SharePlexには、カスタムルーチンと組み合わせて使用するための準備されたオプションのルーチンがあります。これらのオプションは、基本的で一般的なコンフリクト解決フォーマットで使用することができます。列のタイプに制限はありません。
データベースでプライマリキーと一意キーのサプリメンタルロギングを有効にする必要があります。
OracleからOracleへ
PostgreSQLからPostgreSQLへ
PostgreSQLからOracleへ
PostgreSQL Database as a ServiceからPostgreSQL Database as a Serviceへ
PostgreSQL Database as a ServiceからOracleへ
PostgreSQL Database as a ServiceからPostgreSQLへ
SharePlexの準備されたルーチンを実施する前に、以下の考慮事項を確認してください。
この準備されたコンフリクト解決ルーチンは、INSERT、UPDATE、およびDELETE操作で機能します。これは、信頼できるソースシステム上で発生した行の変更に優先順位を割り当てることで、ホストベースのコンフリクト解決を実行します。信頼できるソースを定義するには、SP_OPO_TRUSTED_SOURCE(Oracleソース)またはSP_OPX_TRUSTED_SOURCE(PostgreSQLソース)パラメーターをソースシステム名に設定します。
| 操作 | 解決策 |
|---|---|
|
INSERT |
ソースがSP_OPO_TRUSTED_SOURCE(Oracleソース)またはSP_OPX_TRUSTED_SOURCE(PostgreSQLソース)で指定されたものである場合、INSERTをUPDATEに変換し、既存の行を上書きします。 そうでない場合は、変更レコードを破棄し、対象の行には何もしません。 |
| UPDATE |
ソースがSP_OPO_TRUSTED_SOURCE(Oracleソース)またはSP_OPX_TRUSTED_SOURCE(PostgreSQLソース)で指定されたものである場合、UPDATEを使用して既存の行を上書きし、WHERE句でキー列のみを使用します。そうでない場合は、変更レコードを破棄し、対象の行には何もしません。 |
| DELETE | 同期外エラーを無視し、ターゲット行には何もしません。 |
owner.table {I | U | D} !HostPriority
この準備されたルーチンは、INSERT、UPDATE、DELETE操作で機能します。これは、タイムスタンプによって決まる最も古い行の変更に優先順位を割り当てることで、時間ベースでコンフリクトを解決します。
タイムスタンプを取得するために、このルーチンを使用するテーブルには、テーブルに対してINSERTとUPDATEを実行するたびに更新されるNULLではないタイムスタンプ列が必要です。DMLまたは既存の行のタイムスタンプ列がNULLの場合、このルーチンはコンフリクトを解決できません。
このルーチンでは、OracleのSP_OCT_REDUCED_KEYパラメーターとPostgreSQLのSP_CAP_REDUCED_KEYパラメーターをソースシステム上で0に設定し、UPDATESのすべてのプリイメージの値をPost処理で使用できるようにする必要があります。
| 操作 | 解決策 |
|---|---|
|
INSERT および UPDATE |
|
| DELETE | コンフリクト(同期外メッセージ)を無視します。 |
owner.table {I | U | D} !LeastRecentRecord(col_name)
ここで、col_nameはルーチンが使用するタイムスタンプ列です。
|
注意:
|
この準備されたルーチンは、INSERT、UPDATE、DELETE操作で機能します。これは、タイムスタンプによって決まる最新の行の変更に優先順位を割り当てることで、時間ベースでコンフリクトを解決します。
タイムスタンプを取得するために、このルーチンを使用するテーブルには、テーブルに対してINSERTとUPDATEを実行するたびに更新されるNULLではないタイムスタンプ列が必要です。DMLまたは既存の行のタイムスタンプ列がNULLの場合、このルーチンはコンフリクトを解決できません。
このルーチンでは、OracleのSP_OCT_REDUCED_KEYパラメーターとPostgreSQLのSP_CAP_REDUCED_KEYパラメーターをソースシステム上で0に設定し、UPDATESのすべてのプリイメージの値をPost処理で使用できるようにする必要があります。
| 操作 | 解決策 |
|---|---|
|
INSERT および UPDATE |
|
| DELETE | コンフリクト(同期外メッセージ)を無視します。 |
owner.table {I | U | D} !MostRecentRecord(col_name)
ここで、col_nameはルーチンが使用するタイムスタンプ列です。
|
注意:
|
このルーチンはUPDATE操作に対して機能します。これは、変更された行のキー値のみに依存するコンフリクトを解決します。通常、SharePlexがデータをポストするSQLステートメントを構築する場合、WHERE句は、確実に同期させるために変更された列のキーとプリイメージの両方を使用します。!UpdateUsingKeyOnlyルーチンは、キーが一致することを前提に、プリイメージの値が一致しなくてもデータをポストするようSharePlexに指示します。
該当する場合は、このルーチンをUPDATEのための唯一のルーチンとして使用することもできます。ただし、複数のUPDATEが同時に行われる場合は、システム優先度や時間優先度などの優先度を割り当てるロジックが含まれないことに留意してください。同期外エラーを避けるため、Questでは、!UpdateUsingKeyOnlyをより具体的な他のルーチンと組み合わせて使用し、カスタムルーチンが失敗した場合の最終オプションとして!UpdateUsingKeyOnlyを使用することを推奨しています。
重要: !UpdateUsingKeyOnlyは、優先順位が最後になるようにルーチンのリストの最後のエントリにしなければなりません。
以下の例では、UPDATEの実行中にowner.table1でコンフリクトが発生すると、SharePlexが最初に(優先順位の高い順に)2つのカスタムルーチンを呼び出し、次に!UpdateUsingKeyOnlyルーチンを呼び出します。
| owner.table1 | u | owner.procedure_up_A |
| owner.table1 | u | owner.procedure_up_B |
| owner.table1 | u | !UpdateUsingKeyOnly |
!UpdateUsingKeyOnly名では大文字と小文字を区別します。単語と単語の間にはスペースを入れず、この手順にあるとおりに正確に入力する必要があります。設定ファイルにはこのルーチンの所有者名を記載しないでください。INSERTおよびDELETE操作には、カスタムロジックを使用する必要があります。
SharePlexの準備されたルーチンを使用している場合、成功したコンフリクトの解決操作に関する情報をログに記録するようにPostプロセスを設定することができます。この機能は、デフォルトでは無効になっています。
コンフリクト解決のロギングを有効にするには:
次のコマンドを入力します。
sp_ctrl> set param SP_OPO_LOG_CONFLICT {1 | 2}
1に設定すると、SHAREPLEX_CONF_LOGテーブルへのコンフリクト解決のロギングが有効になります。
注意: 1に設定すると、SHAREPLEX_CONF_LOGテーブルのEXISTING_TIMESTAMPおよびTARGET_ROWID列(既存のデータが置換されない場合)は更新されません。
2に設定すると、SHAREPLEX_CONF_LOGテーブルへのコンフリクト解決のロギングが、Postによる追加のメタデータのクエリと共に有効になります。
準備されたルーチンLeastRecentRecordまたはMostRecentRecordを使用すると、Postは既存のレコードのタイムスタンプ列のターゲットデータベースにクエリを実行します。クエリの結果は、SHAREPLEX_CONF_LOGテーブルのEXISTING_TIMESTAMP列にログ記録されます。
準備されたルーチンでは、入力されたレコードで置換されなかった行に対し、Postは置換される可能性のある既存の行のTARGET_ROWIDを問い合わせます。そうでない場合、既存の行のROWIDは記録されません。
注: 2と設定すると、クエリを実行した結果、Postのパフォーマンスに影響を与える可能性があります。
Postは、SHAREPLEX_CONF_LOGという名前のテーブルに情報を記録します。このテーブルについて以下に説明します。
| 列 | 列の定義 | ロギングされる情報 |
|---|---|---|
| CONFLICT_NO | NUMBER NOT NULL | 解決したコンフリクトの一意の識別子。この値はshareplex_conf_log_seqシーケンスから生成されます。 |
| CONFLICT_TIME | TIMESTAMP DEFAULT SYSTIMESTAMP | コンフリクト解決のタイムスタンプ |
| CONFLICT_TABLE | VARCHAR2(100) | コンフリクトが発生したターゲットテーブル名 |
| CONFLICT_TYPE | VARCHAR2(1) | コンフリクトのタイプ。IはInsert(挿入)、UはUpdate(アップデート)、DはDelete(削除) |
| CONFLICT_RESOLVED | VARCHAR2(1) NOT NULL |
コンフリクトが解決されたかどうかの指標 Y = はい(コンフリクトは解決済み) N=いいえ(コンフリクトは未解決)未解決のコンフリクトはID_errlog.sqlファイルに記録されます。ここで、IDはソースデータベース識別子です。 |
| TIMESTAMP_COLUMN | VARCHAR2(50) | 最新のレコードを判断するためにPostが比較した、タイムスタンプを含む列の名前 |
| INCOMING_TIMESTAMP | DATE | ソースシステムで行が挿入、更新、または削除されたときのタイムスタンプ |
| EXISTING_TIMESTAMP | DATE | ターゲットデータベース内の行の現在のタイムスタンプ。これは、SP_OPO_LOG_CONFLICTパラメーターが2に設定されている場合にのみ適用され、Postはこの値を取得するターゲットデータベースにクエリを実行します。 |
| PRIMARY_KEYS | VARCHAR2(4000) | プライマリキーの列の名前 |
| MESSAGE | VARCHAR2(400) |
コンフリクトでどちらの行が優先されたかを示すメッセージ。使用したコンフリクト解決ルーチンによって優先される行が決まります。例えば、!MostRecentRecordルーチンを使用したときに最新のレコードがソースレコードである場合、以下のメッセージを返します。 Incoming timestamp > existing timestamp. Incoming wins, overwrite existing. ターゲットレコードが最新のものであったり、ソースレコードと同じタイムスタンプである場合、メッセージは次のようになります。 Incoming timestamp <= existing timestamp. Existing wins, discard incoming. |
| SQL_STATEMENT | LONG | コンフリクト解消の結果として実行された最終SQLステートメント |
| CONFLICT_CHECKED | VARCHAR2(1) | コンフリクトを確認したユーザがいるかどうかを示します。デフォルトはN(なし)です。コンフリクトを確認するユーザは、この値をYに変更することができます。 |
SharePlexの準備されたルーチンを使用している場合、成功したコンフリクトの解決操作に関する情報をログに記録するようにPostプロセスを設定することができます。この機能は、デフォルトでは無効になっています。
コンフリクト解決のロギングを有効にするには:
次のコマンドを入力します。
sp_ctrl> set param SP_OPX_LOG_CONFLICT {1 | 2}
1に設定すると、shareplex_conf_logテーブルへのコンフリクト解決のロギングが有効になります。
注: 1に設定すると、shareplex_conf_logテーブルの列existing_timestamp(既存のデータが置換されない場合)は更新されません。
2に設定すると、shareplex_conf_logテーブルへのコンフリクト解決のロギングが、Postによる追加のメタデータのクエリと共に有効になります。
準備されたルーチンLeastRecentRecordまたはMostRecentRecordを使用すると、Postは既存のレコードのタイムスタンプ列のターゲットデータベースにクエリを実行します。クエリの結果は、shareplex_conf_logテーブルのexisting_timestamp列にログ記録されます。
注: 2と設定すると、クエリを実行した結果、Postのパフォーマンスに影響を与える可能性があります。
Postは、shareplex_conf_logという名前のテーブルに情報を記録します。このテーブルについて以下に説明します。
| 列 | 列の定義 | ロギングされる情報 |
|---|---|---|
| conflict_no | bigserial primary key | 解決したコンフリクトの一意の識別子。この値はshareplex_conf_log_conflict_no_seqシーケンスから生成されます。 |
| conflict_time | timestamp | コンフリクト解決のタイムスタンプ |
| src_host | varchar(64) | ソースホストのホスト名 |
| curr_host | varchar(64) | 現在のホストのホスト名 |
| trusted_host | varchar(64) | 信頼できるホストのホスト名。準備されたルーチン!HostPriorityの場合にこれが使用されます。 |
| src_db | varchar(150) | ソースデータベース名 |
| source_rowid | varchar(20) | ソース側のテーブルの行ID。PostgreSQLソースの場合、この列は適用されず、値はN/Aになります。 |
| target_rowid | varchar(20) | ターゲット側のテーブルの行ID。PostgreSQLターゲットの場合、この列は適用されず、値はN/Aになります。 |
| conflict_table | varchar(300) | コンフリクトが発生したターゲット側のテーブルの名前 |
| conflict_type | char(1) | コンフリクトのタイプ。IはInsert(挿入)、UはUpdate(アップデート)、DはDelete(削除) |
| conflict_resolved | char(1) not null |
コンフリクトが解決されたかどうかの指標 Y = はい(コンフリクトは解決済み) N=いいえ(コンフリクトは未解決)未解決のコンフリクトはID_errlog.sqlファイルに記録されます。ここで、IDはソースデータベース識別子です。 |
| odbc_error | varchar(20) | コンフリクトの原因となったodbcエラーを示します。フォーマットは<ネイティブエラー>:<エラーsqlstate>です。 |
この説明では、カスケードレプリケーション (多層レプリケーションとも呼ばれます)を設定する方法を示します。この戦略では、ソースシステムから中間システムにデータをレプリケートし、次に中間システムから1つまたは複数のリモート・ターゲット・システムにデータをレプリケートします。
カスケードレプリケーションは、さまざまなレプリケーションの目的をサポートするために、以下のような状況の回避策として使用できます。
カスケード戦略を使用するには、直接接続を行う機能は必要ありませんが、ソースマシンが最終的なターゲットマシン名を解決できる必要があります。
OracleおよびPostgreSQL
Oracle
OracleおよびOpen Target(最終ターゲット)
このレプリケーション戦略では以下をサポートします。
『SharePlexインストールガイド』の説明に従ってシステムを準備し、SharePlexをインストールして、データベースアカウントを設定します。
重要!SharePlexを使用して中間システム上のデータベースにポストする場合は、すべてのシステムで同じSharePlexユーザを作成します。
ターゲットオブジェクトに対してDMLを実行するトリガを無効にします。
ターゲットシステムでシーケンスが不要な場合は、レプリケートしないでください。レプリケーションが遅くなる可能性があります。ソーステーブルのキー生成にシーケンスが使用されている場合でも、レプリケートされた行がターゲットシステムに挿入されると、シーケンス値がキー列の一部になります。シーケンス自体をレプリケートする必要はありません。
中間システムを介したソースからターゲットへのDDLレプリケーションは、『管理ガイド』の「SharePlexがサポートするDDL」の章に記載されている情報に従ってサポートされます。ただし、次の例外があります。
重要! これらの説明は、SharePlex設定ファイルを完全に理解していることを前提としています。重要な構文要素の省略表現が使用されています。詳細については、データをレプリケートするためのSharePlexの設定を参照してください。
このトピックの設定構文では、プレースホルダは以下を表しています。
重要! データをレプリケートするためのSharePlexの設定ページを参照してください。
データをカスケードするには、以下のオプションがあります。
中間システムにデータベースがある場合、そのデータベースにポストし、データをもう一度キャプチャして1つ以上のリモートターゲットにレプリケートするようにSharePlexを設定できます。
中間システムにデータベースがない場合、データをインポートし、キューに入れてから、1つ以上のリモートターゲットにエクスポートするようにSharePlexを設定できます。システム上にCaptureプロセスはありません。これはパススルー設定として知られています。ソースシステムからターゲットシステムに直接データを渡します。
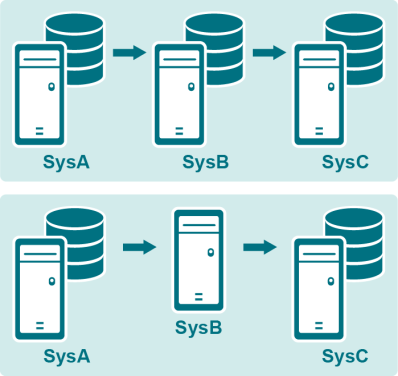
この設定を使用するには:
Oracle DDLレプリケーションは、中間システム上のOracleデータベースからターゲットシステムへのレプリケーションには対応していません。ソースシステムから中間システムへのレプリケーションのみサポートされます。
Captureが完了する前にREDOログがラップする場合に備えて、ソースシステムと中間システムでアーカイブロギングを有効にします。
この設定では、ソースシステムから中間システム上のデータベースにレプリケートします。
注意: このテンプレートでは、hostBが中間システムです。
|
datasource_specification |
||
| source_specification1 | target_specification1 | hostB@o.SID |
| source_specification2 | target_specification2 | hostB@o.SID |
| Datasource:o.oraA | ||
| hr.emp | hr.emp2 | hostB@o.oraB |
| hr.sal | hr.sal2 | hostB@o.oraB |
| cust.% | cust.% | hostB@o.oraB |
注意: この同じ設定で、他のソースオブジェクトからのデータを、中間システムを介してカスケードせずに他のターゲットに直接ルーティングすることができます。別の行で適切なルーティングを指定するだけです。
この設定では、中間システム上のデータベースからデータをキャプチャし、そのデータをターゲットシステムにレプリケートします。ソース設定ではターゲットテーブルであったテーブルが、この設定ではソーステーブルになります。ターゲットは、サポートされているどのSharePlexターゲットでも可能です。
|
datasource_specification |
||
| source_specification1 | target_specification1 | hostC[@db][+...] |
| source_specification2 | target_specification2 | hostD[@db][+...] |
| Datasource:o.oraB | ||
| hr.emp | hr.emp2 | hostC@o.oraC |
| hr.sal | hr.sal2 | hostD@o.oraD+hostE@r.mssE |
| cust.% | cust.% | !cust_partitions |
注意: この例の最後の項目は、水平分割レプリケーションを使用して、sales.accountsテーブルのさまざまなデータをさまざまな地域データベースに配布する方法を示しています。詳細については、水平分割レプリケーションの設定を参照してください。を参照してください。
(Oracle中間データベース)中間データベースがOracleの場合、 SP_OCT_REPLICATE_POSTERパラメータを1に設定します。これにより、中間システム上のCaptureプロセスに、SharePlexによってポストされた変更をキャプチャし、ターゲットシステムにレプリケートするように指示します。(デフォルトは0であり、Captureが同じシステム上のPostアクティビティを無視することを意味します。)
sp_ctrlで、以下のコマンドを発行します。この変更は、次にCaptureを開始したときに有効になります。
set param SP_OCT_REPLICATE_POSTER 1
この設定を使用するには:
oratabファイルに、OracleインスタンスとORACLE_SID指定を作成します(UnixおよびLinuxシステム)。データベースは空でも構いません。
DDLレプリケーションはサポートされていません。
注意: このテンプレートでは、hostBが中間システムです。
|
datasource_specification | ||
| source_specification1 | target_specification1 | hostB*hostC[@db] |
| source_specification2 | target_specification2 | hostB*hostD[@db][+hostB*hostE[@db][+...] |
| source_specification3 | target_specification3 | hostB*hostX[@db]+hostY[@db] |
| Datasource:o.oraA | ||
| hr.emp | hr.emp2 | hostB*hostC@o.oraC |
| hr.emp | hr."Emp_3" | hostB*hostC@r.mssB |
| cust.% | cust.% | hostB*hostD@o.oraD+hostE@o.oraE |
この説明では、高可用性の目的でSharePlexをセットアップし、ソースデータベースのミラーであるセカンダリOracleデータベースにレプリケートする方法を示します。この戦略では、互いに逆向きの2つのSharePlex設定による双方向のレプリケーションを使用します。セカンダリ(スタンバイ)マシンの設定は、プライマリマシンに障害が発生した場合のフェールオーバーに備えて、そのシステムのExportプロセスを停止したままアクティブな状態を維持します。
注意: CrunchyData高可用性クラスタ環境のセットアップ情報については、『SharePlexインストールおよびセットアップガイド』の「PostgreSQL高可用性クラスタへのSharePlexのインストール」セクションを参照してください。
この戦略は、以下のようなビジネス要件をサポートします。
この戦略では、SharePlexは次のように動作します。
OracleおよびPostgreSQL
Oracle
このレプリケーション戦略は、名前付きexportキューとpostキューの使用をサポートします。
注意: 列のマッピングと分割レプリケーションは、高可用性設定では適切ではありません。ソースとターゲットのオブジェクトは異なる名前を持つことができますが、これは高可用性構造の管理をより複雑にします。
すべてのシステムでアーカイブロギングを有効にします。
フェールオーバーの目的では、以下が必要です。
注意: Oracleのホットバックアップを使用してセカンダリインスタンスを作成する場合は、スクリプトを保存しておいてください。これを修正することで、プライマリインスタンスを再作成することができます。
このトピックの設定構文では、プレースホルダは以下を表しています。
hostAはプライマリシステムです。
重要! 設定ファイルのコンポーネントの詳細については、「データをレプリケートするためのSharePlexの設定」を参照してください。
高可用性設定は、互いに逆向きの2つの設定を使用します。データベース内の全オブジェクトをレプリケートする場合、config.sqlスクリプトを使用すると、設定プロセスを簡素化できます。詳細については、『SharePlexリファレンスガイド』の「設定スクリプト」セクションを参照してください。
|
Datasource:o.oraA |
||
| ownerA.object | ownerB.object | hostB@o.oraB |
|
Datasource:o.oraB |
||
| ownerB.object | ownerA.object | hostA@o.oraA |
高可用性環境でシステムに障害が発生した場合、レプリケーションをセカンダリシステムに移動し、リストア後にプライマリシステムに戻すことができます。詳細については、Oracleのフェイルオーバー後のレプリケーションのリカバリ を参照してください。
