SharePlexは、1つのPDBから以下へデータをレプリケートすることができます。
SharePlexは、通常のソースデータベースからターゲットOracle CDB内のPDBにデータをレプリケートすることができます。
1つの設定ファイルで、同じCDBまたは別のCDBにある任意の数のターゲットPDBにレプリケートできます。
PDBからキャプチャするには:
設定ファイルで、PDBのTNSエイリアスをデータソースとして指定します。例えば、TNSのエイリアスがpdb1の場合、データソースの指定は次のようになります。
Datasource: o.pdb1
PDBにレプリケートするには:
pdb2がターゲットである次の例のように、ルーティングマップにターゲットPDBのTNSエイリアスを指定します。
sys02@o.pdb2
例1: この例では2つの設定ファイルを示します。1つはpdb1から、もう1つはpdb2からレプリケートし、いずれもpdb3にデータをレプリケートします。
Datasource: o.pdb1 hr.emp hr2.emp2 sys02@o.pdb3
Datasource: o.pdb2 sales.cust sales2.cust2 sys02@o.pdb3
例2: この例では1つの設定ファイルを示します。pdb1からpdb2およびpdb3にレプリケートし、両方のターゲットが別のシステム上にあります。
この章では、名前付きキューの高度なSharePlex設定オプションの使用方法を説明します。これらのオプションによって、特定の処理とルーティングの要件を満たすためにデータを分割および並列化するための高いレベルの柔軟性が実現されます。先に進む前に、データをレプリケートするためのSharePlexの設定に関わる概念とプロセスを確実に理解してください。
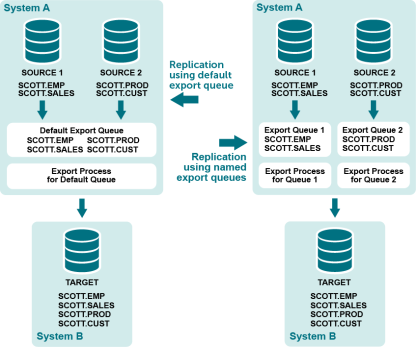
名前付きexportキューは、独自のExportプロセスに接続される、オプションのユーザ定義exportキューです。SharePlexはデフォルトのexportキューとプロセスのペアに加え、それぞれの名前付きexportキューと関連するExportプロセスを作成します。SharePlexは、名前付きexportキューとプロセスのペアを作成するときに、そのデータストリームを含めるために、ターゲット上に専用のImportプロセス、postキュー、Postプロセスも作成します。
設定ファイルを作成するときに、1つ以上の名前付きexportキューを作成するようにSharePlexに指示します。名前付きexportキューで処理するように設定されていないデータは、デフォルトのexportキューで処理されます。
PostgreSQLからPostgreSQL、Oracle、SQL Server、Kafkaへ
Oracleから全ターゲットへ
名前付きexportキューを使用して、以下のレプリケーションを分離します。
その他のメリット:
名前付きexportキューとデフォルトのexportキューを組み合わせることができます。標準的なルーティングマップ(名前付きキュー指定のないtargetsys@database_spec)を持つ設定内のテーブルは、デフォルトのexportキューを通してレプリケートされます。
名前付きexportキューを含むルーティングマップを定義するには、以下の構文を使用します。
source_host:export_queuename*target_host[@database]
| Datasource: o.SID | ||
| src_owner.table | tgt_owner.table |
source_host:export_queue*target_host[@database_specification] |
| ルーティングコンポーネント | 説明 |
|---|---|
| source_host | ソースシステムの名前。 |
| export_queue |
exportキューの名前。キュー名はすべてのプラットフォームで大文字と小文字が区別されます。複数の単語は使用できません。アンダースコアでつなげることはできます。以下に例を示します。 sys1:export_q1*sys2@o.myora |
| target_host | ターゲットシステムの名前。 |
| データベース指定 |
データソースの場合、以下のいずれか: o.oracle_SID r.database_name
対象がデータベースの場合は、以下のいずれか: o.oracle_SID o.tns_alias o.PDBname r.database_name c.oracle_SID |
注意:
|
次の設定ファイルは、同じターゲットシステム上の2つの異なるデータベースにレプリケートされる2つの異なるデータソースを示しています。各データソースは、名前付きexportキューを通してルーティングされます。
| Datasource:o.oraA | ||
| scott.emp | scott.emp | sysA:QueueA*sysB@o.oraC |
| scott.sales | scott.sales | sysA:QueueA*sysB@o.oraC |
| Datasource:o.oraB | ||
| scott.prod | scott.prod | sysA:QueueB*sysB@o.oraD |
| scott.cust | scott.cust | sysA:QueueB*sysB@o.oraD |
以下は、名前付きexportキューを使用して、LOBを含むテーブルを他のテーブルから分離する方法を示しています。
| Datasource:o.oraA | ||
| scott.cust | scott.cust | sysA:QueueA*sysB@o.oraC |
| scott.sales | scott.sales | sysA:QueueA*sysB@o.oraC |
| scott.prod | scott.prod | sysA:QueueA*sysB@o.oraC |
| scott.emp_LOB | scott.emp_LOB | sysA:QueueB*sysB@o.oraC |
あるいは、LOBテーブル用に名前付きexportキューを定義し、残りのテーブルはデフォルトのexportキューで処理するようにすることもできます。
| Datasource:o.oraA | ||
| scott.cust | scott.cust | sysB@o.oraC |
| scott.sales | scott.sales | sysB@o.oraC |
| scott.prod | scott.prod | sysB@o.oraC |
| scott.emp_LOB | scott.emp_LOB | sysA:lobQ*sysB@o.oraC |
名前付きexportキューを含むルーティングマップを定義するには、以下の構文を使用します。
source_host:export_queuename*target_host[@database]
PostgreSQL、Oracle、SQL Server、Kafka
| Datasource:r.dbname | ||
| src_schema.table | tgt_schema.table |
source_host:export_queue*target_host[@database_specification] |
| ルーティングコンポーネント | 説明 |
|---|---|
| source_host | ソースシステムの名前。 |
| export_queue |
exportキューの名前。キュー名はすべてのプラットフォームで大文字と小文字が区別されます。複数の単語は使用できません。アンダースコアでつなげることはできます。以下に例を示します。 sys1:export_q1*sys2@r.dbname |
| target_host | ターゲットシステムの名前。 |
| データベース指定 |
r.database_name |
注意: ルーティングマップの構文では、コンポーネント間にスペースを入れないでください。
次の設定ファイルは、同じターゲットシステム上の2つの異なるデータベースにレプリケートされる2つの異なるデータソースを示しています。各データソースは、名前付きexportキューを通してルーティングされます。
| Datasource:r.dbnameA | ||
| scott.emp | scott.emp | sysA:QueueA*sysB@r.dbnameC |
| scott.sales | scott.sales | sysA:QueueA*sysB@r.dbnameC |
| Datasource:r.dbnameB | ||
| scott.prod | scott.prod | sysA:QueueB*sysB@r.dbnameD |
| scott.cust | scott.cust | sysA:QueueB*sysB@r.dbnameD |
以下は、名前付きexportキューを使用して、LOBを含むテーブルを他のテーブルから分離する方法を示しています。
| Datasource:r.dbnameA | ||
| scott.cust | scott.cust | sysA:QueueA*sysB@r.dbnameC |
| scott.sales | scott.sales | sysA:QueueA*sysB@r.dbnameC |
| scott.prod | scott.prod | sysA:QueueA*sysB@r.dbnameC |
| scott.emp_LOB | scott.emp_LOB | sysA:QueueB*sysB@r.dbnameC |
あるいは、LOBテーブル用に名前付きexportキューを定義し、残りのテーブルはデフォルトのexportキューで処理するようにすることもできます。
| Datasource:r.dbnameA | ||
| scott.cust | scott.cust | sysB@r.dbnameC |
| scott.sales | scott.sales | sysB@r.dbnameC |
| scott.prod | scott.prod | sysB@r.dbnameC |
| scott.emp_LOB | scott.emp_LOB | sysA:lobQ*sysB@r.dbnameC |
名前付きexportキューは、sp_ctrlを使用して表示できます。
これらのコマンドの詳細については『SharePlexリファレンスガイド』を参照してください。
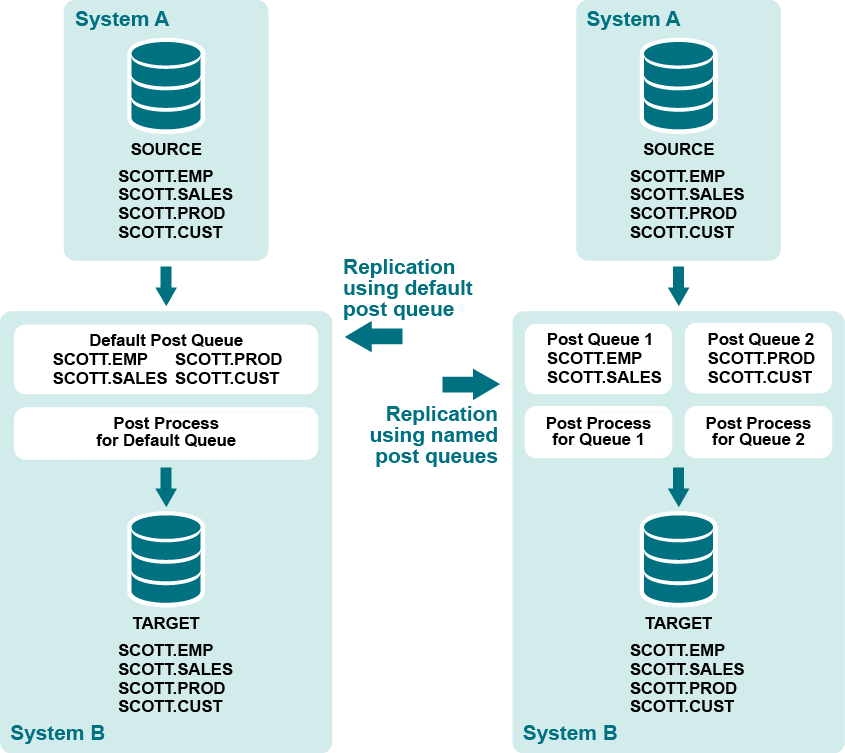
名前付きpostキューは、設定ファイル内のルーティングマップのオプションコンポーネントです。名前付きpostキューは、ユーザが定義したpostキューであり、独自のPostプロセスを持ち、デフォルトのpostキューとPostプロセスと並行して動作します。1つ以上の名前付きpostキューとプロセスのペアを定義して、一連の並列Postレプリケーションストリームを確立することができます。
PostgreSQLからPostgreSQL、Oracle、SQL Server、Kafkaへ
Oracleから全ターゲットへ
名前付きpostキューを使用して、異なるテーブルからのデータを2つ以上の個別のPostストリームに分離することができます。名前付きpostキューを使用することで、処理のボトルネックの原因となる以下のようなオブジェクトを分離し、ポストパフォーマンスを向上させることができます。
残りのオブジェクトは、追加の名前付きpostキューを通して処理するか、デフォルトのpostキューを使用します。標準的なルーティングマップ(host@target )を持つ設定ファイル内のオブジェクトは、デフォルトのpostキューを通じてレプリケートされます。
水平分割を使って、非常に大きなテーブルの行を別々の名前付きpostキューに分割することで、並列性を高めることができます。
SharePlexパラメータは、キューとプロセスのペアごとに異なる設定にできます。これにより、それぞれを通じてレプリケートされるオブジェクトに基づいて、Postプロセスのパフォーマンスを調整できます。
SharePlexには許可されるキューの最大数があります。詳細については、設定ファイル内のルーティング指定を参照してください。
名前付きexportキューを使用している場合、SharePlexはデフォルトで各キューに名前付きpostキューとプロセスのペアを作成します。名前付きexportキューを使用していない場合は、以下の構文を使用して、ルーティングマップに:queueコンポーネントを追加することで、設定ファイルに名前付きpostキューを定義します。
host:queue@target
| Datasource: o.SID | ||
| src_owner.table | tgt_owner.table |
host:queue[@database_specification] |
| ルーティングコンポーネント | 説明 |
|---|---|
| host | ターゲットシステムの名前。 |
| キュー |
postキューの一意の名前。キュー名はすべてのプラットフォームで大文字と小文字が区別されます。複数の単語は使用できません。アンダースコアでつなげることはできます。以下に例を示します。 sys2:post_q1@o.myora |
| database_specification |
データソースの場合、以下のいずれか: o.oracle_SID 対象がデータベースの場合は、以下のいずれか:
|
注意:
|
以下の設定では、テーブルscott.empからデータをルーティングするQueue1という名前のpostキューと、テーブルscott.custからデータをルーティングするQueue2という名前のpostキューを作成します。
| Datasource:o.oraA | ||
| scott.emp | scott.emp | sysB:Queue1@o.oraC |
| scott.cust | scott.cust |
sysB:Queue2@o.oraC |
以下は、中間システムを使用したパススルー構成でデータをルーティングする場合に、名前付きpostキューを指定する方法を示しています。詳細については、データを共有または配布するためのレプリケーションの設定を参照してください。
| Datasource:o.oraA | ||
| scott.emp | scott.emp | sysB*sysC:Queue1@o.oraC |
名前付きexportキューを使用している場合、SharePlexはデフォルトで各キューに名前付きpostキューとプロセスのペアを作成します。名前付きexportキューを使用していない場合は、以下の構文を使用して、ルーティングマップに:queueコンポーネントを追加することで、設定ファイルに名前付きpostキューを定義します。
host:queue@target
PostgreSQL、Oracle、SQL Server、Kafka
| Datasource:r.dbname | ||
| src_schema.table | tgt_schema.table |
host:queue[@database_specification] |
| ルーティングコンポーネント | 説明 |
|---|---|
| host | ターゲットシステムの名前。 |
| キュー |
postキューの一意の名前。キュー名はすべてのプラットフォームで大文字と小文字が区別されます。複数の単語は使用できません。アンダースコアでつなげることはできます。以下に例を示します。 sys2:post_q1@r.dbname |
| database_specification |
r.database_name |
注意: ルーティングマップの構文では、コンポーネント間にスペースを入れないでください。
以下の設定では、テーブルscott.empからデータをルーティングするQueue1という名前のpostキューと、テーブルscott.custからデータをルーティングするQueue2という名前のpostキューを作成します。
| Datasource:r.dbname | ||
| scott.emp | scott.emp | sysB:Queue1@r.dbname |
| scott.cust | scott.cust |
sysB:Queue2@r.dbname |
以下は、中間システムを使用したパススルー構成でデータをルーティングする場合に、名前付きpostキューを指定する方法を示しています。
| Datasource:r.dbname | ||
| scott.emp | scott.emp | sysB*sysC:Queue1@r.dbname |
名前付きpostキューは、データソース(データのレプリケーション元)と以下のいずれかによって識別されます。
名前付きpostキューは、sp_ctrlを使用して表示できます。
これらのコマンドの詳細については『SharePlexリファレンスガイド』を参照してください。
