneously per container.
When changing the parallelism, it is advised to make changes in small steps and then observe the impact that this has had on migration performance.
EV ingest specific tuning
An option in the System Configuration allows the EV Import Module to pause if Enterprise Vault is in a scheduled archiving window. Pausing the ingestion during this time lessens the load on the target environment.
In addition, backup mode is checked per target Vault Store every 5 minutes.
When ingesting data the EV Import module will only send data to a Vault Store that is not in backup mode.
Finally, the number of items that are not yet marked as indexed in the target environment is captured per Vault Store once per minute. This is displayed on the System Health page in the Archive Shuttle Admin Interface.
|
|
NOTE: A large index backlog might indicate that the target environment has a problem relating to indexing is indexing slowly. |
Native Format Import (NFI) specific tuning
An option in the System Configuration allows the Native Format Import module to rename (i.e., move) temporary PST files from the Staging Area to the PST Output Path during Stage 1. Normally, the finalization of PSTs is not performed until Stage 2 is running for a container mapping, but this can lead to increased pressure for storage requirements on the Staging Area.
Enabling the option in the System Configuration can mean that this pressure is reduced because completed PST files are moved out of the Staging Area and placed in their final location.
Office 365 specific tuning
Additional throughput can be achieved by the Office 365 module by setting up and configuring additional service accounts that have application impersonation rights within Office 365. These accounts can then be added to the credential editor, and the Office 365 module will use them for ingesting data in a round-robin fashion.
Item batching
The Exchange and Office 365 modules both utilize an intelligent batching mechanism which groups together items based on size, folder and whether the item has an attachment or not.
|
|
NOTE: This can be deactivated on a per-module basis, if required. |
Quest creates software solutions that make the benefits of new technology real in an increasingly complex IT landscape. From database and systems management, to Active Directory and Office 365 management, and cyber security resilience, Quest helps customers solve their next IT challenge now. Around the globe, more than 130,000 companies and 95% of the Fortune 500 count on Quest to deliver proactive management and monitoring for the next enterprise initiative, find the next solution for complex Microsoft challenges and stay ahead of the next threat. Quest Software. Where next meets now. For more information, visit www.quest.com.