この章では、水平パーティン化レプリケーションと垂直分割レプリケーションといったSharePlexの高度な設定オプションの使用方法を説明します。これらのオプションによって、特定の要件を満たすためにデータを分割、並列化、フィルタリングするための高いレベルの柔軟性が実現されます。先に進む前に、設定ファイルの作成に関わる概念とプロセスを確実に理解してください。
水平分割レプリケーションを使用して、テーブルの行を個別の処理ストリームに分割します。以下を実行するために、水平分割レプリケーションを使用できます。
PostgreSQLからPostgreSQL、Oracle、SQL Server、Kafkaへ
Oracleから全ターゲットへ
サービスとしてのPGDBからサービスとしてのPGDBへ
サービスとしてのPGDBからOracleへ
サービスとしてのPGDBからPostgreSQLへ
テーブルの水平分割レプリケーションを設定する手順は以下の通りです。
行パーティションを定義し、それらをパーティションスキーム にリンクします。
行パーティションは、グループとしてレプリケートするソーステーブルの行のサブセットです。
パーティションスキームは、行パーティションの論理コンテナです
パーティションスキームの行パーティションは、以下のいずれかに基づくことができます。
列条件に基づく行パーティションは、次の目的で使用できます。
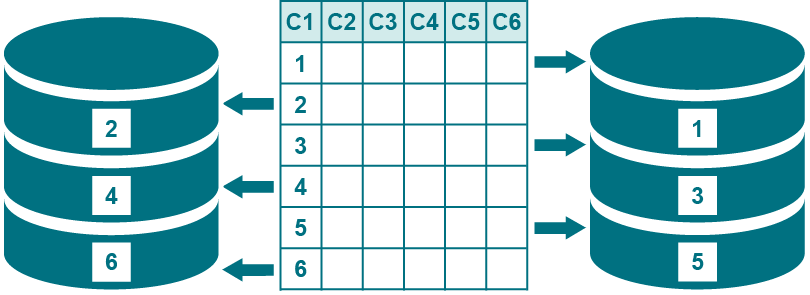
複数の行パーティションを使用してテーブルの行を分割し、行の各セットが異なるターゲットにレプリケートされるようにします。例えば、CORPORATE.SALESという名前のテーブルに、「East」と「West」という2つの行パーティションがあるとします。それに応じて列条件が定義され、REGION = EASTを満たす行は1つの場所にレプリケートされ、REGION = WESTを満たす行は別の場所にレプリケートされます。例えば、パーティションスキームに「Sales_by_region」という名前を付けることができます。
複数の行パーティションを使用して、テーブルの行を並列処理ストリーム(並列のExport、Import、Postストリーム)に分割し、ターゲットテーブルへのポストを高速化します。例えば、頻繁に更新されるターゲットテーブルへのレプリケーションのフローを改善することができます。この目的での列条件の使用は、並列Postプロセスに均等に処理を振り分けることができる列がテーブルに含まれている場合にのみ適切です。
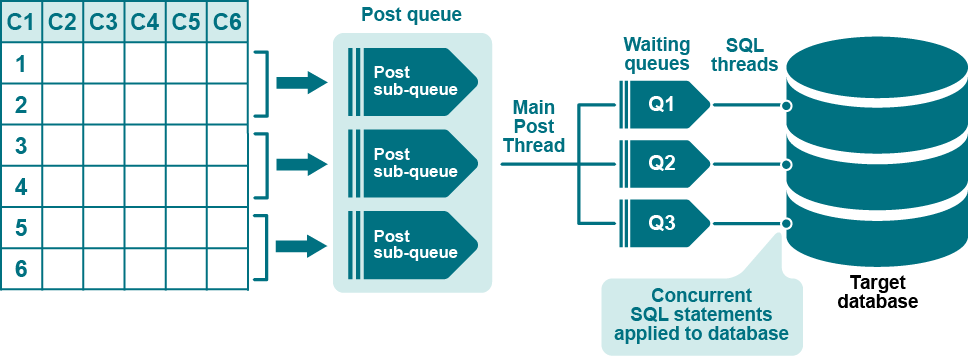
ハッシュ値に基づいた行パーティションを使用して、テーブルの行を並列処理ストリーム(並列のExport、Import、Post)に分割し、ターゲットテーブルへのポストを高速化できます。パーティションの作成に列条件ではなくハッシュ値を使用する利点は、WHERE句でテーブルの列を参照する必要がなく、SharePlexによって行が自動的に均等に分割されることです。しかし、列ベースのパーティションスキームとは異なり、ハッシュベースのパーティションスキームには、SharePlexcompareコマンドやrepairコマンドを使用できません。
水平分割レプリケーションと垂直分割レプリケーションを組み合わせることで、情報の配布方法を最大限に制御できます。
次などを考慮します。
水平分割レプリケーションは、同じテーブルのフルテーブルレプリケーションと組み合わせて使用することができます。例えば、行のグループを異なるレポートシステムにルーティングし、すべての行をバックアップシステムにルーティングすることができます。
ハッシュベースのパーティション化は、以下をサポートしていません。
ハッシュベースのパーティション化は、行を別のパーティションに移行させるような操作もサポートしていません。そのような操作には以下のような例があります。
add partitionコマンドを使用して行パーティションを作成し、パーティションスキームに割り当てます。
列条件に基づいて行をパーティション化するには
特定のパーティションスキームで作成する行パーティションごとに、add partitionを発行します。最初の行パーティションを作成するとき、SharePlexはパーティションスキームも作成します。
sp_ctrl> add partition to scheme_name setcondition = column_condition and route = routing_map [and name = name] [and tablename =owner.table] [and description =description]
ハッシュ値に基づいて行をパーティション化するには
add partitionを1回発行して、作成するハッシュパーティションの数を指定します。
sp_ctrl> add partition to scheme_name set hash = value and route = value
注意: add partitionをto scheme_nameおよびsetキーワードと共に指定した後は、他のすべてのコンポーネントはどのような順序でも構いません。
| コンポーネント | 説明 |
|---|---|
| to scheme_name |
toは、行パーティションがscheme_nameに追加されることを示す必須キーワードです。 scheme_nameはパーティションスキームの名前です。パーティションスキームは、最初に発行するadd partitionコマンドによって作成されます。このコマンドは、パーティション化する最初の行のセットも指定します。 水平分割を多用する場合は、パーティションスキームの命名規則を確立しておくことをお勧めします。 |
|
set |
行パーティションの定義を開始する必須キーワード。 |
| condition = column_condition |
列条件に基づいて行パーティションを作成します。条件は引用符で囲む必要があります。((region_id = West) and region_id is not null)のような標準的なWHERE条件構文を使用します。 conditionコンポーネントとhashコンポーネントは相互に排他的です。 |
| hash = value |
ハッシュ値に基づいて行パーティションを作成します。指定された値は、パーティションスキームにおける行パーティションの数を決定します。 conditionコンポーネントとhashコンポーネントは相互に排他的です。 |
| route = routing_map |
このパーティションのルート。これは以下のいずれかになります。 列条件に基づくパーティション: 標準のSharePlexルーティングマップを指定します(例: sysB@o.myora、sysB:q1@o.myoraまたはsysB@o.myora+sysC@o.myora(複合ルーティングマップ))。 ターゲットがJMS、Kafka、またはファイルの場合、ターゲットをx.jms、x.kafka、またはx.fileとして指定する必要があります(例: sysA:hpq1@x.kafka)。 異なる名前を持つ複数のターゲットテーブルにパーティションをルーティングするには、以下の手順を実行します。
ハッシュに基づくパーティション: 以下のフォーマットを使用して、各パーティションに名前付きpostキューを作成するようにSharePlexに指示します。 host:basename|#{o.SID | r.database} ここで
|
| name = name |
(推奨)このパーティションの短い名前。このオプションは、列条件に基づくパーティションにのみ有効です。名前を付けておくと、将来パーティションを変更したり削除したりする必要が生じたときに、長い列の条件を入力する必要がなくなります。 |
| tablename = owner.table |
(オプション)このオプションは、ターゲットテーブルが複数あり、そのうちの1つ以上が異なる名前である場合に使用します。名前ごとにadd partitionコマンドを個別に発行します。 テーブル名は完全修飾名でなければなりません。大文字と小文字が区別される場合は、名前を引用符で囲んで指定する必要があります。 例: add partition to scheme1 set name = p1 and condition = "C1 > 200" and route = sysb:p1@o.orasid and tablename = myschema.mytable |
| description = description | (オプション) このパーティションの説明。 |
異なる行のセットを異なるpostキューにルーティング:
sp_ctrl> add partition to scheme1 set name = q1 and condition = "C1 >= 200" and route = sysb:q1@o.orasid
sp_ctrl> add partition to scheme1 set name = q2 and condition = "C1 < 200" and route = sysb:q2@o.orasid
異なる行のセットを、異なるターゲットシステムおよびソースと異なるテーブル名にルーティング:
sp_ctrl> add partition to scheme1 set name = east and condition = "area = east" and route = sys1e@o.orasid and tablename = ora1.targ
sp_ctrl> add partition to scheme1 set name = west and condition = "area = west" and route = sys2w@o.orasid and tablename = ora2.targ
行を4つのパーティションに分け、それぞれを異なるpostキューで処理します。
sp_ctrl> add partition to scheme1 set hash = 4 and route = sysb:hash|#@o.ora112
以下に、列条件を作成するためのガイドラインを示します。このガイドラインは、ハッシュ値を使用して作成する行パーティションには適用されません。
列条件のベースになる列の種類は、データソースによって異なります。
PRIMARYキー列やUNIQUEキー列など、列条件は値が変更されない列に基づく必要があります。これは、パーティションシフトを回避するためです。パーティションシフトは、パーティションの条件列に加えられた変更により、基礎となるデータが別のパーティションの条件を満たす、またはどのパーティションの条件も満たさなくなることです。
パーティションシフトのケース1: 列の値が更新され、新しい値がどの列の条件も満たさなくなります。
パーティションシフトのケース2: ある列の条件を満たす行が更新され、別の条件を満たすようになります。
列条件の値の変更によって生じた非同期行は、以下の方法を使用して修復できます。
さらに、設定ファイルをアクティブにする前に、ソースで以下のパラメータを設定することで、データが正しくレプリケートされることを確認できます。
注意: キー以外の列を列条件のベースとして使用しており、水平分割レプリケーションが有効な状態でパフォーマンスの低下に気づいた場合は、その列のロググループを追加してください。
SharePlexは、列条件で以下のデータ型をサポートしています。
注意:
|
次のリストは、SharePlexが列条件でサポートしている条件構文を示しています。
|
column = value
not (column = value)
column > value
value > column
column < value
column <= value
column >= value
column <> value
column != value
column like value
column between value1 and value2
not (column between value1 and value2 )
column is null
column is not null |
条件は、括弧とAND、OR、NOTの論理接続子を使用して入れ子式に組み合わせることができます。
禁止事項:
フルテーブルレプリケーションを使用するテーブルと分割レプリケーションを使用するテーブルを含め、指定したデータソースからレプリケートするすべてのデータに対して1つの設定ファイルを使用します。
| Datasource:o.SID | ||
| src_owner.table | tgt_owner.table |
!partition_scheme |
| ! | routing_map | |
| コンポーネント | 説明 | |
|---|---|---|
|
o.database |
データソースの指定。Oracleソースにはo.表記を、データベースの場合、ORACLE_SID | |
| src_owner.tableおよびtgt_owner.table | ソース側のテーブルとターゲット側のテーブルのそれぞれの指定。 | |
| !partition_scheme |
指定されたソーステーブルとターゲットテーブルで使用するパーティションスキームの名前。!は必須です。名前は大文字と小文字が区別されます。!schemeA+schemeBなど、複数のパーティションスキームの複合ルーティングはサポートされていません。 同じソーステーブルに使用するパーティションスキームごとに個別のエントリを作成します。例を参照してください。 | |
| ! routing_map |
プレースホルダ・ルーティング・マップ 。パーティションスキームで使用したルートが、設定ファイルのどこにもリストされていない場合にのみ必要です。SharePlexでは、パーティションスキームにリストされている場合でも、すべてのルートが設定ファイルに記述されている必要があります。
例を参照してください。 |
| Datasource: o.mydb | ||
| scott.emp | scott.emp_2 | !partition_emp |
| Datasource: o.mydb | ||
| scott.emp | scott.emp_2 | !partition_schemeA |
| scott.emp | scott.emp_3 | !partition_schemeB |
| ! targsys1 |
| ! targsys2@o.ora2+targsys3@o.ora3 |
このプレースホルダは列条件に基づくパーティションにのみ必要です。
view partitionsコマンドを使用して、水平分割レプリケーション設定内の1つのパーティションスキームまたはすべてのパーティションスキームの行パーティションを表示します。
行パーティションを表示するには
すべてのパーティションを表示するか、特定のパーティションスキームのパーティションだけを表示するかによって、次のコマンドでいずれかのオプションを指定して実行します。
sp_ctrl> view partitions for {scheme_name | all}
次の例は、ハッシュベースのパーティションスキームと列ベースのパーティションスキームの両方を示しています。
sp_ctrl> view partitions all
Scheme Name Route Hash Condition ----------- ------------- ------------------------------ ------ --------------- HASH4 hash sys02:hash|#@o.ora112 4 ROWID TEST_CT highvalues sys02:highvalues@o.ora112 sales>=10000 TEST_CT lowvalues sys02:lowvalues@o.ora112 sales<10000
パーティションのpostキューを表示するには
ターゲット上でqstatusコマンドを実行すると、水平分割レプリケーションに関連付けられたpostキューが表示されます。
sp_ctrl sys02>
Queues Statistics for sys02
Name: highvalues (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: lowvalues (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Queues Statistics for sys02
Name: hash1 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash2 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash3 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash4 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
パーティションスキームを管理するために、以下のコマンドまたはパラメータを使用できます。詳細については、『SharePlexリファレンスガイド』を参照してください。
|
タスク |
コマンド/パラメーター |
説明 |
|---|---|---|
|
パーティションを変更 |
modify partitionコマンド |
行パーティション定義の属性を変更します。 |
|
パーティションスキームを削除 |
drop partition schemeコマンド |
パーティションスキームとその中のすべての行パーティションを削除します。 |
|
ハッシュアルゴリズムの変更 |
SP_OCF_HASH_BY_BLOCK |
ハッシュアルゴリズムをデフォルトの行IDベースからブロックベースに変更します。ブロックベースのアルゴリズムを有効にするには1に設定します。 |
PostgreSQL、Oracle、SQL Server、Kafka
|
注意:
|
テーブルの水平分割レプリケーションを設定する手順は以下の通りです。
行パーティションを定義し、それらをパーティションスキーム にリンクします。
行パーティションは、グループとしてレプリケートするソーステーブルの行のサブセットです。
パーティションスキームは、行パーティションの論理コンテナです
列条件に基づく行パーティションは、次の目的で使用できます。
複数の行パーティションを使用してテーブルの行を分割し、行の各セットが異なるターゲットにレプリケートされるようにします。例えば、CORPORATE.SALESという名前のテーブルに、「East」と「West」という2つの行パーティションがあるとします。それに応じて列条件が定義され、REGION = EASTを満たす行は1つの場所にレプリケートされ、REGION = WESTを満たす行は別の場所にレプリケートされます。例えば、パーティションスキームに「Sales_by_region」という名前を付けることができます。
複数の行パーティションを使用して、テーブルの行を並列処理ストリーム(並列のExport、Import、Postストリーム)に分割し、ターゲットテーブルへのポストを高速化します。例えば、頻繁に更新されるターゲットテーブルへのレプリケーションのフローを改善することができます。この目的での列条件の使用は、並列Postプロセスに均等に処理を振り分けることができる列(プライマリキーまたは非nullの一意のキーの使用を推奨)がテーブルに含まれている場合にのみ適切です。
水平分割レプリケーションと垂直分割レプリケーションを組み合わせることで、情報の配布方法を最大限に制御できます。
次などを考慮します。
水平分割レプリケーションは、同じテーブルのフルテーブルレプリケーションと組み合わせて使用することができます。例えば、行のグループを異なるレポートシステムにルーティングし、すべての行をバックアップシステムにルーティングすることができます。
add partitionコマンドを使用して行パーティションを作成し、パーティションスキームに割り当てます。
列条件に基づいて行をパーティション化するには
特定のパーティションスキームで作成する行パーティションごとに、add partitionを発行します。最初の行パーティションを作成するとき、SharePlexはパーティションスキームも作成します。
sp_ctrl> add partition to scheme_name setcondition = column_condition and route = routing_map [and name = name] [and tablename =schema.table] [and description =description]
注意: add partitionをto scheme_nameおよびsetキーワードと共に指定した後は、他のすべてのコンポーネントはどのような順序でも構いません。
| コンポーネント | 説明 |
|---|---|
| to scheme_name |
toは、行パーティションがscheme_nameに追加されることを示す必須キーワードです。 scheme_nameはパーティションスキームの名前です。パーティションスキームは、最初に発行するadd partitionコマンドによって作成されます。このコマンドは、パーティション化する最初の行のセットも指定します。 水平分割を多用する場合は、パーティションスキームの命名規則を確立しておくことをお勧めします。 |
|
set |
行パーティションの定義を開始する必須キーワード。 |
| condition = column_condition |
列条件に基づいて行パーティションを作成します。条件は引用符で囲む必要があります。((region_id = West) and region_id is not null)のような標準的なWHERE条件構文を使用します。 |
| route = routing_map |
このパーティションのルート。これは以下のいずれかになります。 列条件に基づくパーティション: 標準のSharePlexルーティングマップを指定します。例: sysB@r.dbnameまたはsysB:q1@r.dbnameまたはsysB@r.dbname+sysC@r.dbname(複合ルーティングマップ)。 異なる名前を持つ複数のターゲットテーブルにパーティションをルーティングするには、以下の手順を実行します。
|
| name = name |
(推奨)このパーティションの短い名前。このオプションは、列条件に基づくパーティションにのみ有効です。名前を付けておくと、将来パーティションを変更したり削除したりする必要が生じたときに、長い列の条件を入力する必要がなくなります。 |
| tablename = schemaname.table |
(オプション)このオプションは、ターゲットテーブルが複数あり、そのうちの1つ以上が異なる名前である場合に使用します。名前ごとにadd partitionコマンドを個別に発行します。 テーブル名は完全修飾名でなければなりません。大文字と小文字が区別される場合は、名前を引用符で囲んで指定する必要があります。 例: add partition to scheme1 set name = p1 and condition = "C1 > 200" and route = sysb:p1@r.dbname and tablename = myschema.mytable |
| description = description | (オプション) このパーティションの説明。 |
異なる行のセットを異なるpostキューにルーティング:
sp_ctrl> add partition to scheme1 set name = q1 and condition = "C1 >= 200" and route = sysb:q1@r.dbname
sp_ctrl> add partition to scheme1 set name = q2 and condition = "C1 < 200" and route = sysb:q2@r.dbname
異なる行のセットを、異なるターゲットシステムおよびソースと異なるテーブル名にルーティング:
sp_ctrl> add partition to scheme1 set name = east and condition = "area = east" and route = sys1e@r.dbname and tablename = schema1.targ
sp_ctrl> add partition to scheme1 set name = west and condition = "area = west" and route = sys2w@r.dbname and tablename = schema2.targ
以下に、列条件を作成するためのガイドラインを示します。
列条件のベースになる列の種類は、データソースによって異なります。
PRIMARYキー列やUNIQUE キー列など、列条件は値が変更されない列に基づく必要があります。これは、パーティションシフトを回避するためです。パーティションシフトは、パーティションの条件列に加えられた変更により、基礎となるデータが別のパーティションの条件を満たす、またはどのパーティションの条件も満たさなくなることです。
パーティションシフトのケース1: 列の値が更新され、新しい値がどの列の条件も満たさなくなります。
パーティションシフトのケース2: ある列の条件を満たす行が更新され、別の条件を満たすようになります。
さらに、設定ファイルをアクティブにする前に、ソースで以下のパラメータを設定することで、データが正しくレプリケートされることを確認できます。
注意: キー以外の列を列条件のベースとして使用しており、水平分割レプリケーションが有効な状態でパフォーマンスの低下に気づいた場合は、その列のロググループを追加してください。PostgreSQLでは、レプリカアイデンティティにFULLを設定して、このパラメータを使用できます。
SharePlexは、列条件で以下のデータ型をサポートしています。
SMALLINT
INT
BIGINT
NUMERIC
CHAR(長さ2000以下)
VARCHAR(長さ1<=4000)
DATE
BOOLEAN(condition = "column_name =1" or condition = "column_name = 0")
注意:
|
次のリストは、SharePlexが列条件でサポートしている条件構文を示しています。
|
column = value
not (column = value)
column > value
value > column
column < value
column <= value
column >= value
column <> value
column != value
column like value
column between value1 and value2
not (column between value1 and value2 )
column is null
column is not null |
条件は、括弧とAND、OR、NOTの論理接続子を使用して入れ子式に組み合わせることができます。
禁止事項:
フルテーブルレプリケーションを使用するテーブルと分割レプリケーションを使用するテーブルを含め、指定したデータソースからレプリケートするすべてのデータに対して1つの設定ファイルを使用します。
| Datasource:r.dbname | ||
| srcschemaname.table | targetschemaname.table |
!partition_scheme |
| ! | routing_map | |
| コンポーネント | 説明 | |
|---|---|---|
|
r.dbname |
データソースの指定。PostgreSQLソースにはr.表記を使用します。 | |
| src_schema.tableおよびtgt_schema.table | ソース側のテーブルとターゲット側のテーブルのそれぞれの指定。 | |
| !partition_scheme |
指定されたソーステーブルとターゲットテーブルで使用するパーティションスキームの名前。!は必須です。名前は大文字と小文字が区別されます。!schemeA+schemeBなど、複数のパーティションスキームの複合ルーティングはサポートされていません。 同じソーステーブルに使用するパーティションスキームごとに個別のエントリを作成します。例を参照してください。 | |
| ! routing_map |
プレースホルダ・ルーティング・マップ 。パーティションスキームで使用したルートが、設定ファイルのどこにもリストされていない場合にのみ必要です。SharePlexでは、パーティションスキームにリストされている場合でも、すべてのルートが設定ファイルに記述されている必要があります。
|
パーティションスキームを指定するには
| Datasource: r.mydb | ||
| scott.emp | scott.emp_2 | !partition_emp |
同じソーステーブルに複数のパーティションスキームを指定するには
| Datasource: r.mydb | ||
| scott.emp | scott.emp_2 | !partition_schemeA |
| scott.emp | scott.emp_3 | !partition_schemeB |
プレースホルダ・ルーティング・マップを指定するには
| ! targsys1 |
| ! targsys2@r.dbname2+targsys3@r.dbname3 |
このプレースホルダは列条件に基づくパーティションにのみ必要です。
view partitionsコマンドを使用して、水平分割レプリケーション設定内の1つのパーティションスキームまたはすべてのパーティションスキームの行パーティションを表示します。
行パーティションを表示するには
すべてのパーティションを表示するか、特定のパーティションスキームのパーティションだけを表示するかによって、次のコマンドでいずれかのオプションを指定して実行します。
sp_ctrl>view partitions for {scheme_name | all}
次の例は、列ベースのパーティションスキームを示しています。
sp_ctrl> view partitions all
| Scheme | Name | Route | Tablename | Condition |
|---|---|---|---|---|
| product | lessQuantity | 10.250.40.27@r.testdb | splex.prod_1 | id between 1 and 100 |
| product | moreQuantity | 10.250.40.27@r.testdb | splex.prod_2 | id between 101 and 200 |
| product | largeQuantity | 10.250.40.27@r.testdb | splex.prod_3 | id between 201 and 300 |
| sales_by_region | east | 10.250.40.27@r.testdb | splex.sales_dst1 | ((region = 'East') and region is not null) |
| sales_by_region | west | 10.250.40.27@r.testdb | splex.sales_dst2 | ((region = 'west') and region is not null) |
| city_scheme | Pune | 10.250.40.27:pune_queue@r.testdb | splex.student_target1 | ((stud_name = 'Pune') and stud_name is not null) |
| city_scheme | Mumbai | 10.250.40.24:mumbai_queue@r.testdb | splex.student_target2 | ((stud_name = 'Mumbai') and stud_name is not null) |
city_scheme column-based partition scheme
パーティションのpostキューを表示するには
ターゲット上でqstatusコマンドを実行すると、水平分割レプリケーションに関連付けられたpostキューが表示されます。
sp_ctrl (pslinuxpgsp11:2200)> qstatus
Queues Statistics for pslinuxpgsp11
Name: pune_queue (r.testdb-r.testdb) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)sp_ctrl (pslinuxpgsp08:2200)> qstatus
Queues Statistics for pslinuxpgsp08
Name: mumbai_queue (r.testdb-r.testdb) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
パーティションスキームを管理するために、以下のコマンドまたはパラメータを使用できます。詳細については、『SharePlexリファレンスガイド』を参照してください。
|
タスク |
コマンド/パラメーター |
説明 |
|---|---|---|
|
パーティションを変更 |
modify partitionコマンド |
行パーティション定義の属性を変更します。 |
|
パーティションスキームを削除 |
drop partition schemeコマンド |
パーティションスキームとその中のすべての行パーティションを削除します。 |
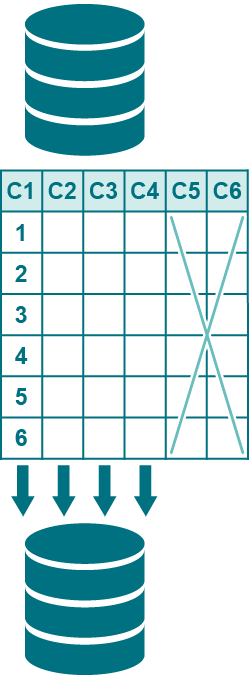
テーブルの垂直分割レプリケーションは、列のサブセットをレプリケートする場合に使用します。例えば図に示すように、C1、C2、C3、C4に加えられたデータの変更はレプリケートできますが、C5とC6に加えられた変更はレプリケートできません。
PostgreSQLからPostgreSQL、Oracle、SQL Server、Kafkaへ
Oracleから全ターゲットへ
サービスとしてのPGDBからサービスとしてのPGDBへ
サービスとしてのPGDBからOracleへ
サービスとしてのPGDBからPostgreSQLへ
垂直分割レプリケーションを含む設定ファイルを作成する場合は、以下のガイドラインに従ってください。
垂直分割レプリケーションは、レポート作成やその他のデータ共有戦略には適していますが、高可用性環境には適していません。テーブルを垂直分割レプリケーション用に設定すると、SharePlexはその他の列を認識しないため、これらの列のデータはレプリケートされません。
水平分割レプリケーションと垂直分割レプリケーションを組み合わせることで、配布する情報を最大限に制御できます。
例: ある会社には本社と地域部門があり、本社が企業データベースを、各地域が地域データベースを管理しています。本社は、垂直分割レプリケーションを使用して、テーブルの列データの一部をこれらの地域拠点と共有し、その他の機密データは本社で保持しています。共有された列に加えられた行の変更は、さらに水平分割され、該当する地域のデータベースにレプリケートされます。
垂直分割レプリケーションを構成するには、列パーティションまたは除外列パーティションのいずれかを設定ファイルで指定します。
どちらのタイプの列パーティションを指定する場合も、以下の規則に従ってください。
垂直分割レプリケーションのエントリを設定するには、以下の構文を使用します。設定ファイルの作成方法の詳細については、「データをレプリケートするためのSharePlexの設定」を参照してください。
| datasource_specification | ||
|
#列パーティションを使用したテーブルの指定 | ||
|
src_owner.table (src_col,src_col,...) |
tgt_owner.table [(tgt_col,tgt_col,...)]。 | routing_map |
|
#除外列パーティションを使用したテーブルの指定 | ||
| src_owner.table !(src_col,src_col,...) | tgt_owner.table | routing_map |
| 設定のコンポーネント | 説明 |
|---|---|
| src_owner.tableおよびtgt_owner.table | ソース側のテーブルとターゲット側のテーブルのそれぞれの指定。 |
|
(src_col, src_col,...) |
レプリケーションに含める列をリストした列パーティションを指定します。レプリケーション開始後に追加された列のデータも含め、他の列のデータはレプリケートされません(DDLレプリケーションが有効になっていると仮定)。 |
|
!(src_col,src_col,...) |
レプリケーションから除外する列をリストする除外列パーティションを指定します。レプリケーション開始後に追加された列のデータも含め、その他の列のデータはすべてレプリケートされます(DDLレプリケーションが有効になっていると仮定)。 注: 除外列パーティションを使用する場合、対応するソース側の列名とターゲット側の列名は同一でなければならず、除外列をキー定義で使用することはできません。詳細については、「一意キーの定義 」を参照してください。 |
| (tgt_col,tgt_col,...) |
ターゲット側の列。このオプションを使用して、異なる所有者や名前を持つソース側の列をターゲット側の列にマッピングします。ソース側の列とターゲット側の列の所有者または名前が同じ場合は、ターゲット側の列を省略することができます。 ソース側の列をターゲット側の列にマッピングするには、以下の規則に従います。
|
| routing_map |
列パーティションのルーティングマップ。ルーティングマップは以下のいずれかにできます。
重要! 設定ファイルにはソース側のテーブルごとに1つの列条件のみをリストできます。このため、複数のターゲットを個別のエントリに記載するのではなく、複合ルーティングマップを使用する必要があります。複合ルーティングマップを使用するには、すべてのターゲット側のテーブルの所有者と名前が同じでなければなりません。詳細については、設定ファイル内のルーティング指定を参照してください。 |
複合ルーティングマップを使用して複数のターゲットにレプリケートする垂直分割レプリケーションの設定を次に示します。このソース側のテーブルに複合ルーティングマップを使用するには、すべてのターゲットの名前をscott.salにしなければなりません。
| Datasourceo.oraA | ||
| scott.emp (c1,c2) | scott.sal |
sysB@o.oraB+sysC@o.oraC |
以下は、単一のターゲットにレプリケートする垂直分割レプリケーションの設定で、ターゲット側の列はソース側の列とは異なる名前を持っています。
| Datasourceo.oraA | ||
| scott.emp (c1,c2) | scott.sal (c5,c6) |
sysB@o.oraB |
scott.emp (c1, c2)の同じ列パーティションを設定ファイル内で2回繰り返しているため、以下の設定ファイルは有効ではありません。
| Datasourceo.oraA | ||
| scott.emp (c1,c2) | scott.cust (c1,c2) |
sysB@o.oraB |
| scott.emp (c1,c2) | scott.sales (c1,c2) | sysC@o.oraC |
PostgreSQL、Oracle、SQL Server、Kafka
注: PostgreSQLからSQLサーバへのレプリケーションは、垂直分割データのBOOLEAN、TIME、TIME WITH TIME ZONE、およびBYTEAデータ型をサポートしていません。
垂直分割レプリケーションを設定するには:
垂直分割レプリケーションを構成するには、列パーティションまたは除外列パーティションのいずれかを設定ファイルで指定します。
どちらのタイプの列パーティションを指定する場合も、以下の規則に従ってください。
垂直分割レプリケーションのエントリを設定するには、以下の構文を使用します。
| datasource_specification | ||
|
#列パーティションを使用したテーブルの指定 | ||
|
src_schema.table (src_col,src_col,...) |
tgt_schema.table [(tgt_col,tgt_col,...)] | routing_map |
|
#除外列パーティションを使用したテーブルの指定 | ||
| src_schema.table !(src_col,src_col,...) | tgt_schema.table | routing_map |
| 設定のコンポーネント | 説明 |
|---|---|
| src_schema.tableおよびtgt_schema.table | ソース側のテーブルとターゲット側のテーブルのそれぞれの指定。 |
| (tgt_col,tgt_col,...) |
ターゲット側の列。このオプションを使用して、異なるスキーマや名前を持つソース側の列をターゲット側の列にマッピングします。ソース側の列とターゲット側の列のスキーマや名前が同じ場合は、ターゲット側の列を省略することができます。 ソース側の列をターゲット側の列にマッピングするには、以下の規則に従います。
|
| routing_map |
列パーティションのルーティングマップ。ルーティングマップは以下のいずれかにできます。
重要! 設定ファイルにはソース側のテーブルごとに1つの列条件のみをリストできます。このため、複数のターゲットを個別のエントリに記載するのではなく、複合ルーティングマップを使用する必要があります。複合ルーティングマップを使用するには、すべてのターゲット側のテーブルのスキーマと名前が同じでなければなりません。 |
複合ルーティングマップを使用して複数のターゲットにレプリケートする垂直分割レプリケーションの設定を次に示します。このソース側のテーブルに複合ルーティングマップを使用するには、すべてのターゲットの名前をscott.salにしなければなりません。
| Datasource: r.dbname | ||
| scott.emp (c1,c2) | scott.sal |
sysB@r.dbname1 + sysC@r.dbname2 |
以下は、単一のターゲットにレプリケートする垂直分割レプリケーションの設定で、ターゲット側の列はソース側の列とは異なる名前を持っています。
| Datasource: r.dbname | ||
| scott.emp (c1,c2) | scott.sal (c5,c6) |
sysB@r.dbname1 |
scott.emp (c1, c2)の同じ列パーティションを設定ファイル内で2回繰り返しているため、以下の設定ファイルは有効ではありません。
| Datasource: r.dbname | ||
| scott.emp (c1,c2) | scott.cust (c1,c2) |
sysB@r.dbname1 |
| scott.emp (c1,c2) | scott.cust (c1,c2) | sysC@r.dbname2 |
この章では、変更履歴ターゲットを管理するためにSharePlexを設定する方法について説明します。SharePlexにより、履歴を維持すると同時に、同じデータセットをレプリケートして最新のターゲットを維持することができます。
