
Searching for Events in Repository Viewer
To browse repositories, use the InTrust Repository Viewer application. This console provides tools for event viewing and on-the-spot audit data analysis. Repository Viewer lets you dispense with SSRS-based reporting if your intention is to examine audit data rather than submit formal reports or provide knowledge for regulations compliance.
The primary feature of Repository Viewer is event searching. Searching supports advanced filtering, grouping and sorting. For your searches to work fast, it is recommended that the repository be indexed. (For more information about indexing, see the Repository Indexing for Advanced Search Capabilities topic.)
You can do the following with the search results:
- Save search criteria as searches for future use
- Organize the results in a tree using multi-level grouping
- Apply view filters to further refine the scope of data
- Export the results to create an ad-hoc report
In addition, you can schedule a report to be built from an automatic search and have it delivered by email or saved in a network share.
Where to Run Repository Viewer
Repository Viewer does not have complex InTrust component dependencies. However, in the primary use scenario it connects to the repository through an InTrust server, and it matters a lot how far apart the three components are: Repository Viewer, the InTrust server and the repository.
Working with Repository Viewer and InTrust Server
If Repository Viewer opens a repository through an InTrust server, it lets the server manage repository connections.
When Repository Viewer starts working with a repository, it connects to the InTrust server, gets authorization for access to the repository contents, and then connects to the repository.
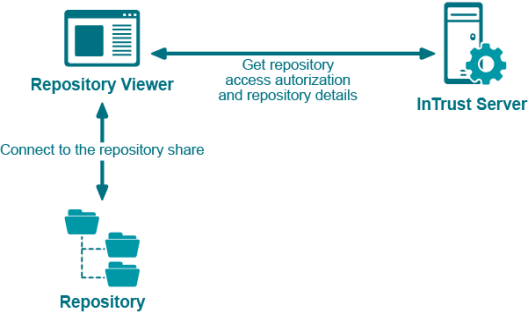
As Repository Viewer continues to work with the repository, it repeats the following steps:
- Ask the InTrust server for the exact locations of the requested data in the repository structure.
- After this negotiation, read the data directly from the repository, using the information from the server.
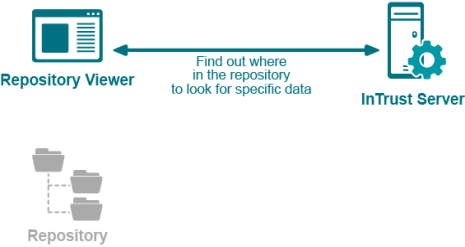
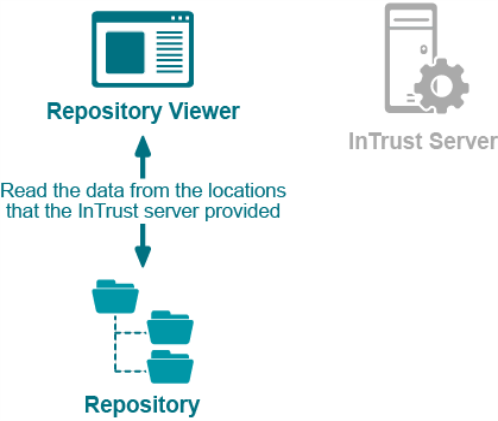
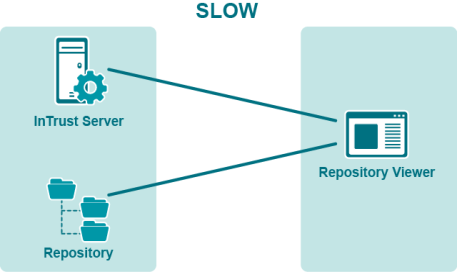
The actual reading of repository data is the most traffic-intensive part of the process. Therefore, you should try to run Repository Viewer as close as possible to the repository share, especially in geographically-dispersed networks. Ideally, they should be on the same computer, but if that is not possible, you should run Repository Viewer on a computer or virtual machine located in the part of the network that is nearest the repository share location. How close Repository Viewer is to the InTrust server is far less important, because the amount of data they exchange is insignificant.
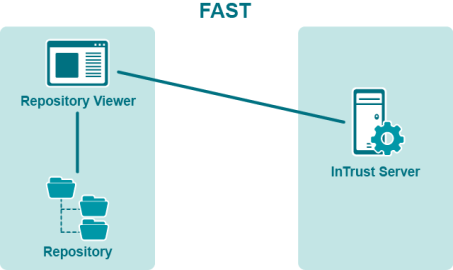
Working with Repository Viewer without an InTrust Server
You can use this option to analyze data from an idle repository; for example, a backup copy of a production repository with historical data.