These instructions show you how to set up SharePlex for the purpose of maintaining multiple databases, where applications on each system can make changes to the same data, while SharePlex keeps all of the data synchronized through replication. This is known as peer-to-peer, or active-active, replication. In this strategy, the databases are usually mirror images of each other, with all objects existing in their entirety on all systems. Although similar in benefit to a high-availability strategy, the difference between the two is that peer-to-peer allows concurrent changes to the same data, while high availability permits changes to the secondary database only in the event that the primary database goes offline.
This strategy supports the following business requirements:
An example of peer-to-peer replication is an e-commerce company with three identical databases. When users access the application from a web browser, the web server connects to any of those databases sequentially in a round-robin configuration. If one of the databases is unavailable, the server connects to a different available database server. Thus the configuration serves not only as a failover resource, but also as a means of distributing the load evenly among all the peers. Should the company need to produce business reports, user access to one of the databases can be stopped temporarily, and that database can be used to run the reports.
Note: Data changes made in peer-to-peer replication are prevented from looping back from one machine to another because Capture ignores transactions performed on the local system by the Post process.
Peer-to-peer replication is not appropriate for all replication environments. It requires a major commitment to database design that might not be practical when packaged applications are in use. It also requires the development of conflict resolution routines to prioritize which transaction SharePlex posts to any given database if there are multiple changes to the same data at or near the same time.
Oracle to Oracle
This replication strategy supports the following:
This replication strategy does not support the following:
Prepare the system, install SharePlex, and configure database accounts according to the instructions in the SharePlex Installation Guide.
In peer-to-peer replication, DML changes are allowed on copies of the same tables in different databases, usually on different systems, while SharePlex keeps them all current through replication. If a record is changed in more than one database at (or near) the same time, conflicts can occur, and conflict-resolution logic must be applied to resolve the discrepancy.
A conflict is defined as an out-of-sync condition — source and target tables are not identical. You can predict that out-of-sync (conflict) situations will occur when a DML statement constructed by SharePlex fails to execute on a row in the target table because of the following reasons:
Post applies a replicated INSERT but a row with the same key already exists in the target. Post applies the following logic:
Note: You can configure Post so that it does not consider non-key values when posting an INSERT. See the SP_OPO_SUPPRESSED_OOS parameter in the SharePlex Reference Guide.
Post applies a replicated UPDATE but either cannot find a row in the target with the same key value as the one in the UPDATE or Post finds the correct row but the row values do not match the before values in the UPDATE. Post applies the following logic:
Note: You can configure Post so that it returns an out-of-sync message if the current values in the target row match the after values of the UPDATE. See the SP_OPO_SUPPRESSED_OOS parameter in the SharePlex Reference Guide.
To understand how SharePlex determines a conflict, refer to the following examples of normal and conflict situations. In the examples, three systems (SysA, SysB and SysC) are used.
The following tables are used in the example:
Scott.employee_source
jane.employee_backup
The column names and definitions are identical:
| EmpNo | number(4) not null, |
| SocSec | number(11) not null, |
| EmpName | char(30), |
| Job | char(10), |
| Salary | number(7,2), |
| Dept | number(2) |
The values for both tables in a synchronized state are:
| EmpNo (key) | SocSec | EmpName | Job | Salary | Dept |
|---|---|---|---|---|---|
| 1 | 111-22-3333 | Mary Smith | Manager | 50000 | 1 |
| 2 | 111-33-4444 | John Doe | Data Entry | 20000 | 2 |
| 3 | 000-11-2222 | Mike Jones | Assistant | 30000 | 3 |
| 4 | 000-44-7777 | Dave Brown | Manager | 45000 | 3 |
Now the row looks like this:
| EmpNo (key) | SocSec | EmpName | Job | Salary | Dept |
| 1 | 111-22-3333 | Mary Smith | Manager | 50000 | 3 |
Note: For more information, see Appendix A: Peer-To-Peer Diagram.
To deploy peer-to-peer replication, perform the following tasks:
To successfully deploy SharePlex in a peer-to-peer configuration, you must be able to:
These requirements must be considered during the architectural phase of the project, because they demand cooperation with the application. Consequently, many packaged applications are not suitable for a peer-to-peer deployment because they were not created within those guidelines.
Following are more detailed explanations of each of the requirements.
The only acceptable key in peer-to-peer replication is a primary key. If a table has no primary key but has a unique, not-NULL key, you can convert that key to a primary key. LONG columns cannot be part of the key.
If you cannot assign a primary key, and you know all rows are unique, you can create a unique index on all tables.
The primary key must be unique among all of the databases in the peer-to-peer replication network, meaning:
The primary key must be created to contain enough information about a row so there can be no question about the uniqueness of that row, and so that there will be a conflict if a replicated operation would violate uniqueness.
The primary key value cannot be changed.
Supplemental logging of primary and unique keys must be enabled in the database.
Using only a sequence as the primary key probably will not suffice for peer-to-peer replication. For example, suppose the sample table uses sequences to generate values for key column EmpNo. Suppose UserA gets the next sequence value on SysA and inserts a row for “Jane Wilson.” UserB gets the next sequence value on SysB and also inserts a row for “Jane Wilson.” Even if the sequence numbers are different on each system, so there are no unique key violations on the replicated INSERTs, data integrity is compromised because there are now two entries for “Jane Wilson” in the databases, each with a different key. Subsequent UPDATEs will fail. The solution is to include other unique columns in the key, so that there is enough information to ensure uniqueness and ensure a conflict that can then be resolved through resolution logic.
SharePlex does not support peer-to-peer replication of sequences. If the application uses sequences to generate all or part of a key, there must be no chance for the same range of values to be generated on any other system in the peer-to-peer configuration. You can use a sequence server or you can maintain sequences separately on each server and make sure you partition a unique range to each one. Quest recommends using n+1 sequence generation (where n = the number of systems in replication). Depending on the type of application, you can add a location identifier such as the system name to the sequence value in the primary key to enforce uniqueness.
DML changes resulting from triggers firing on a source system enter the redo log and are replicated to the target system by SharePlex. If the same triggers fire on the target system, they return out-of-sync errors.
To handle triggers in a peer-to-peer configuration, you can do either of the following:
ON DELETE CASCADE constraints can remain enabled on all instances in the peer-to-peer replication configuration, but you must set the following parameters to direct Post to ignore those constraints:
Applications that use UPDATE statements to record changes in quantity, such as inventory or account balances, pose a challenge for peer-to-peer replication. The following example of an online bookseller explains the reason why.
The bookseller’s Inventory table contains the following columns.
Book_ID (primary key)
Quantity
Suppose the following sequence of events takes place:
A conflict resolution procedure could be written, but how would the correct value be determined? The correct value in both databases after the two transactions should be 97 books, but no matter which of the two UPDATE statements is accepted, the result is incorrect.
For this reason, peer-to-peer replication is not recommended for applications maintaining account or inventory balances using UPDATEs. If you can use a debit/credit method of maintaining balances, you can use INSERT statements (INSERT into inventory values “n”,...) instead of UPDATE statements. INSERT statements do not require a before-and-after comparison with a WHERE clause, as do UPDATE statements.
If your application must use UPDATE statements, you can write a conflict resolution procedure to determine the absolute (or net) change resulting from different UPDATE statements on different systems. For example, in the case of the preceding online bookseller example, when the first customer’s purchase is replicated to the second system, the following conflict resolution procedure fires:
if existing_row.quantity <> old.quantity then old.quantity - new.quantity = quantity_change; update existing_row set quantity = existing_row.quantity - quantity_change;
The conflict resolution logic tells SharePlex that, if the quantity value of the existing row in the target database (98) does not equal the old value (pre-image of 100), then subtract the new value (the replicated value of 99) from the pre-image to get the net change (1). Then, issue an UPDATE statement that sets the Quantity column to 98-1, which equals 97.
When the second user’s change is replicated to the first system, the same conflict resolution procedure fires. In this case, the net change (pre-image of 100 minus the new value of 98) is 2. The UPDATE statement on this system also results in a value of 97, which is 99 (the existing row value after the first customer’s purchase) minus the net change of 2. The result of this procedure’s logic is that the Quantity columns on each system are updated to 97 books, the net effect of selling three books.
The following example illustrates this concept using an account balance within a financial record:
account_number (primary key)
balance
You can write a conflict resolution routine to accommodate this kind of transaction by calculating the absolute (or net) change in the account, then using that value to resolve the conflict. For example:
if existing_row.balance <> old.balance then old.balance - new.balance = balance_change; update existing_row set balance = existing_row.balance - balance_change;
The result of this procedure would be to update the account balance to $1750, the net effect of depositing $500 and withdrawing $250. On SysB, the routine directs SharePlex to subtract the new (replicated) balance of 2000 from the old balance of 1500 for a net change of -500. The UPDATE statement sets the balance value to 1250 - (-500) = 1750, the correct value.
On SysA, the replicated value of 1250 is subtracted from the old balance of 1500 to get the net change of 250. The UPDATE statement subtracts that value from the existing balance of 2000 to get the correct value of 1750.
When the environment is established to avoid or resolve conflict when SharePlex searches for the correct row to change, the only remaining conflict potential is on fact data — which change to accept when the values for the same column in the same row differ on two or more systems. For this, your application must be able to accept the addition of timestamp and source columns, with source being the name of the local system for the table.
The following explains how those columns play a vital role when using a conflict resolution routine to establish priority.
You must assign a particular database or server to be the prevailing, or trusted, source for two reasons:
It is recommended that you include a timestamp column in the tables and assign priority in the conflict resolution routine to the earliest or latest timestamp. However, the timestamp must not be part of a key, or it will cause conflicts. SharePlex cannot locate rows if a key value changes — and the key value will change if one of the columns is a timestamp.
For timestamp priority to work, you must make sure all of the servers involved agree on the date and time. Tables on servers in different time zones can use Greenwich Mean Time (GMT).
The default date format for SharePlex conflict resolution is MMDDYYYY HH24MISS. Tables with default dates must use that format, or conflict resolution will return errors. Before creating a table with a default date, use the following command to change the date format in SQL*Plus.
ALTER SESSION SET nls_date_format = 'MMDDYYYYHH24MISS'
The configuration files on the systems in a peer-to-peer configuration are identical with the exception of the datasource specification and the routing.
In the configuration syntax in this topic, the placeholders represent the following items in the environment. This documentation assumes three systems, but there can be more.
hostA is the first system.
Important!
|
Datasource:o.oraA | ||
| ownerA.object | ownerB.object | hostB@o.oraB |
| ownerA.object | ownerB.object | hostB@o.oraB |
| ownerA.object | ownerC.object | hostC@o.oraC |
| ownerA.object | ownerC.object | hostC@o.oraC |
Note: If all owner names and table names are the same on all systems, you can use a compound routing map for each of these configuration files. For example, the compound routing for replication from hostA is as follows:
| Datasource:o.oraA | ||
| owner.object | owner.object | hostB@o.oraB+hostC@o.oraC |
|
Datasource:o.oraB | ||
| ownerB.object | ownerA.object | hostA@o.oraA |
| ownerB.object | ownerA.object | hostA@o.oraA |
| ownerB.object | ownerC.object | hostC@o.oraC |
| ownerB.object | ownerC.object | hostC@o.oraC |
|
Datasource:o.oraC | ||
| ownerC.object | ownerA.object | hostA@o.oraA |
| ownerC.object | ownerA.object | hostA@o.oraA |
| ownerC.object | ownerB.object | hostB@o.oraB |
| ownerC.object | ownerB.object | hostB@o.oraB |
| Datasource:o.oraA | ||
| hr.emp | hr.emp | hostB@o.oraB |
| hr.sal | hr.sal | hostB@o.oraB |
| cust.% | cust.% | hostB@o.oraB |
To create conflict resolution routines, you write PL/SQL procedures that direct the action of SharePlex when a conflict occurs. Business rules vary widely from company to company, so it is impossible to create a standard set of conflict resolution rules and syntax that apply in every situation. You will probably need to write your own routines. It is good practice to write more than one procedure, such as making site or system priority the primary routine and timestamp a secondary routine. SharePlex invokes one routine after another until one succeeds or there are no more procedures available.
SharePlex provides the following tools that can be used as a basis for your routines:
Important!
SharePlex provides a generic conflict resolution PL/SQL package that can be used to pass information to and from the procedural routines that you write.
Note: Custom routines are supported for Oracle to Oracle source-target combinations only.
Before you get started, understand the following guidelines:
Note: If you ran the SharePlex conflict resolution demonstration in the SharePlex Installation and Setup Guide, you can view a sample generic conflict resolution routine by viewing the od_employee_gen routine that was installed in the database used for the demonstration.
Follow this template to create your procedure.
| (table_info in outsplex.sp_cr.row_typ, col_values insplex.sp_cr.col_def_tabtyp) |
where:
SharePlex defines PL/SQL record and table structures in a public package named sp_cr in the SharePlex database schema. The package uses the following parameters.
"CREATE or REPLACE PACKAGE %s.sp_cr AS
"TYPE row_typ IS RECORD
"(src_host VARCHAR2(32),
"src_ora_sid VARCHAR2(32),
"src_ora_time VARCHAR2(20),
"source_rowid VARCHAR2(20),
"target_rowid VARCHAR2(20),
"statement_type VARCHAR2(6),
"source_table VARCHAR2(78),
"target_table VARCHAR2(78), \n\t"
"oracle_err NUMBER,
"status NUMBER,
"action NUMBER,
"reporting NUMBER
");
For each row operation that causes a conflict, SharePlex passes this metadata information to your procedure.
| Variable | Description |
|---|---|
| src_host | The name of the source system (where the operation occurred). It is case-sensitive and is passed using the same case as on the source system, for example SysA. If there are named post queues in use on the target system, this variable consists of the name of the post queue, for example postq1. |
| src_ora_sid | The ORACLE_SID of the source database. It is case-sensitive and is passed in the same case as in the oratab file, Windows Registry or V$PARAMETER table. |
| src_ora_time | The timestamp of the change record in the source redo log. |
| source_rowid | The row ID of the source row. It is passed as a literal within single quotes, for example ‘123456’. |
| target_rowid | The row ID of the corresponding row in the target database. SharePlex obtains the row ID by querying the target database. It is passed as a literal within single quotes, for example ‘123456’. If the row cannot be found using the PRIMARY key, the value is NULL. |
| statement_type | A letter, either I, U or D, indicating whether the operation is an INSERT, UPDATE or DELETE statement. |
| source_table | The owner and name of the source table, expressed as owner.table. This value is case-sensitive and matches the way the table is named in the database. It is passed within double quotes, for example "scott"."emp." |
| target_table | The owner and name of the target table, expressed as owner.table. This value is case-sensitive and matches the way the table is named in the database. It is passed within double quotes, for example "scott"."emp." |
| oracle_err |
This is different, depending on whether the procedure is being used for conflict resolution or transformation. Transformation: SharePlex passes a value of 0 for this variable. This variable is only used for conflict resolution. Conflict resolution: The Oracle error number that caused the conflict. |
These variables direct the action of SharePlex based on whether the procedure succeeded or failed).
| Variable | Description |
|---|---|
| status |
Defines whether or not the procedure succeeded. You must specify a value for this parameter.
|
| action |
Defines the action that you want SharePlex to take. This is different, depending on whether the procedure is used for transformation or conflict resolution. Transformation: You must specify a value of 0 for this parameter, which directs SharePlex NOT to post the SQL statement. Your transformation routine is responsible for posting the results of the transformation either to the target table or another table. The outcome of this action depends on what you specify for the reporting variable Conflict resolution: Specifies the action to take as a result of an unsuccessful conflict resolution procedure. You must specify a value for this parameter.
|
| reporting |
Determines how SharePlex reports unsuccessful procedural results. You must specify a value for this parameter.
|
SharePlex creates a col_def_tabtyp PL/SQL table for each replicated operation. This table stores column information. It is different depending on whether the procedure is used for transformation or conflict resolution.
All fields are passed by SharePlex to your routine, although not all will have values if SharePlex cannot locate the row.
Following is the data type that is used to populate the col_def_tabtyp table.
type col_def_typ is record (column_name user_tab_columns.column_name%type ,data type user_tab_columns.data type%type ,is_key boolean ,is_changed boolean ,old_value varchar2(32764) ,new_value varchar2(32764) ,current_value varchar2(32764) ); type col_def_tabtyp is table of col_def_typ
| Column | Description |
|---|---|
| column_name | Tells your procedure the name of the column that was replicated from the source table, for example emp_last_name. This value is not case-sensitive. |
| data type | Tells your procedure the data type of the data in the replicated column, for example VARCHAR2. This value is always in capital letters. |
| is_key | Tells your procedure whether or not the column is a key column. If it is a key column, SharePlex passes a value of TRUE. If the column is not part of a key, SharePlex passes a value of FALSE. |
| is_changed |
Tells your procedure whether or not the column value has changed. If it is changed, SharePlex passes a value of TRUE. If the column is not changed, SharePlex passes a value of FALSE.
|
| old_value |
Tells your procedure the old value of the replicated column, before it was changed on the source system. This column is NULL for INSERTs, because the row did not exist in the target database before the INSERT. Conflict resolution only: This is the pre-image against which SharePlex compared the source and target columns as part of its synchronization check for UPDATEs and DELETEs. If the old value passed by SharePlex does not match the current_value value obtained from the target row, then there is a conflict. |
| new_value | Tells your procedure the new value of the replicated column, as changed on the source system. |
| current_value | Tells your procedure the current value of the column in the target table. If SharePlex cannot locate the target row, the value is NULL. |
The following tables illustrate the possible outcomes of each type of operation.
| column_name | is_changed | old_value | new_value | current_value1 | is_key |
|---|---|---|---|---|---|
| C1 | TRUE | NULL | bind | NULL | FALSE |
| C2 | TRUE | NULL | bind | NULL | TRUE |
| C3 | FALSE | NULL | NULL | NULL | TRUE | FALSE |
1 When an INSERT fails, it is because a row with the same PRIMARY key already exists in the target database. SharePlex does not return the current value for INSERTs.
| column_name | is_changed | old_value | new_value | current_value1, 2 | is_key |
|---|---|---|---|---|---|
| C1 | TRUE | bind | bind | NULL | target_value | FALSE |
| C2 | FALSE | bind | NULL | NULL | target_value | TRUE |
| C3 | TRUE | bind | bind | NULL | target_value | TRUE |
1 (Conflict resolution) When an UPDATE fails, it is because SharePlex cannot find the row by using the PRIMARY key and the pre-image. If the row cannot be found, SharePlex searches for the row by using only the PRIMARY key. If SharePlex finds the row, it returns the current value for the key column as well as the changed columns. If SharePlex cannot find the row by using just the PRIMARY key, then SharePlex returns a NULL.
2 (Transformation) For an UPDATE, SharePlex cannot locate a row using the PRIMARY key and the pre-images, because the pre-images are different due to transformation. As an alternative, it searches for the row using just the PRIMARY key. If it finds it, SharePlex returns the current value for the key column as well as the changed columns. If it cannot locate the row using just the PRIMARY key, then current_value is NULL
| column_name | is_changed | old_value | new_value | current_value1 | is_key |
|---|---|---|---|---|---|
| C1 | FALSE | bind | NULL | NULL | TRUE |
1 When a DELETE fails, it is because SharePlex could not find the row by using the PRIMARY key. Therefore, SharePlex returns a NULL.
SharePlex provides optional prepared routines for use in conjunction with custom routines. These options can be used with basic and generic conflict resolution formats. There are no limitations on column types.
Supplemental logging of primary and unique keys must be enabled in the database.
Review the following considerations before implementing SharePlex prepared routines.
This routine works for UPDATE operations. It provides conflict resolution that relies solely on the key value of the changed row.
Note: This routine can be used only with an Oracle to Oracle source-target combination.
Supported source-target: This routine can be used only with Oracle to Oracle source-target combinations.
Normally, when SharePlex builds a SQL statement to post data, the WHERE clause uses both the key and the pre-image of the columns that changed to ensure synchronization. The !UpdateUsingKeyOnly routine directs SharePlex to post the data even though the pre-image values do not match, assuming the keys match.
If appropriate, this routine can be used as the sole routine for UPDATEs, but with the understanding that it does not include logic that assigns priority, such as system or time priority, in case of multiple concurrent UPDATEs. To avoid out-of-sync errors, Quest recommends using !UpdateUsingKeyOnly in conjunction with other, more specific routines, relying on !UpdateUsingKeyOnly as a final option if the custom routines fail.
Important: !UpdateUsingKeyOnly must be the last entry in the list of routines, thus assigning it last priority.
In the following example, when there is a conflict for owner.table1 during an UPDATE, SharePlex calls the two custom routines first (in order of priority) and then calls the !UpdateUsingKeyOnly routine.
| owner.table1 | u | owner.procedure_up_A |
| owner.table1 | u | owner.procedure_up_B |
| owner.table1 | u | !UpdateUsingKeyOnly |
The !UpdateUsingKeyOnly name is case sensitive. It must be typed exactly as shown in these instructions, with no spaces between words. Do not list an owner name with this routine in the configuration file. For more information, see List the routines in conflict_resolution.SID.
For INSERT and DELETE operations, custom logic must be used.
This prepared conflict resolution routine works for INSERT, UPDATE, and DELETE operations. It provides host-based conflict resolution by assigning priority to the row change that originated on the trusted source system. To define the trusted source, set the SP_OPO_TRUSTED_SOURCE or SP_OPX_TRUSTED_SOURCE parameter to the name of the source system.
| Operation | Resolution Action |
|---|---|
|
INSERT |
If the source is the one specified with SP_OPO_TRUSTED_SOURCE or SP_OPX_TRUSTED_SOURCE, convert the INSERT to an UPDATE and overwrite the existing row. Otherwise, discard the change record and do nothing to the target row. |
| UPDATE |
(Oracle only) If the source is the one specified with SP_OPO_TRUSTED_SOURCE, overwrite the existing row using an UPDATE and use only the key columns in the WHERE clause. Otherwise, discard the change record and do nothing to the target row. |
| DELETE | Ignore the out-of-sync error and do nothing to the target row. |
owner.table {I | U | D} !HostPriority
For more information, see List the routines in conflict_resolution.SID.
This prepared routine works for INSERT, UPDATE, and DELETE operations. It provides time-based conflict resolution by assigning priority to the most recent row change, as determined by a timestamp.
Note: This routine can be used only with an Oracle to Oracle source-target combination.
To capture the timestamp, tables using this routine must have a non-NULL timestamp column that is updated with every INSERT and UPDATE on the table. If the timestamp column in the DML, or in the existing row, is NULL, this routine cannot resolve the conflict.
This routine requires the SP_OCT_REDUCED_KEY parameter to be set to 0 on the source system, so that all of the pre-image values of UPDATES are available to the Post process.
| Operation | Resolution Action |
|---|---|
|
INSERT and UPDATE |
|
| DELETE | Ignore the conflict (out-of-sync message). |
owner.table {I | U | D} !MostRecentRecord(col_name)
Where col_name is the timestamp column to be used by the routine.
See List the routines in conflict_resolution.SID.
This prepared routine works for INSERT, UPDATE, and DELETE operations. It provides time-based conflict resolution by assigning priority to the least recent row change, as determined by a timestamp.
Note: This routine can be used only with an Oracle to Oracle source-target combination.
To capture the timestamp, tables using this routine must have a non-NULL timestamp column that is updated with every INSERT and UPDATE on the table. If the timestamp column in the DML, or in the existing row, is NULL, this routine cannot resolve the conflict.
| Operation | Resolution Action |
|---|---|
|
INSERT and UPDATE |
|
| DELETE | Ignore the conflict (out-of-sync message). |
owner.table {I | U | D} !LeastRecentRecord(col_name)
Where col_name is the timestamp column to be used by the routine.
See List the routines in conflict_resolution.SID.
After you create the conflict resolution procedure(s), construct the conflict resolution file. This file tells SharePlex which procedures to use for which objects and operation types, and in which order.
A blank conflict_resolution.SID file, where SID is the ORACLE_SID of the target instance, was included in the data sub-directory of the SharePlex variable-data directory when SharePlex was installed. Use the file on the target system.
If this file does not exist, you can create one in ASCII format in an ASCII text editor. It must be named conflict_resolution.SID, where SID is the ORACLE_SID of the target instance. Note: the SID is case-sensitive.
Important! There can be only one conflict_resolution.SID file per active configuration.
Use the following template to link a procedure to one or more objects and operation types.
| owner.object | {i | u | d | iud} | owner.procedure |
where:
| scott.sal | IUD | scott.sal_cr |
| like:scott.%\_corp\_emp | IUD | scott.emp_cr1 |
| like:scott.%\_corp\_emp | IUD | scott.emp_cr2 |
| like:scott% | IUD | scott.emp_cr3 |
| scott.cust | U | scott.sal_cr |
How it works:
To use the SharePlex prepared routines for all tables in the replication configuration, use the !DEFAULT parameter instead of specifying an owner and object name.
A custom routine takes priority over a SharePlex prepared routine. A prepared routine is used only if the custom routine fails. This is true regardless of the order in which the !DEFAULT-associated routine appears in the file.
The !DEFAULT parameter is case-sensitive. It must be typed in all capital letters.
In the following example, the !UpdateUsingKeyOnly procedure is used for UPDATEs and DELETEs for all tables, including james.table1, although the user-defined procedures listed for james.table1 take precedence.
| !DEFAULT | U | !UpdateUsingKeyOnly |
| !DEFAULT | D | !UpdateUsingKeyOnly |
| james.table1 | U | james.procedure_upd |
| james.table1 | I | james.procedure_ins |
| james.table1 | D | james.procedure_del |
You can change the conflict resolution file any time during replication to add and remove tables and procedures. After you change the conflict resolution file, stop and re-start the Post process.
You can configure the Post process to log information about successful conflict resolution operations if you are using the SharePlex prepared routines. This feature is disabled by default.
Note: This feature can be used only with Oracle to Oracle source-target combinations.
To enable the logging of conflict resolution
Issue the following command:
sp_ctrl> set param SP_OPO_LOG_CONFLICT {1 | 2}
A setting of 2 enables the logging to the SHAREPLEX_CONF_LOG table and also directs Post to log the following to the Post process log:
Note: A setting of 2 may affect the performance of Post as a result of making the query.
Post logs the information to a table named SHAREPLEX_CONF_LOG. The following describes this table.
| Column | Column Definition | Information that is logged |
|---|---|---|
| CONFLICT_NO | NUMBER NOT NULL | The unique identifier of the resolved conflict. This value is generated from the shareplex_conf_log_seq sequence. |
| CONFLICT_TIME | TIMESTAMP DEFAULT SYSTIMESTAMP | The timestamp of the conflict resolution |
| CONFLICT_TABLE | VARCHAR2(100) | The name of the target table that was involved in the conflict |
| CONFLICT_TYPE | VARCHAR2(1) | The type of conflict, either I for insert, U for update, or D for delete |
| CONFLICT_RESOLVED | VARCHAR2(1) NOT NULL |
Indicator of whether the conflict was resolved or not. Y = yes, the conflict was resolved N = no, the conflict was not resolved. Unresolved conflicts are logged to the ID_errlog.sql file, where ID is the source database identifier. |
| TIMESTAMP_COLUMN | VARCHAR2(50) | The name of the column that contains the timestamp that Post compared to determine which record was most recent. |
| INCOMING_TIMESTAMP | DATE | The timestamp that the row was inserted, updated, or deleted on the source system |
| EXISTING_TIMESTAMP | DATE | The current timestamp of the row in the target database. This applies only if the SP_OPO_LOG_CONFLICT parameter is set to 2, which directs Post to query the target database to get this value. |
| PRIMARY_KEYS | VARCHAR2(4000) | The names of the primary key columns |
| MESSAGE | VARCHAR2(400) |
A message that states which row won in the conflict. The row that wins depends on which conflict resolution routine was used. For example, the following message is returned when the !MostRecentRecord routine is used and the most recent record is the source record: Incoming timestamp > existing timestamp. Incoming wins, overwrite existing. If the target record was the most recent one or has the same timestamp as the source record, then the message would be: Incoming timestamp <= existing timestamp. Existing wins, discard incoming. |
| SQL_STATEMENT | LONG | The final SQL statement that got executed as a result of the conflict resolution |
| CONFLICT_CHECKED | VARCHAR2(1) | Indicates whether or not someone reviewed the conflict. The default is N for No. The person who reviews the conflict can change this value to Y. |
These instructions show you how to set up cascading replication, also known as multi-tiered replication. This strategy replicates data from a source system to an intermediary system, and then from the intermediary system to one or more remote target systems.
Cascading replication can be used to support various replication objectives as a workaround in such conditions as the following:
To use a cascading strategy, the source machine must be able to resolve the final target machine name(s), although the ability to make a direct connection is not required.
Oracle
Oracle
Oracle and Open Target (final target)
This replication strategy supports the following:
Prepare the system, install SharePlex, and configure database accounts according to the instructions in the SharePlex Installation Guide.
Important! Create the same SharePlex user on all systems if you will be using SharePlex to post to a database on the intermediary system.
Disable triggers that perform DML on the target objects.
If sequences are unnecessary on the target system, do not replicate them. It can slow down replication. Even if a sequence is used to generate keys in a source table, the sequence values are part of the key columns when the replicated rows are inserted on the target system. The sequence itself does not have to be replicated.
DDL replication from source to target through an intermediary system is supported in accordance with the information found in the DDL that SharePlex supports chapter of the Administration Guide, with the following exceptions:
Important! These instructions assume you have a full understanding of SharePlex configuration files. They use abbreviated representations of important syntax elements. For more information, see Configure data replication.
In the configuration syntax in this topic, the placeholders represent the following:
Important!
To cascade data, you have the following options:
If there is a database on the intermediary system, you can configure SharePlex to post to that database and then capture the data again to replicate it to one or more remote targets.
If there is not a database on the intermediary system, you can configure SharePlex to import, queue, and then export the data to one or more remote targets. There is no Capture process on the system. This is known as a pass-through configuration. It passes the data directly from the source system to the target(s).
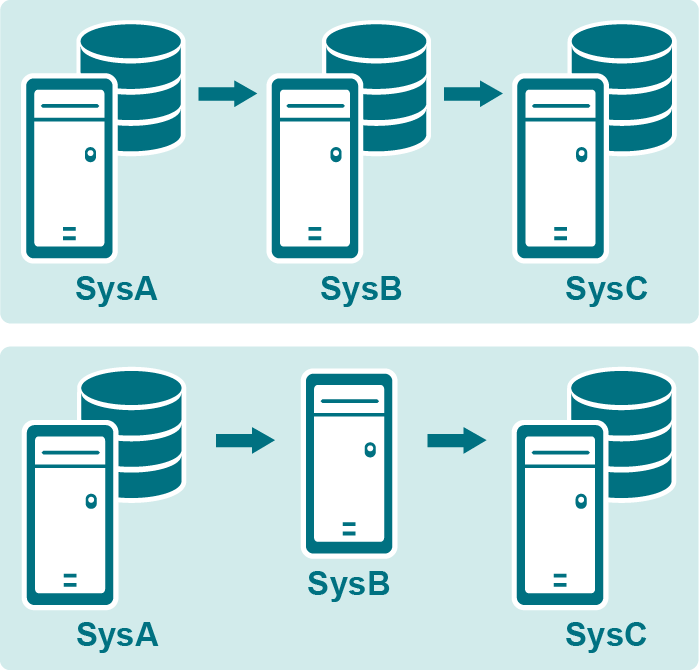
To use this configuration:
Oracle DDL replication is not supported from an Oracle database on the intermediary system to the target systems. It is supported only from the source system to the intermediary system.
Enable archive logging on the source and intermediary systems in case the redo logs wrap before Capture is finished with them.
This configuration replicates from the source system to the database on the intermediary system.
Note: In this template, hostB is the intermediary system.
|
datasource_specification |
||
| source_specification1 | target_specification1 | hostB@o.SID |
| source_specification2 | target_specification2 | hostB@o.SID |
| Datasource:o.oraA | ||
| hr.emp | hr.emp2 | hostB@o.oraB |
| hr.sal | hr.sal2 | hostB@o.oraB |
| cust.% | cust.% | hostB@o.oraB |
Note: In this same configuration, you could route data from other source objects directly to other targets, without cascading through the intermediary system. Just specify the appropriate routing on a separate line.
This configuration captures the data from the database on the intermediary system, then replicates it to the target system(s). The tables that were the target tables in the source configuration are the source tables in this configuration. The target can be any supported SharePlex target.
|
datasource_specification |
||
| source_specification1 | target_specification1 | hostC[@db][+...] |
| source_specification2 | target_specification2 | hostD[@db][+...] |
| Datasource:o.oraB | ||
| hr.emp | hr.emp2 | hostC@o.oraC |
| hr.sal | hr.sal2 | hostD@o.oraD+hostE@r.mssE |
| cust.% | cust.% | !cust_partitions |
Note: The last entry in this example shows the use of horizontally partitioned replication to distribute different data from the sales.accounts table to different regional databases. For more information, see Configure horizontally partitioned replication.
(Oracle intermediary database) Set the SP_OCT_REPLICATE_POSTER parameter to 1 if the intermediary database is Oracle. This instructs the Capture process on the intermediary system to capture the changes posted by SharePlex and replicate them to the target system. (The default is 0, meaning that Capture ignores Post activity on the same system.)
In sp_ctrl, issue the following command. The change takes effect the next time Capture starts.
set param SP_OCT_REPLICATE_POSTER 1
To use this configuration:
Create an Oracle instance and an ORACLE_SID specification in the oratab file (Unix and Linux systems) or the Windows Registry. The database can be empty.
DDL replication is not supported.
Note: In this template, hostB is the intermediary system.
|
datasource_specification | ||
| source_specification1 | target_specification1 | hostB*hostC[@db] |
| source_specification2 | target_specification2 | hostB*hostD[@db][+hostB*hostE[@db][+...] |
| source_specification3 | target_specification3 | hostB*hostX[@db]+hostY[@db] |
| Datasource:o.oraA | ||
| hr.emp | hr.emp2 | hostB*hostC@o.oraC |
| hr.emp | hr."Emp_3" | hostB*hostC@r.mssB |
| cust.% | cust.% | hostB*hostD@o.oraD+hostE@o.oraE |
These instructions show you how to set up SharePlex for the purpose of high availability: replicating to a secondary Oracle database that is a mirror of the source database. This strategy uses bi-directional replication with two SharePlex configurations that are the reverse of each other. The configuration on the secondary (standby) machine remains in an activated state with the Export process on that system stopped in readiness for failover if the primary machine fails.
This strategy supports business requirements such as the following:
In this strategy, SharePlex operates as follows:
Oracle
Oracle
This replication strategy supports the use of named export and post queues.
Note: Column mapping and partitioned replication is not appropriate in a high availability configuration. Source and target objects can have different names but this makes the management of a high-availability structure more complicated.
Enable archive logging on all systems.
For failover purposes, the following are required:
Note: If you use an Oracle hot backup to create the secondary instance, keep the script. It can be modified to re-create the primary instance.
In the configuration syntax in this topic, the placeholders represent the following:
hostA is the primary system.
Important!
A high availability configuration uses two configurations that are the reverse of each other. To replicate all objects in the database, you can use the config.sql script to simplify the configuration process. For more information, see Configuration Scripts.
|
Datasource:o.oraA |
||
| ownerA.object | ownerB.object | hostB@o.oraB |
|
Datasource:o.oraB |
||
| ownerB.object | ownerA.object | hostA@o.oraA |
If a system fails in your high-availability environment, you can move replication to a secondary system and then move it back to the primary system when it is restored. For more information, see Recover replication after Oracle failover .
This chapter contains the information that you need to know in order to replicate Oracle DDL operations that are supported by SharePlex.
