이 지침에서는 통합 복제: 여러 소스 시스템에서 하나의 중앙 타겟 시스템으로의 복제를 위해 SharePlex를 설정하는 방법을 보여줍니다.
이 전략은 다음과 같은 비즈니스 요구 사항을 지원합니다.
- 실시간 보고 및 데이터 분석
- 중앙 데이터 저장소/마트 또는 웨어하우스에 빅데이터 축적
지원되는 소스
Oracle 및 PostgreSQL
지원되는 타겟
Oracle 및 Open Target
기능
이 복제 전략은 다음을 지원합니다.
- 동일하거나 다른 소스 및 타겟 이름
- 수직으로 파티셔닝된 복제 사용
- 수평으로 파티셔닝된 복제 사용
- 명명된 익스포트 및 Post 큐 사용
요구 사항
-
지침에 따라 시스템을 준비하고, SharePlex를 설치하고, 데이터베이스 계정을 구성합니다(참조: SharePlex 설치 안내서).
- SharePlex를 제외하고는 타겟 테이블에서 DML이나 DDL을 수행하면 안 됩니다. 복제 구성 외부에 있는 타겟 시스템의 테이블은 복제에 영향을 주지 않고 DML 및 DDL 작업을 수행할 수 있습니다.
-
각 소스 시스템은 서로 다른 데이터 세트를 중앙 타겟에 복제해야 합니다. 소스 시스템이 동일한 데이터를 중앙 타겟 시스템에 복제하는 경우 이는 활성-활성 복제로 간주됩니다. 자세한 내용은 피어-투-피어 복제 구성 를 참조하십시오.
- 타겟 시스템에 시퀀스가 불필요한 경우에는 복제하지 마십시오. 시퀀스를 복제하면 복제 속도가 느려질 수 있습니다. 소스 테이블에서 키를 생성하는 데 시퀀스가 사용되는 경우에도 복제된 행이 타겟 시스템에 삽입될 때의 시퀀스 값은 키 컬럼의 일부입니다. 시퀀스 자체는 복제할 필요가 없습니다.
배포 옵션
여러 소스 시스템에서 하나의 타겟 시스템으로 복제하기 위해 SharePlex를 배포하는 두 가지 옵션이 있습니다.
어느 배포에서든 소스 시스템이 타겟 시스템에 직접 연결할 수 없는 경우 해당 경로에 대한 단계화 복제를 사용해 SharePlex를 활성화하여 타겟에 대한 연결을 허용하는 중간 시스템에 데이터를 단계화할 수 있습니다. 자세한 내용은 중간 시스템을 통한 복제 설정를 참조하십시오.
참고: SharePlex compare와 repair 명령은 단계화 구성에서 사용할 수 없습니다.
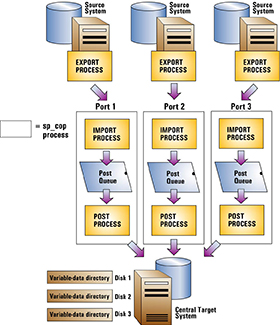
타겟 시스템에 하나의 SharePlex 인스턴스 사용하여 배포
하나의 SharePlex 인스턴스를 사용하여 타겟에서 들어오는 모든 데이터를 처리할 수 있습니다. 각 소스 시스템에 대해 SharePlex는 복제가 시작될 때 중앙 타겟 시스템에 Import 프로세스를 생성합니다. 그러면 각 소스-타겟 복제 스트림에 대한 Post 큐와 Post 프로세스가 생성되며 모두 하나의 sp_cop 프로세스로 제어됩니다. 각 소스-타겟 스트림을 개별적으로 제어할 수 있지만 Post 큐는 모두 타겟 시스템에서 동일한 SharePlex variable-data 디렉토리를 공유합니다.
단일 variable-data 디렉토리를 사용한 배포에는 다음과 같은 잠재적인 위험이 있습니다.
- variable-data 디렉토리가 포함된 디스크와의 처리를 중단하는 이벤트는 모든 복제 스트림에 영향을 미칩니다.
- 정리는 전체 variable-data 디렉토리에서 수행되기 때문에 사용하는 정리 유틸리티는 모든 복제 스트림에 영향을 미칩니다.
- 제거는 전체 variable-data 디렉토리에 영향을 미치기 때문에 한 소스 시스템에서 실행되는 purge config 명령은 다른 소스 시스템에서 복제된 데이터도 삭제합니다. 명명된 Post 큐를 사용하면 이러한 위험이 제거되지만 배포에서 SharePlex 객체의 이름 지정, 모니터링 및 관리가 복잡해집니다.
이 배포를 사용하려면 다음을 수행합니다.
- 각 시스템(소스 및 타겟)에 하나의 포트 번호와 하나의 variable-data 디렉토리를 사용하여 일반적인 방법으로 SharePlex를 설치합니다.
- SharePlex를 설치할 때 각 설치에 대해 SharePlex에 대한 데이터베이스 계정을 생성해야 합니다.
중요! 모든 시스템에서 SharePlex에 동일한 포트 번호를 사용합니다.
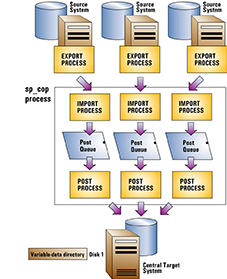
타겟 시스템에 여러 개의 SharePlex 인스턴스를 사용하여 배포
각 소스 시스템마다 하나씩, 타겟에 여러 개의 SharePlex 인스턴스를 배포할 수 있습니다. SharePlex 인스턴스는 다음 요소로 구성됩니다.
- 고유한 sp_cop 프로세스
- 고유한 variable-data 디렉토리
- sp_cop가 실행되는 고유한 포트 번호
- 해당 인스턴스의 프로세스가 데이터베이스와 상호작용하는 데 사용하는 고유한 데이터베이스 계정입니다.
SharePlex의 여러 개별 인스턴스를 실행하면 각 소스-타겟 복제 스트림을 다른 스트림에서 격리할 수 있습니다. 이를 통해 다음을 수행할 수 있습니다.
이 배포를 사용하려면 다음을 수행합니다.
가능한 경우 타겟 시스템에 먼저 설치합니다. 이를 통해 각 variable-data 디렉토리에 대한 포트 번호를 설정할 수 있으며, 해당 소스 시스템에서 SharePlex를 설정할 때 참조할 수 있습니다.
타겟 시스템의 단계
SharePlex의 여러 인스턴스 실행에 제시된 설정 옵션 중 하나를 선택합니다. 이러한 프로시저는 타겟에서 SharePlex의 독립적인 인스턴스를 설정하는 단계를 안내합니다. 타겟에 SharePlex를 이미 설치한 경우 variable-data 디렉토리, 데이터베이스 계정 및 포트 번호가 이미 있습니다. 해당 SharePlex 인스턴스를 소스 시스템 중 하나에 전용으로 지정한 다음, 해당 지침에 따라 타겟에 추가 인스턴스를 생성할 수 있습니다.
소스 시스템의 단계
지시에 따라 각 소스 시스템에 SharePlex 인스턴스를 하나씩 설치합니다(참조: SharePlex설치 안내서). 해당 인스턴스의 포트 번호를 연결된 타겟 variable-data 디렉토리의 포트 번호와 일치시킵니다. 소스 시스템에 SharePlex를 이미 설치한 경우 필요에 따라 포트 번호를 변경할 수 있습니다. 자세한 내용은 SharePlex 포트 번호 설정를 참조하십시오.
구성
해당 시스템에서 중앙 타겟으로 객체를 복제하는 각 소스 시스템에 구성 파일을 생성합니다. 구성 파일을 생성하는 방법에 대한 자세한 내용은 데이터 복제를 위해 SharePlex 구성를 참조하십시오.
|
datasource_specification |
|
|
| source_specification |
target_specification |
central_host[@db] |
여기서,
- source_specation은 소스 객체(owner.object)의 정규화된 이름이거나 와일드카드 사양입니다.
- target_specification은 타겟 객체(owner.object)의 정규화된 이름이거나 와일드카드 사양입니다.
- central_host는 타겟 시스템입니다.
- db는 데이터베이스 사양입니다. 데이터베이스 사양은 연결 유형에 따라 Oracle SID, TNS 별칭 또는 데이터베이스 이름 앞에 o. 또는 r.이 추가되는 것으로 구성됩니다. 타겟이 JMS, Kafka 또는 파일인 경우 데이터베이스 식별자가 필요하지 않습니다.
예
이 예에서는 hostA의 데이터 소스 oraA 및 hostB의 데이터 소스 oraB 데이터가 시스템 hostC의 oraC로 복제되는 것을 보여줍니다.
hostA의 데이터
| Datasource:o.oraA |
|
|
| hr.* |
hr.* |
hostC@o.oraC |
| fin.* |
fin* |
hostC@o.oraC |
hostB의 데이터
| Datasource:o.oraB |
|
|
| cust.* |
hr.* |
hostC@o.oraC |
|
mfg.* |
mfg.* |
hostC@o.oraC |
권장되는 타겟 구성
통합 구성의 각 소스 시스템은 타겟의 자체 Post 프로세스로 흐르는 개별 데이터 스트림을 보냅니다. 선택한 고유 식별자를 각 소스 시스템에 할당한 다음, 타겟에 게시하는 각 삽입 또는 업데이트에 해당 식별자를 포함하도록 Post 프로세스를 구성할 수 있습니다.
이 방식으로 행을 식별함으로써 사용자 환경은 SharePlex compare 및 repair 명령(소스 ID 필요)은 물론 해당 소스에 따라 행 선택 또는 식별이 필요할 수 있는 기타 작업을 지원할 준비가 됩니다. compare와 repair 프로세스는 소스 ID 값을 사용하여 해당 소스에 유효한 행만 선택합니다.
소스 ID를 쓰도록 각 Post를 구성하려면 다음을 수행합니다.
-
SHAREPLEX_SOURCE_ID라는 컬럼을 포함하도록 타겟 테이블을 생성하거나 변경합니다. 소스 ID 값이 포함될 컬럼입니다.
참고: 계속 진행하기 전에 target 명령을 메타데이터 설정 옵션과 함께 실행하여 이 이름을 변경할 수 있습니다. 자세한 내용은 SharePlex 참조 안내서를 참조하십시오.
- 각 소스 시스템에 대해 고유 ID를 선택합니다. 단일 영숫자 문자열이 허용됩니다.
- 타겟에서 각 Post 프로세스에 대해 sp_ctrl을 실행합니다.
-
각 Post 프로세스에 대해 target 명령을 소스 설정 옵션과 함께 실행합니다. 이 명령은 해당 Post 프로세스에 의해 게시될 소스 ID를 설정합니다. 다음 예에서는 세 가지 Post 프로세스에 대한 명령을 보여줍니다.
sp_ctrl> target sys4 queue Q1 set source east
sp_ctrl> target sys4 queue Q2 set source central
sp_ctrl> target sys4 queue Q3 set source west
피어-투-피어 복제 구성
이 지침에서는 여러 데이터베이스를 유지 관리할 목적으로 SharePlex를 설정하는 방법을 보여줍니다. 여기서 각 시스템의 애플리케이션은 동일한 데이터를 변경할 수 있고 SharePlex는 복제를 통해 모든 데이터를 동기화된 상태로 유지합니다. 이를 피어-투-피어 또는 활성-활성 복제라고 합니다. 이 전략에서 데이터베이스는 일반적으로 서로의 미러 이미지이며, 모든 객체는 모든 시스템에 전체적으로 존재합니다. 고가용성 전략과 이점은 비슷하지만 둘의 차이점은 피어-투-피어가 동일한 데이터에 대한 동시 변경을 허용하는 반면, 고가용성은 기본 데이터베이스가 오프라인 상태가 되는 경우에만 보조 데이터베이스에 대한 변경을 허용한다는 점입니다.
이 전략은 다음의 비즈니스 요구 사항을 지원합니다.
- 다양한 위치에서 여러 인스턴스를 운영하여 미션 크리티컬 데이터의 가용성을 유지합니다.
- 여러 접근 지점에 과도한 OLTP(Online Transaction Processing) 애플리케이션 로드를 분산합니다.
- 중요한 데이터베이스에 대한 직접 접근을 제한하면서 방화벽 외부의 사용자가 자신의 데이터 복사본을 업데이트할 수 있도록 합니다.
피어-투-피어 복제의 예로는 세 개의 동일한 데이터베이스를 보유한 전자상거래 회사가 있습니다. 사용자가 웹 브라우저에서 애플리케이션에 접근하면 웹 서버는 라운드 로빈 구성으로 해당 데이터베이스에 순차적으로 연결됩니다. 데이터베이스 중 하나를 사용할 수 없는 경우 서버는 사용 가능한 다른 데이터베이스 서버에 연결됩니다. 따라서 구성은 장애 조치 리소스 역할을 할 뿐만 아니라 모든 피어 간에 로드를 균일하게 분산하는 수단으로도 사용됩니다. 회사가 비즈니스 보고서를 작성해야 하는 경우 데이터베이스 중 하나에 대한 사용자 접근을 일시적으로 중지할 수 있으며 해당 데이터베이스를 사용하여 보고서를 실행할 수 있습니다.
참고: Capture는 Post 프로세스에 의해 로컬 시스템에서 수행된 트랜잭션을 무시하기 때문에 피어-투-피어 복제에서 변경된 데이터가 한 시스템에서 다른 시스템으로 루프백되는 것을 방지합니다.
피어-투-피어 복제가 모든 복제 환경에 적합한 것은 아닙니다. 패키징된 애플리케이션을 사용하는 경우에는 데이터베이스 설계에 대한 상당한 노력이 필요하며 이는 실용적이지 않을 수 있습니다. 또한 동시에 또는 거의 동시에 동일한 데이터에 여러 변경 사항이 있는 경우 특정 데이터베이스에 어떤 트랜잭션 SharePlex가 게시되는지 우선순위를 지정하는 충돌 해결 루틴을 개발해야 합니다.
지원되는 소스-타겟 조합
-
오라클 간 마이그레이션
-
Oracle-PostgreSQL
-
Oracle-PostgreSQL Database as a Service as source
-
PostgreSQL-PostgreSQL
-
PostgreSQL-Oracle
-
PostgreSQL-PostgreSQL Database as a Service
-
PostgreSQL Database as a Service as source-PostgreSQL
-
PostgreSQL Database as a Service as source-Oracle
-
PostgreSQL Database as a Service as source-PostgreSQL Database as a Service
기능
이 복제 전략은 다음을 지원합니다.
이 복제 전략은 다음을 지원하지 않습니다.
- LOB 복제. LOB가 있는 테이블이 복제에 포함된 경우 LOB는 충돌 해결을 통해 우회되므로 데이터가 동기화되지 않을 가능성이 있습니다.
- 컬럼 매핑 및 파티셔닝된 복제는 피어-투-피어 구성에 적합하지 않습니다.
요구 사항
- 피어-투-피어 복제와 관련된 모든 테이블에는 기본 키 또는 null 허용 컬럼이 없는 유니크 키가 있어야 합니다. 각 키는 복제에 포함될 모든 데이터베이스 중에서 동일한 owner.table.row를 고유하게 식별해야 하며 데이터베이스에서 키 컬럼의 로깅이 활성화되어야 합니다. 이 항목의 추가 요구 사항을 참조하십시오.
-
지침에 따라 시스템을 준비하고, SharePlex를 설치하고, 데이터베이스 계정을 구성합니다(참조: SharePlex 설치 안내서).
- 피어-투-피어 구성의 모든 데이터베이스에서 기본 키, 유니크 키 및 외래 키에 대한 보충 로깅을 활성화합니다.
- 모든 시스템에서 아카이브 로깅을 활성화합니다.
- 동기화의 개념을 이해해야 합니다. 자세한 내용은 동기화의 개념 이해를 참조하십시오.
-
활성화하기 전에 SP_OPX_CREATE_ORIGIN_PG를 1로 설정합니다. PostgreSQL-Oracle 복제의 경우 PostgreSQL 피어에 설정하고 PostgreSQL-PostgreSQL 복제의 경우 두 피어 모두에 설정합니다.
개요
피어-투-피어 복제에서는 일반적으로 다른 시스템에 있는 다른 데이터베이스의 동일한 테이블 복사본에 대해 DML 변경이 허용되는 반면 SharePlex는 복제를 통해 모든 내용을 최신 상태로 유지합니다. 동시에(또는 거의 동시에) 둘 이상의 데이터베이스에서 레코드가 변경되면 충돌이 발생할 수 있으며 불일치를 해결하려면 충돌 해결 논리를 적용해야 합니다.
피어-투-피어 복제에서 충돌이 발생하는 원인
SharePlex가 충돌을 확인하는 방법을 알아보려면 일반적인 상황과 충돌 상황에 대한 다음 예를 참조하십시오. 예에서는 세 가지 시스템(SysA, SysB, SysC)이 사용됩니다. 충돌이 무엇인지에 대한 자세한 내용은 충돌이란?을 참조하십시오.
이 예에서는 다음 테이블이 사용되었습니다.
Scott.employee_source
jane.employee_backup
다음의 컬럼 이름과 정의는 동일합니다.
| EmpNo |
number(4) not null, |
| SocSec |
number(11) not null, |
| EmpName |
char(30), |
| Job |
char(10), |
| Salary |
number(7,2), |
| Dept |
number(2) |
동기화된 상태인 두 테이블에 대한 값은 다음과 같습니다.
| 1 |
111-22-3333 |
Mary Smith |
관리자 |
50000 |
1 |
| 2 |
111-33-4444 |
John Doe |
데이터 입력 |
20000 |
2 |
| 3 |
000-11-2222 |
Mike Jones |
지원 |
30000 |
3 |
| 4 |
000-44-7777 |
Dave Brown |
관리자 |
45000 |
3 |
충돌이 없는 피어-투-피어 복제의 예
- 오전 9시에 SysA의 UserA는 Dept 컬럼의 값을 2로 변경합니다. 여기서 EmpNo는 1입니다. SharePlex는 해당 변경 사항을 SysB 및 SysC에 복제하고 두 데이터베이스는 모두 동기화된 상태를 유지합니다.
- 같은 날 오전 9시 30분에 SysB의 UserB는 Dept 값을 3으로 변경합니다. 여기서 EmpNo는 1입니다. SharePlex는 해당 변경 사항을 SysA 및 SysC에 복제하고 두 데이터베이스는 계속 동기화됩니다.
행은 다음과 같이 표시됩니다.
| EmpNo (key) |
SocSec |
EmpName |
Job |
Salary |
Dept |
| 1 |
111-22-3333 |
Mary Smith |
관리자 |
50000 |
3 |
UPDATE 충돌이 있는 피어-투-피어 복제의 예
- 오전 11시에 SysA의 UserA는 Dept 값을 1로 업데이트합니다. 여기서 EmpNo는 1입니다. 그날 오전 11시 2분에 네트워크에 오류가 발생합니다. 캡처된 변경 사항은 모든 시스템의 Export 큐에 있습니다.
- 그날 오전 11시 5분에 네트워크가 복원되기 전에 SysB의 UserB는 Dept 값을 2로 업데이트합니다. 여기서 EmpNo는 1입니다. 네트워크는 그날 오전 11시 10분에 복원됩니다. 복제 데이터 전송이 재개됩니다.
- SharePlex는 UserA의 변경 사항을 SysB의 데이터베이스에 게시하려고 할 때 Dept 컬럼의 값이 3(사전 이미지)일 것으로 예상하지만 UserB의 변경으로 인해 값은 2입니다. 사전 이미지가 일치하지 않기 때문에 SharePlex에 동기화 중단 오류가 발생합니다.
- SharePlex는 UserB의 변경 사항을 SysA에 게시하려고 할 때 해당 컬럼의 값이 3일 것으로 예상하지만 UserA의 변경으로 인해 값은 1입니다. SharePlex에서 동기화 중단 오류가 발생합니다.
- SharePlex가 UserA와 User B의 변경 사항을 SysC의 데이터베이스에 게시하려고 하면 사전 이미지가 일치하지 않기 때문에 두 문 모두 실패합니다. SharePlex에서 동기화 중단 오류가 발생합니다.
참고: 자세한 내용은 부록 A: 피어-투-피어 다이어그램를 참조하십시오.
배포
피어-투-피어 복제를 배포하려면 다음 작업을 수행합니다.
- 피어-투-피어 환경에 대한 데이터 적합성을 평가합니다. 권장되는 변경을 수행합니다. 자세한 내용은 데이터 평가를 참조하십시오.
- 각 시스템의 데이터가 피어-투-피어 환경의 다른 모든 시스템에 복제되도록 SharePlex를 구성합니다. 자세한 내용은 Oracle-Oracle 복제 구성를 참조하십시오.
- Post가 충돌을 처리하는 방법에 대한 규칙을 제공하는 충돌 해결 루틴을 개발합니다. 자세한 내용은 충돌 해결 루틴 설정를 참조하십시오.
- 충돌 해결 파일을 만듭니다. SharePlex는 충돌이 발생할 때 사용할 올바른 프로시저를 결정하기 위해 이 파일을 참조합니다. 자세한 내용은 피어-투-피어 복제 구성 를 참조하십시오.
데이터 평가
피어-투-피어 구성에서 SharePlex를 성공적으로 배포하려면 다음을 수행해야 합니다.
- 키 분리
- 키 변경 방지
- 제어 시퀀스 생성
- 제어 트리거 사용
- 단계화 삭제 제거
- 신뢰할 수 있는 호스트 지정
- 우선순위 정의
이러한 요구 사항은 애플리케이션과의 협력을 요구하므로 프로젝트의 아키텍처 단계에서 고려해야 합니다. 따라서 많은 패키지 애플리케이션이 해당 가이드라인에 따라 생성되지 않았기 때문에 피어-투-피어 배포에 적합하지 않습니다.
다음은 각 요구 사항에 대한 자세한 설명입니다.
키
피어 투 피어 복제에서 허용되는 유일한 키는 기본 키입니다. 테이블에 기본 키는 없지만 null이 아닌 유니크 키가 있는 경우 해당 키를 기본 키로 변환할 수 있습니다. LONG 컬럼은 키의 일부가 될 수 없습니다.
기본 키를 할당할 수 없고 모든 행이 고유하다는 것을 알고 있는 경우 모든 테이블에 고유 인덱스를 만들 수 있습니다.
기본 키는 피어-투-피어 복제 네트워크의 모든 데이터베이스 중에서 고유해야 합니다. 즉, 다음을 의미합니다.
- 모든 데이터베이스의 각 해당 테이블에서 동일한 컬럼을 사용해야 합니다.
- 해당 행의 키 컬럼은 값이 동일해야 합니다.
기본 키는 행에 대한 충분한 정보를 포함하도록 생성해야 해당 행의 고유성에 대해 의문이 생기지 않으며, 따라서 복제된 작업이 고유성을 위반하면 충돌이 발생합니다.
기본 키 값은 변경할 수 없습니다.
데이터베이스에서 기본 키와 유니크 키의 추가 로깅을 활성화해야 합니다.
기본 키로 시퀀스만 사용하는 것은 피어-투-피어 복제에 부족할 수 있습니다. 예를 들어 샘플 테이블이 시퀀스를 사용하여 EmpNo 키 컬럼에 대한 값을 생성한다고 가정해 보겠습니다. UserA가 SysA에서 다음 시퀀스 값을 가져오고 "Jane Wilson"에 대한 행을 삽입한다고 가정합니다. UserB는 SysB에서 다음 시퀀스 값을 가져오고 "Jane Wilson"에 대한 행도 삽입합니다. 각 시스템의 시퀀스 번호가 달라서 복제된 INSERT에 유니크 키 위반이 없더라도 현재 데이터베이스에 "Jane Wilson"에 대한 항목이 두 개 있고 각각 다른 키가 있으므로 데이터 무결성이 손상됩니다. 이후 UPDATE에 실패합니다. 해결 방법은 키에 다른 고유 컬럼을 포함시켜 고유성을 보장하고 해결 논리를 통해 해결할 수 있는 충돌을 보장하는 데 충분한 정보를 확보하는 것입니다.
시퀀스
SharePlex는 시퀀스의 피어-투-피어 복제를 지원하지 않습니다. 애플리케이션이 시퀀스를 사용하여 키 전체 또는 일부를 생성하는 경우 피어-투-피어 구성의 다른 시스템에서 동일한 범위의 값이 생성될 가능성이 없어야 합니다. 시퀀스 서버를 사용하거나 각 서버에서 별도로 시퀀스를 유지 관리하고 각 서버에 고유한 범위를 파티셔닝할 수 있습니다. Quest는 n+1 시퀀스 생성 사용을 권장합니다(여기서 n = 복제 중인 시스템 수). 애플리케이션 유형에 따라 위치 식별자(예: 시스템 이름)를 기본 키의 시퀀스 값에 추가하여 고유성을 강화할 수 있습니다.
트리거
소스 시스템에서 실행된 트리거로 인한 DML 변경 사항은 리두 로그에 입력되고 SharePlex에 의해 타겟 시스템에 복제됩니다. 동일한 트리거가 타겟 시스템에서 실행되면 동기화 중단 오류가 반환됩니다.
피어-투-피어 구성에서 트리거를 처리하려면 다음 중 하나를 수행할 수 있습니다.
- 트리거를 비활성화합니다.
- 활성화된 상태로 유지하되 피어-투-피어 구성의 모든 인스턴스에서 SharePlex 사용자를 무시하도록 변경합니다. SharePlex는 이러한 목적으로 sp_add_trigger.sql 스크립트를 제공합니다. 이 스크립트는 Post 프로세스를 무시하도록 지시하는 WHEN 절을 트리거의 프로시저 문에 넣습니다. 자세한 내용은 복제를 위한 Oracle 데이터베이스 객체 설정를 참조하십시오.
ON DELETE CASCADE 제약 조건
ON DELETE CASCADE 제약 조건은 피어-투-피어 복제 구성의 모든 인스턴스에서 활성화된 상태로 남아 있을 수 있지만 Post가 이러한 제약 조건을 무시하도록 지시하려면 다음과 같은 매개변수를 설정해야 합니다.
- SP_OPO_DEPENDENCY_CHECK 매개변수를 2로 설정
- SP_OCT_REDUCED_KEY 매개변수를 0으로 설정
- SP_OPO_REDUCED_KEY 매개변수를 0으로 설정(다른 복제 시나리오에서는 이 매개변수를 다른 수준으로 설정할 수 있지만 피어-투-피어 구성에서는 0으로 설정해야 함)
UPDATE를 사용하여 유지되는 잔액 값
UPDATE 문을 사용하여 재고 또는 계정 잔액 등 수량 변경을 기록하는 애플리케이션은 피어-투-피어 복제에 대한 문제가 발생할 수 있습니다. 다음 온라인 서점의 예에서 그 이유를 설명합니다.
서점의 재고 테이블에는 다음 컬럼이 포함되어 있습니다.
Book_ID(기본 키)
수량
다음과 같은 일련의 이벤트가 발생한다고 가정합니다.
- 고객이 한 서버에 있는 데이터베이스를 통해 도서를 구매합니다. 도서 재고 수량이 100권에서 99권으로 줄어듭니다. SharePlex는 해당 UPDATE 문을 다른 서버에 복제합니다. (업데이트 재고 세트 수량 = 99, book_ID = 51295).
- 원본 UPDATE가 도착하기 전에 다른 고객이 다른 서버에서 동일한 도서를 두 권 구매하고(UPDATE 재고 세트 수량 = 98, book_ID = 51295), 해당 서버의 수량은 100권에서 98권으로 줄어듭니다.
- Post 프로세스가 첫 번째 트랜잭션을 게시하려고 할 때 첫 번째 시스템의 사전 이미지(도서 100권)가 두 번째 시스템의 예상 값(두 번째 트랜잭션의 결과로 현재 98권)과 일치하지 않는 것으로 확인됩니다. Post가 동기화 중단 오류를 반환합니다.
충돌 해결 프로시저를 작성할 수 있지만 올바른 값은 어떻게 결정될까요? 두 트랜잭션 이후 두 데이터베이스의 올바른 값은 97권이어야 하지만 두 UPDATE 문 중 어느 것이 허용되더라도 결과는 올바르지 않습니다.
이러한 이유로 UPDATE를 사용하여 계정 또는 재고 잔액을 유지 관리하는 애플리케이션에는 피어-투-피어 복제가 권장되지 않습니다. 차변/대변 방법을 사용하여 잔액을 유지할 수 있는 경우 UPDATE 문 대신 INSERT 문(재고 값 "n"에 INSERT,...)을 사용할 수 있습니다. INSERT 문에는 UPDATE 문처럼 WHERE 절을 사용한 전후 비교가 필요하지 않습니다.
애플리케이션이 UPDATE 문을 사용해야 하는 경우 충돌 해결 프로시저를 작성하여 서로 다른 시스템의 서로 다른 UPDATE 문으로 인해 발생하는 절대(또는 순)변경을 확인할 수 있습니다. 예를 들어 앞의 온라인 서점 예의 경우 첫 번째 고객의 구매가 두 번째 시스템에 복제되면 다음과 같은 충돌 해결 프로시저가 실행됩니다.
if existing_row.quantity <> old.quantity then old.quantity - new.quantity = quantity_change; update existing_row set quantity = existing_row.quantity - quantity_change;
충돌 해결 논리는 타겟 데이터베이스에 있는 기존 행의 수량 값(98)이 이전 값(사전 이미지 100)과 같지 않으면 순변경(1)을 얻기 위해 사전 이미지에서 새 값(복제된 값 99)을 빼도록 SharePlex에 지시합니다. 그런 다음, Quantity 컬럼을 98-1(97과 동일)로 설정하는 UPDATE 문을 실행합니다.
두 번째 사용자의 변경 사항이 첫 번째 시스템에 복제되면 동일한 충돌 해결 프로시저가 시작됩니다. 이 경우 순변경(사전 이미지 100에서 새 값 98을 뺀 값)은 2입니다. 이 시스템에서 UPDATE 문의 결과도 값 97입니다. 이는 99(첫 번째 고객 구매 후 기존 행 값)에서 순변경 2를 뺀 값입니다. 이 프로시저 논리의 결과에 따라 각 시스템의 Quantity 컬럼이 97권으로 업데이트되어 도서 3권을 판매한 순효과가 발생합니다
다음 예에서는 재무 기록 내의 계정 잔액을 사용하여 이 개념을 보여줍니다.
account_number(기본 키)
잔액
- 예시 테이블의 행(계정)에 SysA 잔고가 $1,500라고 가정합니다. CustomerA는 해당 시스템이 $500를 예치합니다. 애플리케이션은 UPDATE 문을 사용하여 잔액을 $2,000로 변경합니다. 변경 사항은 UPDATE 문(예: UPDATE...SET, 잔액=$2,000, 여기서 account_number=51,295)으로 SysB에 복제됩니다.
- 변경 사항이 적용되기 전에 CustomerA의 상대는 SysB에서 $250를 인출하고 애플리케이션은 해당 시스템의 데이터베이스를 $1,250로 업데이트합니다. CustomerA의 트랜잭션이 SysA에서 도착하고 Post가 이를 SysB에 게시하려고 하면 소스 시스템의 사전 이미지가 $1,500이지만 타겟의 사전 이미지는 상대의 트랜잭션으로 인해 $1,250이므로 일치하지 않아 충돌이 발생합니다.
계정의 절대(또는 순)변경을 계산한 후 해당 값을 사용하여 충돌을 해결함으로써 이러한 종류의 트랜잭션을 수용하는 충돌 해결 루틴을 작성할 수 있습니다. 예를 들면 다음과 같습니다.
if existing_row.balance <> old.balance then old.balance - new.balance = balance_change; update existing_row set balance = existing_row.balance - balance_change;
이 프로시저의 결과는 계정 잔액을 $1,750로 업데이트하는 것이며, 이는 $500를 입금하고 $250를 인출하는 순효과입니다. SysB에서 루틴은 SharePlex에 이전 잔액 1,500에서 새(복제된) 잔액 2,000을 빼서 -500의 순변경을 수행하도록 지시합니다. UPDATE 문은 잔액 값을 올바른 값인 1,250 - (-500) = 1,750으로 설정합니다.
SysA에서는 복제된 값 1,250을 기존 잔액 1,500에서 빼서 순변경액인 250을 얻습니다. UPDATE 문은 기존 잔액 2,000에서 해당 값을 빼서 올바른 값인 1,750을 얻습니다.
우선순위
SharePlex가 변경할 올바른 행을 검색할 때 충돌을 피하거나 해결하기 위한 환경이 구축되면 남은 충돌 가능성은 팩트 데이터에 있습니다. 이는 두 개 이상의 시스템에서 동일한 행의 동일한 컬럼에 대한 값이 다른 경우 이를 허용하도록 변경됩니다. 이를 위해 애플리케이션은 테이블에 대한 로컬 시스템의 이름인 소스를 사용하여 타임스탬프 및 소스 컬럼의 추가를 허용할 수 있어야 합니다.
다음은 우선순위를 설정하기 위해 충돌 해결 루틴을 수행할 때 이러한 컬럼이 어떻게 중요한 역할을 하는지 설명합니다.
신뢰할 수 있는 소스
다음의 두 가지 이유로 특정 데이터베이스나 서버를 널리 사용되는 소스나 신뢰할 수 있는 소스로 할당해야 합니다.
- 충돌 해결 루틴은 시스템이 많을수록 상당히 크고 복잡해질 가능성이 있습니다. 어느 시점에서는 재동기화가 필요한 오류가 발생할 가능성이 큽니다.resynchronization 구성의 시스템 중 하나는 필요한 경우 다른 모든 시스템이 재동기화되는 실제 소스로 간주되어야 합니다.
- 신뢰할 수 있는 소스 시스템의 작업이 다른 시스템의 충돌 작업보다 우선순위를 갖도록 충돌 해결 루틴을 작성할 수 있습니다. 예를 들어 본사 서버의 변경 사항이 지사의 동일한 변경 사항보다 우선적으로 적용될 수 있습니다.
타임스탬프
테이블에 타임스탬프 컬럼을 포함하고 충돌 해결 루틴의 우선순위를 가장 이른 타임스탬프나 가장 늦은 타임스탬프에 할당하는 것이 좋습니다. 그러나 타임스탬프는 키의 일부가 아니어야 하며, 일부인 경우 충돌이 발생합니다. SharePlex는 키 값이 변경되면 행을 찾을 수 없으며 컬럼 중 하나가 타임스탬프이면 키 값이 변경됩니다.
타임스탬프 우선순위가 작동하려면 관련된 모든 서버가 날짜와 시간에 동의해야 합니다. 서로 다른 시간대에 있는 서버의 테이블은 GMT(Greenwich Mean Time)를 사용할 수 있습니다.
관련된 서버가 다른 시간대에 있는 상황을 처리하려면 루틴에서 사용할 테이블에 'TIMESTAMP WITH LOCAL TIME ZONE' 컬럼을 지정하면 되고, 피어-투-피어 복제에서 데이터베이스의 'DBTIMEZONE'이 동일해야 합니다.
SharePlex 충돌 해결을 위한 기본 날짜 형식은 MMDDYYYY HH24MISS입니다. 기본 날짜가 있는 테이블은 해당 형식을 사용해야 하며, 사용하지 않으면 충돌 해결 시 오류가 반환됩니다. 기본 날짜가 포함된 테이블을 생성하기 전에 다음과 같은 명령을 사용하여 SQL*Plus에서 날짜 형식을 변경합니다.
ALTER SESSION SET nls_date_format = 'MMDDYYYYHH24MISS'
Oracle-Oracle 복제 구성
피어-투-피어 구성의 시스템에 있는 구성 파일은 데이터 소스 사양 및 라우팅을 제외하고 동일합니다.
구문에 사용되는 규칙
이 항목의 구성 구문에서 자리 표시자는 환경에서 다음 항목을 나타냅니다. 이 문서에서는 세 가지 시스템을 가정하지만 개수는 그 이상이 있을 수 있습니다.
-
hostA는 첫 번째 시스템입니다.
- hostB는 두 번째 시스템입니다.
- hostC는 세 번째 시스템입니다.
- ownerA.object는 hostA에 있는 객체의 정규화된 이름이거나 와일드카드 사양입니다.
- ownerB.object는 hostB에 있는 객체의 정규화된 이름이거나 와일드카드 사양입니다.
- ownerC.object는 hostC에 있는 객체의 정규화된 이름이거나 와일드카드 사양입니다.
- oraA는 hostA의 Oracle 인스턴스입니다.
- oraB는 hostB의 Oracle 인스턴스입니다.
- oraC는 hostC의 Oracle 인스턴스입니다.
중요! 구성 파일의 구성 요소에 대한 자세한 내용은 데이터 복제를 위해 SharePlex 구성를 참조하십시오.
hostA의 구성
|
Datasource:o.oraA |
| ownerA.object |
ownerB.object |
hostB@o.oraB |
| ownerA.object |
ownerB.object |
hostB@o.oraB |
| ownerA.object |
ownerC.object |
hostC@o.oraC |
| ownerA.object |
ownerC.object |
hostC@o.oraC |
참고: 모든 소유자 이름과 테이블 이름이 모든 시스템에서 동일한 경우 이러한 각 구성 파일에 대해 복합 라우팅 맵을 사용할 수 있습니다.
예를 들어 hostA에서 복제를 위한 복합 라우팅은 다음과 같습니다.
| Datasource:o.oraA |
| owner.object |
owner.object |
hostB@o.oraB+hostC@o.oraC |
hostB의 구성
|
Datasource:o.oraB |
| ownerB.object |
ownerA.object |
hostA@o.oraA |
| ownerB.object |
ownerA.object |
hostA@o.oraA |
| ownerB.object |
ownerC.object |
hostC@o.oraC |
| ownerB.object |
ownerC.object |
hostC@o.oraC |
hostC의 구성
|
Datasource:o.oraC |
| ownerC.object |
ownerA.object |
hostA@o.oraA |
| ownerC.object |
ownerA.object |
hostA@o.oraA |
| ownerC.object |
ownerB.object |
hostB@o.oraB |
| ownerC.object |
ownerB.object |
hostB@o.oraB |
예
| Datasource:o.oraA |
| hr.emp |
hr.emp |
hostB@o.oraB |
| hr.sal |
hr.sal |
hostB@o.oraB |
| cust.% |
cust.% |
hostB@o.oraB |
충돌 해결 루틴 설정
Oracle-Oracle의 충돌 해결 루틴 설정에 대한 자세한 내용은 Oracle-Oracle에 대한 사용자 정의 충돌 해결 루틴을 참조하십시오.