The Optimization Criteria are session level settings. Each criteria represents a specific algorithm or relational techniques that the Adaptive Server Optimizer may choose to use when it is retrieving the query plan. They are used to fine-tune the Adaptive Server optimizer to provide the best performance for your database environment.
Although you may specify that Adaptive Server optimizer use a specific algorithm or relational technique, the optimizer may not choose what you have specified.
| Optimization Criteria | Description |
| hash_join | Specify that the Adaptive Server optimizer uses the hash join algorithm. This is valuable when a large number of rows satisfy the join condition or when the joining columns do not have useful indexes. However, the hash join algorithm may consume more run time resources that other join algorithms. |
|
nl_join |
Specify that the Adaptive Server optimizer uses the nested-loop-join algorithm. |
|
merge_join |
Specify that the Adaptive Server optimizer uses the merge join algorithm. This relies on ordered input and is most valuable when the input is ordered on the merge key. |
| Optimization Criteria | Description |
| merge_union_distinct | Specify that the Adaptive Server optimizer uses the merge algorithm for the UNION ALL. It is similar to merge_union_all except that duplicate rows are eliminated. |
|
hash_union_distinct |
Specify that the Adaptive Server optimizer uses the hash distinct algorithm. This will be inefficient if most of the rows are distinct. |
| Optimization Criteria | Description |
| append_union_all | Specify that the Adaptive Server optimizer uses the append union all algorithm. |
|
merge_union_all |
Specify that the Adaptive Server optimizer uses the merge algorithm for the UNION ALL. This means that it will maintain the ordering of the result row from the union input. |
| Optimization Criteria | Description |
|
group_sorted |
Specify that the Adaptive Server optimizer uses an on-the-fly algorithm. This algorithm relies on an input stream sorted on the grouping column and preserves this order in its output. |
|
group_hashing |
Specify that the Adaptive Server optimizer uses the use a group hashing algorithm to process aggregates. |
| Optimization Criteria | Description |
|
distinct_sorted |
Specify that the Adaptive Server optimizer uses a single-pass algorithm to eliminate duplicate rows. This algorithm relies on an ordered input stream. |
|
distinct_sorting |
Specify that the Adaptive Server optimizer uses the sorting algorithm to eliminate duplicate rows. This algorithm is useful when the input is not ordered. |
|
opportunistic_distinct _view |
Specify that the Adaptive Server optimizer uses a more flexible algorithm when enforcing distinctness. |
|
distinct_hashing |
Specify that the Adaptive Server optimizer uses the hashing algorithm to eliminate duplicates, which is very efficient when there are only a few distinct values in comparison to the number of rows. |
| Optimization Criteria | Description |
|
store_index |
Specify that the Adaptive Server optimizer uses the reformatting, which may cause an increase in the number of worktables used. |
|
parallel_query |
Specify that the Adaptive Server optimizer uses parallel query optimization. |
|
index_intersection |
Specify that the Adaptive Server optimizer uses the intersection of multiple index scans as part of the query plan in search space. |
|
multi_table_store_ind |
Specify that the Adaptive Server optimizer uses reformatting on the result of a multiple table join. |
|
bushy_space_search |
Specify that the Adaptive Server optimizer uses bushy-tree-shaped query plans, which may cause an increase in the search space, but may provide more query plan options to improve performance. |
|
advanced_aggregation |
Specify that the Adaptive Server optimizer uses eager aggregation. |
| replicated_partition |
Specify that the Adaptive Server optimizer uses replicated partitioning when multiple scans of the same table in different threads can improve the performance of nested loop joins. |
| group_inserting | Specify that the Adaptive Server optimizer uses the group by aggregation algorithm. This algorithm generates a clustered index work table on the grouping columns and inserts rows into the table in order to evaluate the aggregate. |
Note: The criteria that are marked with an asterisk are counted in the Number of forces selected on the Quota Preferences page.
| Optimization Time and Parallel | Description |
| plan opttimeoutlimit |
Specify that the Adaptive Server optimizer uses the optimization timeout limit to restrict the amount of time it takes to optimize a query. Note: The default value is 60 percent. You can specify a value from 0 to 1000. |
| resource_granularity | Specify that the Adaptive Server optimizer uses max resource granularity to set the amount of total memory allocated to a single query. |
| repartition_degree | Specify that the Adaptive Server optimizer uses repartition degree to suggest the maximum number of worker processes the query processor uses to partition a data stream. |
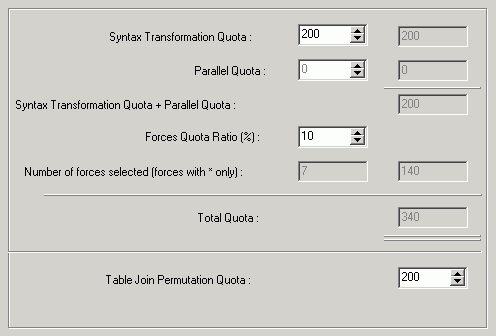
The Quota page on the Optimization tab of the Preferences window allows you to restrict the number of SQL transformations produced during optimization process. The optimization quotas can only be changed when the optimizer intelligence level is set to custom.
The maximum number of SQL statements generated by applying rules in the Feedback-Searching engine. The default quota of 100 is normally sufficient for most of the complicated SQL statements. However you can increase the quota to tackle exceptionally complicated SQL statements with very high levels of table joins or multiple levels of nested sub-queries.
This value controls the number of SQL statements that are generated during the process of rewriting the syntax of the SQL statement.
The maximum number of SQL statements generated by applying the degree of parallelism in the Feedback-Searching engine. Only applicable if the MAXDOP checkbox is selected.
The percentage used to calculate the maximum number of SQL statements to apply forces.
This value determines the number of SQL alternatives that are generated by applying the Forces to the original SQL and the SQL alternatives that were created by transforming the SQL syntax.
A read only field indicating the number of forces, goals, and criteria selected. Only the items that have an * after the name on the Forces/Goals and the Criteria pages are counted. This figure is used to calculate the maximum number of SQL statements generated by applying these selections, ((Syntax Transformation Quota + Parallel Quota) * Forces Quota Ratio%) * Number of Forces Selected = Forces Quota.
The maximum number of SQL statements generated during optimization, this figure consists of: Syntax Transformation Quota + Parallel Quota + Forces Quota.
The maximum number of table joins rearrangements to generate a new table join access path during optimization.
Note: You should bear in mind that the higher the quota, the longer it might take to optimize a complicated SQL statement.
The Abstract Plan page on the Optimization tab of the Preferences window allows you to include the retrieval of the abstract plan for the SQL statements. This requires Adaptive Server 15 or later.
Specify whether to retrieve the abstract plan for the SQL statement whenever the query plan is retrieved. The abstract plan displays in the SQL Optimizer window. The abstract plan is not saved on the database until you deliberately save it.
When this checkbox is selected, the selected abstract plan icon and the abstract plan group name display on the bottom right of the main status bar.
Note: For third-party package applications, you are able to optimize SQL statements without changing the source code by saving the abstract plan.
Specify the abstract plan group name where the abstract plans are saved. The default group names in Adaptive Server are: ap_stdout and ap_stdin. These groups are usually used by the Database Administrator to enable server-wide abstract plan capturing and retrieving.
ap_stdout is used by default to capture an abstract plan.
ap_stdin is used by default to retrieve the abstract plan associated with a SQL statement during the execution of the SQL statement.
Opens the Abstract Plan Manager window to view, create, and modify abstract plan group.
Specify whether you want to check the compatibility of the optimized SQL statements with the original SQL. When this option is selected, the AP Compatibility column displays on the SQL Run Time pane of the SQL Optimizer window and in the Batch Run Criteria window.
Note: A SQL statement may have many different "semantically equivalent" SQL statements. Each statement has an abstract plan. Even though SQL statements are "semantically equivalent", the abstract plans may not be compatible with the original SQL statement. When you check this option, the alternative abstract plans that are compatible with your original SQL are identified.

 View Optimization for ASE 15 - Quota page
View Optimization for ASE 15 - Quota page