この説明では、統合レプリケーション、つまり複数のソースシステムから1つの中央ターゲットシステムにレプリケートする目的で、SharePlexを設定する方法を示します。
この戦略は、以下のようなビジネス要件をサポートします。
OracleおよびPostgreSQL
Oracleおよびオープンターゲット
このレプリケーション戦略では以下をサポートします。
『SharePlexインストールガイド』の説明に従ってシステムを準備し、SharePlexをインストールして、データベースアカウントを設定します。
各ソースシステムは、中央のターゲットに異なるデータセットをレプリケートする必要があります。いずれかのソースシステムが同じデータを中央のターゲットシステムにレプリケートする場合、それはアクティブ/アクティブのレプリケーションとみなされます。詳細については、ピアツーピアレプリケーションの設定 を参照してください。
多数のソースシステムから1つのターゲットシステムにレプリケートするためにSharePlexを展開するには、2つのオプションがあります。
いずれの展開でも、ソースシステムがターゲットシステムに直接接続できない場合は、そのルートにカスケード レプリケーションを使用することで、SharePlexは、ターゲットに接続できる中間システムからデータをカスケードできます。詳細については、中間システムを介したレプリケーションの設定を参照してください。
注意: SharePlexのcompareコマンドおよびrepairコマンドは、カスケード設定では使用できません。
SharePlexの1つのインスタンスを使用して、ターゲット上のすべての受信データを処理できます。ソースシステムごとに、SharePlexはレプリケーションの開始時に中央ターゲットシステム上にImportプロセスを作成します。その結果、ソース/ターゲットのレプリケーションストリームごとにpostキューとPostプロセスが作成され、これらはすべて1つのsp_copプロセスによって制御されます。各ソース/ターゲットストリームを個別に制御することはできますが、postキューはすべて、ターゲットシステム上の同じSharePlex変数データディレクトリを共有します。
単一の変数データディレクトリを使用する展開には、以下の潜在的なリスクがあります。
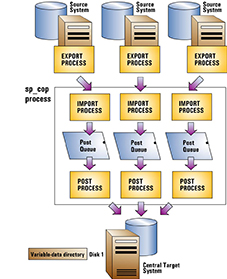
この展開を使用するには、次の手順を実行します。
重要! すべてのシステム上のSharePlexに同じポート番号を使用してください。
ターゲットにSharePlexの複数のインスタンスを展開できます(ソースシステムごとに1つ)。SharePlexインスタンスは以下の要素で構成されます。
複数の個別のSharePlexインスタンスを実行することで、各ソース/ターゲットのレプリケーションストリームを他から分離することができます。これにより、以下のことが可能になります。
1つのディスクの問題が他のディスクの変数データディレクトリに影響しないように、変数データディレクトリを別々のディスクに配置します。
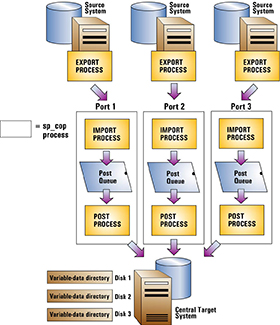
この展開を使用するには、次の手順を実行します。
可能であれば、最初にターゲットシステムにインストールします。これにより、各変数データディレクトリにポート番号を設定できるようになり、対応するソースシステムでSharePlexを設定するときに参照できます。
「SharePlexの複数のインスタンスの実行ページで紹介されている設定オプションのいずれかを選択します。これらの手順では、SharePlexの独立したインスタンスをターゲット上で確立するステップを説明します。ターゲットにSharePlexをインストール済みの場合は、変数データディレクトリ、データベースアカウントおよびポート番号が既に存在します。そのSharePlexインスタンスをソースシステムの1つの専用とし、これらの指示に従ってターゲット上に追加のインスタンスを作成できます。
『SharePlexインストールガイド』の指示に従って、各ソースシステムにSharePlexのインスタンスを1つずつインストールします。これらのインスタンスのポート番号を、関連するターゲット変数データディレクトリのポート番号に一致させます。ソースシステムに既にSharePlexがインストールされている場合は、必要に応じてポート番号を変更することができます。詳細については、SharePlexポート番号の設定を参照してください。
各ソースシステムに、そのシステムから中央ターゲットにオブジェクトをレプリケートする設定ファイルを作成します。設定ファイルの作成方法の詳細については、「データをレプリケートするためのSharePlexの設定ページを参照し て く だ さ い。
|
datasource_specification |
||
| source_specification | target_specification | central_host[@db] |
ここで
この例では、hostAのデータソースoraAとhostBのデータソースoraBからのデータが、 hostCのoraCにレプリケートされることを示しています。
| Datasource:o.oraA | ||
| hr.* | hr.* | hostC@o.oraC |
| fin.* | fin* | hostC@o.oraC |
| Datasource:o.oraA | ||
| cust.* | hr.* | hostC@o.oraC |
|
mfg.* |
mfg.* | hostC@o.oraC |
統合設定内の各ソースシステムは、ターゲット上の独自のPostプロセスに流れる個別のデータストリームを送信します。各ソースシステムに一意の識別子を割り当て、ターゲットにポストする各挿入または更新にその識別子を含めるようにPostプロセスを設定できます。
このように行を識別することで、(ソースIDを必要とする)SharePlexcompareコマンドやrepairコマンド、およびソースによる行の選択や識別を必要とするその他の作業をサポートする環境が整います。compareプロセスおよびrepairプロセスは、ソースID値を使用して、そのソースに有効な行のみを選択します。
ソースIDを書き込むように各Postを設定するには
SHAREPLEX_SOURCE_IDという列を含むように、ターゲットテーブルを作成または変更します。これはソースID値を格納する列です。
注意: 先に進む前に、set metadataオプションを指定してtargetコマンドを実行することで、この名前を変更することができます。詳細については、『SharePlexリファレンスガイド』を参照してください。
Postプロセスごとに、set sourceオプションを指定してtargetコマンドを発行します。このコマンドは、そのPostプロセスによってポストされるソースIDを設定します。以下の例は、3つのPostプロセスに対するコマンドを示しています。
sp_ctrl> target sys4 queue Q1 set source east
sp_ctrl> target sys4 queue Q2 set source central
sp_ctrl> target sys4 queue Q3 set source west
この説明では、複数のデータベースを管理する目的でSharePlexを設定する方法を示します。各システムのアプリケーションは同じデータに変更を加えることができ、SharePlexはレプリケーションを介してすべてのデータを同期させます。これはピアツーピア 、またはアクティブ/アクティブレプリケーションとして知られています。この戦略では、データベースは通常相互のミラーイメージであり、すべてのオブジェクトがすべてのシステム上にそのまま存在します。高可用性戦略と利点の面で類似していますが、両者の違いは、ピアツーピアでは同じデータへの同時変更が可能であるのに対し、高可用性ではプライマリデータベースがオフラインになった場合にのみセカンダリデータベースへの変更が可能である点です。
この戦略は、以下のビジネス要件をサポートします。
ピアツーピアレプリケーションの例として、3つの同一のデータベースを持つeコマース企業があります。ユーザがWebブラウザからアプリケーションにアクセスすると、Webサーバはラウンドロビン設定でこれらのデータベースのいずれかに順番に接続します。1つのデータベースが利用できない場合、サーバは利用可能な別のデータベースサーバに接続します。このように、この設定はフェールオーバーリソースとしてだけでなく、すべてのピアに負荷を均等に分散する手段としても機能します。企業にとってビジネスレポートを作成する必要が生じた場合は、データベースの1つへのユーザアクセスを一時的に停止し、そのデータベースを使用してレポートを作成できます。
注意: ピアツーピアレプリケーションで行われたデータ変更は、あるマシンから別のマシンにループバックすることはありません。これは、Captureが、Postプロセスによってローカルシステム上で実行されたトランザクションを無視するからです。
ピアツーピアレプリケーションは、すべてのレプリケーション環境に適しているわけではありません。データベース設計に大きなコミットメントが必要であるため、パッケージ化されたアプリケーションを使用する場合には、現実的ではないかもしれません。また、同じデータに対して複数の変更が同時またはほぼ同時に行われた場合、SharePlexが特定のデータベースにポストするトランザクションの優先順位を決定する競合解決ルーチンの開発も必要です。
Oracle から Oracle へ
OracleからPostgreSQLへ
OracleからPostgreSQL Database as a Service(ソースとして)へ
PostgreSQLからPostgreSQLへ
PostgreSQLからOracleへ
PostgreSQLからPostgreSQL Database as a Serviceへ
PostgreSQL Database as a Service(ソースとして)からPostgreSQLへ
PostgreSQL Database as a Service(ソースとして)からOracleへ
PostgreSQL Database as a Service(ソースとして)からPostgreSQL Database as a Serviceへ
このレプリケーション戦略では以下をサポートします。
このレプリケーション戦略では以下をサポートしていません。
システムを準備し、『SharePlexインストールガイド』の説明に従って、SharePlexをインストールし、データベースアカウントを設定します。
アクティベーションする前に、SP_OPX_CREATE_ORIGIN_PG を1に設定します。PostgreSQLからOracleへのレプリケーションではPostgreSQLピアに、PostgreSQLからPostgreSQLへのレプリケーションでは両方のピアに設定してください。
ピアツーピアレプリケーションでは、通常は異なるシステム上にある、異なるデータベースの同じテーブルのコピーに対するDMLの変更が可能であり、SharePlexがレプリケーションによってすべてのテーブルを最新の状態に保ちます。レコードが複数のデータベースで同時に(またはほぼ同時に)変更された場合、競合が発生する可能性があり、競合解決ロジックを適用して不一致を解決する必要があります。
SharePlexがどのように競合を判断するのかを理解するために、以下の通常の状況と競合状況の例を参照してください。この例では、3つのシステム(SysA、SysB、SysC)が使用されています。競合とは何かについての詳細は、「競合とは」を参照してください。
この例では以下のテーブルが使用されています。
Scott.employee_source
jane.employee_backup
列の名前と定義は以下のように同じです。
| EmpNo | number(4) not null, |
| SocSec | number(11) not null, |
| EmpName | char(30), |
| Job | char(10), |
| Salary | number(7,2), |
| Dept | number(2) |
同期状態の両テーブルの値は以下の通りです。
| EmpNo (key) | SocSec | EmpName | Job | Salary | Dept |
|---|---|---|---|---|---|
| 1 | 111-22-3333 | Mary Smith | Manager | 50000 | 1 |
| 2 | 111-33-4444 | John Doe | Data Entry | 20000 | 2 |
| 3 | 000-11-2222 | Mike Jones | Assistant | 30000 | 3 |
| 4 | 000-44-7777 | Dave Brown | Manager | 45000 | 3 |
行は以下のようになります。
| EmpNo (key) | SocSec | EmpName | Job | Salary | Dept |
| 1 | 111-22-3333 | Mary Smith | Manager | 50000 | 3 |
注意: 詳細については、付録A: ピアツーピア図を参照してください。
ピアツーピアレプリケーションを展開するには、以下のタスクを実行します。
ピアツーピア設定でSharePlexを正常に展開するには、次のことを行える必要があります。
これらの要件は、アプリケーションとの連携が必要であるため、プロジェクトのアーキテクチャーフェーズで考慮する必要があります。多くのパッケージ化されたアプリケーションは、これらのガイドラインの範囲内で作成されていないため、ピアツーピアの展開には適していません。
以下で、各要件について詳しく説明します。
ピアツーピアレプリケーションで唯一使用できるキーはプライマリキーです。テーブルにプライマリキーがなく、NULLでない一意キーがある場合、そのキーをプライマリキーに変換することができます。LONG列をキーの一部にすることはできません。
プライマリキーを割り当てることができず、すべての行が一意であることがわかっている場合は、すべてのテーブルに一意のインデックスを作成することができます。
プライマリキーはピアツーピア・レプリケーション・ネットワーク内のすべてのデータベース間で一意でなければなりません。これは、次のことを意味します。
プライマリキーは、その行の一意性に疑問が生じないように、また、レプリケートされた操作によって一意性が侵害された場合に競合が発生しないように、その行に関する十分な情報を含むように作成される必要があります。
プライマリキーの値は変更できません。
データベースでプライマリキーと一意キーのサプリメンタルロギングを有効にする必要があります。
シーケンスだけをプライマリキーとして使用することは、ピアツーピアレプリケーションではおそらく十分ではありません。例えば、サンプルテーブルがキー列EmpNoの値を生成するためにシーケンスを使用しているとします。UserAがSysAで次のシーケンス値を取得し、"Jane Wilson"の行を挿入します。UserBがSysBで次のシーケンス値を取得し、やはり"Jane Wilson"の行を挿入します。シーケンス番号がシステムごとに異なっており、レプリケートされたINSERTで一意キー違反が発生しないとしても、データベース内に"Jane Wilson"のエントリが2つ存在し、それぞれのキーが異なるため、データの整合性が損なわれます。それ以降のUPDATEは失敗します。解決策としては、キーに他の一意な列を含めることです。これにより、一意性を保証し、競合があっても解決ロジックで解決するのに十分な情報を確保できます。
SharePlexはシーケンスのピアツーピアレプリケーションをサポートしていません。アプリケーションがシーケンスを使用してキー全体または一部を生成する場合、 ピアツーピア設定内の他のシステムで同じ範囲の値が生成される可能性があってはなりません。シーケンスサーバを使用するか、各サーバでシーケンスを個別に管理して、それぞれ一意の範囲をパーティション化するようにできます。Questでは、n+1シーケンス生成(n=レプリケーション内のシステム数)を使用することをお勧めします。アプリケーションの種類によっては、一意性を確保するために、システム名などのロケーション識別子をプライマリキーのシーケンス値に追加することができます。
ソースシステムでトリガが起動された結果生じたDMLの変更は、REDOログに記録され、SharePlexによってターゲットシステムにレプリケートされます。ターゲットシステム上で同じトリガが起動されると、非同期エラーが返されます。
ピアツーピア設定でトリガを処理するには、以下のいずれかを実行できます。
ON DELETE CASCADE制約はピアツーピアレプリケーション設定でのすべてのインスタンスで有効なままにしておくことができますが、以下のパラメータを設定してこれらの制約を無視するようにPostに指示する必要があります。
UPDATEステートメントを使用して在庫や口座残高のような数量の変化を記録するアプリケーションは、ピアツーピアレプリケーションにとって難題です。次のオンライン書店の例では、その理由を説明します。
この書店の在庫表には以下の列が含まれています。
Book_ID (プライマリキー)
数量
次の一連のイベントが発生したとします。
競合解決手順を記述することはできますが、正しい値はどのように決定されるでしょうか? 2つのトランザクションの後、両方のデータベースの正しい値は97冊であるはずですが、2つのUPDATEステートメントのどちらを受け入れても、結果は正しくありません。
このため、UPDATEを使用して口座や在庫の残量を管理するアプリケーションでは、ピアツーピアレプリケーションは推奨されません。借方/貸方方式で残高を管理できる場合は、UPDATEステートメントの代わりにINSERTステートメント(在庫値「n」へのINSERTなど...)を使用できます。INSERTステートメントの場合、UPDATEステートメントと異なりWHERE句による前後の比較は必要ありません。
アプリケーションでUPDATEステートメントを使用する必要がある場合、競合解決手順を記述して、異なるシステムの異なるUPDATEステートメントによる絶対的な(または実質的な)変更を突き止めることができます。例えば、前述のオンライン書店の例の場合、最初の顧客の購入が2つ目のシステムにレプリケートされると、次の競合解決手順が起動します。
if existing_row.quantity <> old.quantity then old.quantity - new.quantity = quantity_change; update existing_row set quantity = existing_row.quantity - quantity_change;
競合解決ロジックは、ターゲットデータベースの既存の行の数量値(98)が古い値(プリイメージの100)と等しくない場合、新しい値(レプリケートされた値の99)をプリイメージから引いて、実質的な変更数(1)を取得するようにSharePlexに指示します。次に、Quantity列を98-1、つまり97に設定するUPDATEステートメントを発行します。
2人目のユーザの変更が最初のシステムにレプリケートされると、同じ競合解決手順が起動します。この場合、実質的な変更(プリイメージの100から新しい値98を引いたもの)は2です。このシステムのUPDATEステートメントもまた、99(最初の顧客の購入後の既存の行の値)から実質的な変更分の2を引いて、97を導き出します。この手順のロジックの結果、各システムのQuantity列が97に更新され、実質的に3冊の本が売れたことになります。
次の例では、財務記録内の口座残高を使ってこの概念を説明します。
account_number(プライマリキー)
balance
この種のトランザクションに対応するために、競合解決ルーチンを記述できます。この場合、口座の絶対的(または実質的)変更を計算し、その値を使用して競合を解決します。次などを考慮します。
if existing_row.balance <> old.balance then old.balance - new.balance = balance_change; update existing_row set balance = existing_row.balance - balance_change;
このルーチンの結果、500ドルの入金と250ドルの引き出しが反映され、口座残高は1750ドルに更新されます。SysBでは、このルーチンは古い残高1500から新しい(レプリケートされた)残高2000を差し引くようにSharePlexに指示し、増減純額の-500が導き出されます。UPDATEステートメントは、残高値を1250 - (-500) = 1750の正しい値に設定します。
SysAでは、レプリケートされた値1250が古い残高1500から差し引かれ、増減純額が250となります。UPDATEステートメントは、現在の残高2000からその値を引き、正しい値1750を取得します。
変更する正しい行をSharePlexが検索する際に、競合を回避または解決する環境が確立されている場合、残る唯一の競合の可能性は、ファクトデータ、つまり、同じ行の同じ列の値が2つ以上のシステムで異なる場合、どの変更を受け入れるか、です。そのために、アプリケーションがタイムスタンプ列とソース列の追加を受け入れることができる必要があります。ソースはテーブルのローカルシステムの名前です。
以下では、競合解決ルーチンを使用して優先順位を確立するときに、これらの列がどのように重要な役割を果たすかを説明します。
次の2つの理由から、特定のデータベースまたはサーバを優先ソース、つまり信頼できるソースに割り当てる必要があります。
テーブルにタイムスタンプ列を含め、競合解決ルーチンで、タイムスタンプが最も古いもの、または最も新しいものに優先順位を割り当てることを推奨します。ただし、タイムスタンプをキーの一部にしないでください。これは競合の原因になります。SharePlexはキーの値が変更されると行を見つけられなくなりますが、列の1つがタイムスタンプの場合、キーの値が変更されることになるからです。
タイムスタンプの優先順位を機能させるには、関係するすべてのサーバで日付と時刻が一致していることを確認する必要があります。異なるタイムゾーンにあるサーバ上のテーブルでは、グリニッジ標準時(GMT)を使用することができます。
関係するサーバが異なるタイムゾーンにある状況に対処するには、ルーチンが使用するテーブルにTIMESTAMP WITH LOCAL TIME ZONE列を指定し、ピアツーピアレプリケーション内のデータベースのDBTIMEZONEが同じであることを確認します。
SharePlexの競合解決のためのデフォルトの日付形式は、MMDDYYYY HH24MISSです。デフォルトの日付を持つテーブルは、そのフォーマットを使用する必要があります。そうしないと競合解決でエラーが返されます。デフォルトの日付を持つテーブルを作成する前に、SQL*Plusで以下のコマンドを使用して日付フォーマットを変更してください。
ALTER SESSION SET nls_date_format = 'MMDDYYYYHH24MISS'
ピアツーピア設定内の各システムの設定ファイルは、データソースの指定とルーティングを除いて同一です。
このトピックの設定構文では、プレースホルダは環境内の次の項目を表しています。このドキュメントでは3つのシステムを想定していますが、それ以上のシステムが存在することもあり得ます。
hostAは1つ目のシステムです。
重要! 設定ファイルのコンポーネントの詳細については、「データをレプリケートするためのSharePlexの設定ページを参照してください。
|
Datasource:o.oraA | ||
| ownerA.object | ownerB.object | hostB@o.oraB |
| ownerA.object | ownerB.object | hostB@o.oraB |
| ownerA.object | ownerC.object | hostC@o.oraC |
| ownerA.object | ownerC.object | hostC@o.oraC |
注意: すべての所有者名とテーブル名がすべてのシステムで同じである場合、これらの設定ファイルごとに複合ルーティングマップを使用できます。
例えば、hostAからのレプリケーションの複合ルーティングは次のようになります。
| Datasource:o.oraA | ||
| owner.object | owner.object | hostB@o.oraB+hostC@o.oraC |
|
Datasource:o.oraB | ||
| ownerB.object | ownerA.object | hostA@o.oraA |
| ownerB.object | ownerA.object | hostA@o.oraA |
| ownerB.object | ownerC.object | hostC@o.oraC |
| ownerB.object | ownerC.object | hostC@o.oraC |
|
Datasource:o.oraC | ||
| ownerC.object | ownerA.object | hostA@o.oraA |
| ownerC.object | ownerA.object | hostA@o.oraA |
| ownerC.object | ownerB.object | hostB@o.oraB |
| ownerC.object | ownerB.object | hostB@o.oraB |
| Datasource:o.oraA | ||
| hr.emp | hr.emp | hostB@o.oraB |
| hr.sal | hr.sal | hostB@o.oraB |
| cust.% | cust.% | hostB@o.oraB |
Oracle間の競合解決ルーチンの設定については、「OracleからOracleへのユーザ定義の競合解決ルーチン」を参照してください。
ピアツーピア設定内の各システムの設定ファイルは、データソースの指定とルーティングを除いて同一です。
このトピックの設定構文では、プレースホルダは環境内の次の項目を表しています。このドキュメントでは3つのシステムを想定していますが、それ以上のシステムが存在することもあり得ます。
hostAは1つ目のシステムです。
|
Datasource:r.demoA | ||
| schemaA.object | schemaB.object | hostB@r.demoB |
| schemaA.object | schemaB.object | hostB@r.demoB |
|
Datasource:r.demoB | ||
| schemaB.object | schemaA.object | hostA@r.demoA |
| schemaB.object | schemaA.object | hostA@r.demoA |
| Datasource:r.demoA | ||
| hr.emp | hr.emp | hostB@r.demoB |
| hr.sal | hr.sal | hostB@r.demoB |
PostgreSQLまたは PostgreSQL Database as a ServiceからPostgreSQLへの競合解決ルーチンの設定については、「PostgreSQLからPostgreSQLへのユーザ定義の競合解決ルーチン」を参照してください。
PostgreSQLまたはPostgreSQL Database as a ServiceからPostgreSQLへのレプリケーション用にSharePlexで用意されたルーチンについては、「SharePlex提供ルーチン」を参照してください。
ピアツーピア設定内の各システムの設定ファイルは、データソースの指定とルーティングを除いて同一です。
このトピックの設定構文では、プレースホルダは環境内の次の項目を表しています。このドキュメントでは3つのシステムを想定していますが、それ以上のシステムが存在することもあり得ます。
hostAはPostgreSQLシステムです。
|
Datasource:r.dbname | ||
| schemaA.tablename | ownerB.object | hostB@o.oraB |
| schemaA.tablename | ownerB.object |
hostB@o.oraB |
|
Datasource:o.oraB | ||
| ownerB.object | schemaA.tablename | hostA@r.dbname |
| ownerB.object | schemaA.tablename | hostA@r.dbname |
| Datasource:r.dbname | ||
| "demo"."data2k" | "demo"."data2k" | hostB@o.dbname |
| Datasource:o.dbname | ||
| "demo"."data2k" | "demo"."data2k" | hostB@r.dbname |
PostgreSQLまたは PostgreSQL Database as a ServiceからOracleへの競合解決ルーチンの設定については、「PostgreSQLからOracleへのユーザ定義の競合解決ルーチン」を参照してください。
PostgreSQLまたはPostgreSQL Database as a ServiceからOracleへのレプリケーション用にSharePlexで用意されたルーチンについては、「SharePlex提供ルーチン」を参照してください。
