Configure named queues
This chapter contains instructions for using the advanced SharePlex configuration options of named queues. These options provide an additional level of flexibility to divide and parallelize data to meet specific processing and routing requirements. Before proceeding, make certain you understand the concepts and processes in Configure data replication.
Contents
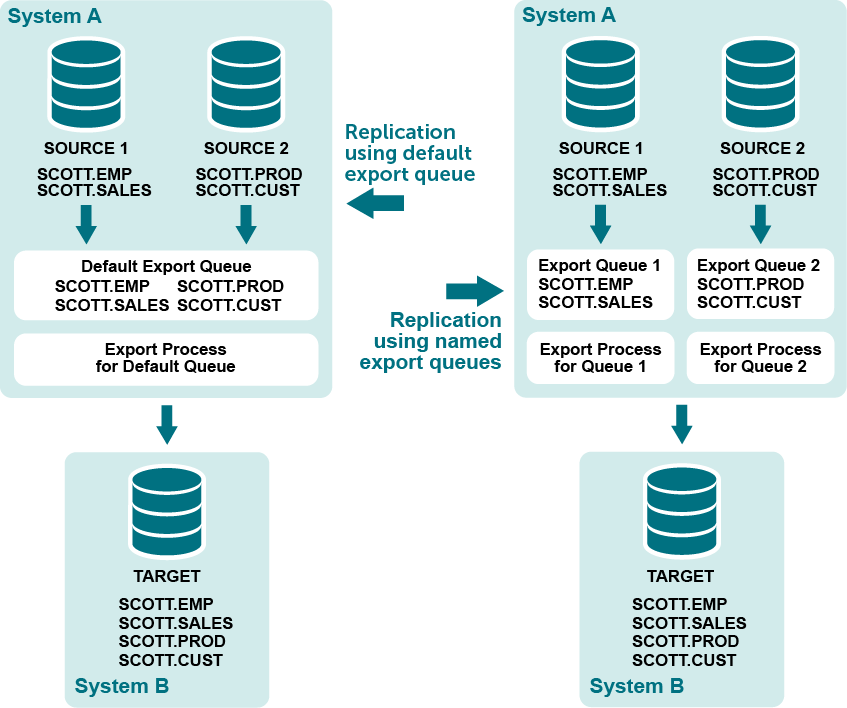
Configure named export queues
A named export queue is an optional, user-defined export queue that is attached to its own Export process. SharePlex creates each named Export queue and associated Export process in addition to the default export queue-process pair. When SharePlex creates a named export queue-process pair, it also creates a dedicated Import process, post queue, and Post process on the target to contain that data stream.
You direct SharePlex to create one or more named export queues when you create your configuration file. Any data that is not configured for processing through a named export queue is processed through the default export queue.
Supported sources
Oracle
Supported targets
All
Benefits of named export queues
Use named export queues to isolate the replication of:
- Individual configurations: By default, SharePlex sends data from all active configurations through one export queue-process pair per target system, but the use of named Export queues enables you to separate each of those replication streams into its own export queue and Export process. In this way, you ensure that purge config or abort config commands that are issued for one configuration do not affect any of the others.
- Selected database objects: You can use a named export queue to isolate certain objects such as tables that contain LOBs. Because each named export queue has its own Import process, post queue, and Post process on the target, you are able to isolate the data the entire way from source to target. For more information about the benefits of named post queues, see Configure named post queues.
Additional benefits:
- You can stop the Export or Import process for one data stream, while allowing the others to continue processing.
- You can set SharePlex parameters to different settings for each export queue-process pair. This enables you to tune the performance of the Export processes based on the objects replicating through each one.
Considerations when using named export queues
Note: If Post returns the error message "shs_SEMERR: an error occurred with the semaphore" on a Windows system, the number of semaphores may need to be increased to accommodate the queues that you created. For more information, see Post stopped .
Configure a named export queue
Use the following syntax to define a routing map that includes a named export queue.
source_host:export_queuename*target_host[@database]
Configuration with named export queue in routing map
| Datasource: o.SID |
| src_owner.table |
tgt_owner.table |
source_host:export_queue*target_host[@database_specification] |
| source_host |
The name of the source system. |
| export_queue |
The name of the export queue. Queue names are case-sensitive on all platforms. Use one word only. Underscores are permissible, for example:
sys1:export_q1*sys2@o.myora |
| target_host |
The name of the target system. |
| database specification |
One of the following for the datasource:
o.oracle_SID
r.database_name
One of the following if the target is a database:
o.oracle_SID
o.tns_alias
o.PDBname
r.database_name
c.oracle_SID |
NoteS:
- Allow no spaces between any components in the syntax of the routing map.
- For more information about the components of a configuration file, see Configure data replication.
Examples
The following configuration files show two different datasources that are being replicated to two different databases on the same target system. Each datasource is routed through a named export queue.
| Datasource:o.oraA |
|
|
| scott.emp |
scott.emp |
sysA:QueueA*sysB@o.oraC |
| scott.sales |
scott.sales |
sysA:QueueA*sysB@o.oraC |
| Datasource:o.oraB |
|
|
| scott.prod |
scott.prod |
sysA:QueueB*sysB@o.oraD |
| scott.cust |
scott.cust |
sysA:QueueB*sysB@o.oraD |
The following shows how to separate a table that contains LOBs from the rest of the tables by using named export queues.
| Datasource:o.oraA |
|
|
| scott.cust |
scott.cust |
sysA:QueueA*sysB@o.oraC |
| scott.sales |
scott.sales |
sysA:QueueA*sysB@o.oraC |
| scott.prod |
scott.prod |
sysA:QueueA*sysB@o.oraC |
| scott.emp_LOB |
scott.emp_LOB |
sysA:QueueB*sysB@o.oraC |
Alternatively, you could simply define a named export queue for the LOB table and allow the remaining tables to be processed through the default export queue.
| Datasource:o.oraA |
|
|
| scott.cust |
scott.cust |
sysB@o.oraC |
| scott.sales |
scott.sales |
sysB@o.oraC |
| scott.prod |
scott.prod |
sysB@o.oraC |
| scott.emp_LOB |
scott.emp_LOB |
sysA:lobQ*sysB@o.oraC |
How to identify named export queues
You can view named export queues through sp_ctrl:
- Use the qstatus command to view all queues on a system.
- Use the show command to view all Export processes with their queues.
See the SharePlex Reference Guide for more infomation about theses commands.
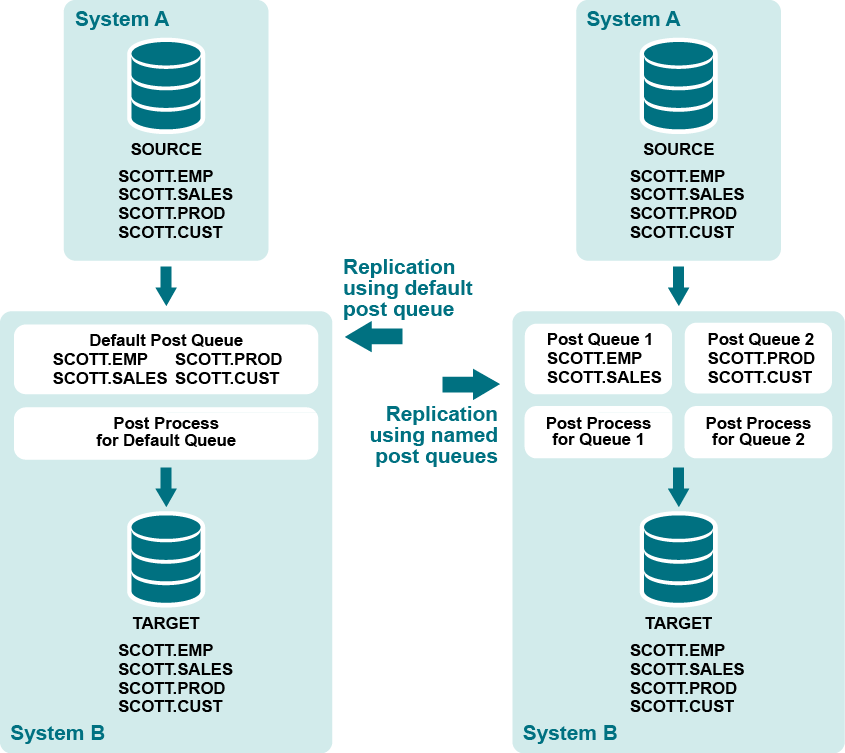
Configure named post queues
A named post queue is an optional component of the routing map in the configuration file. A named post queue is a user-defined post queue with its own Post process, which together operate in parallel to the default post queue and Post process. You can define one or more named post queue-process pairs to establish a set of parallel Post replication streams.
Supported sources
Oracle
Supported targets
All
Benefits of named post queues
You can use named post queues to isolate data from different tables into two or more separate Post streams. By using named post queues, you can improve posting performance by isolating objects such as the following that cause processing bottlenecks:
- large tables
- objects that have LOB columns. Named post queues are recommended for objects that contain LOBs.
- objects that involve large transactions.
- any objects whose operations you want to isolate.
Process the remaining objects through additional named post queues, or use the default post queue. Objects in the configuration file with a standard routing map (host@target) are replicated through a default post queue.
You can use horizontal partitioning to divide the rows of very large tables into separate named post queues as an added measure of parallelism.
You can set SharePlex parameters to different settings for each queue-process pair. This enables you to tune the performance of the Post processes based on the objects replicating through each one.
Considerations when using named post queues
- The analyze config command can help you determine how to organize your tables into named queues, based on any dependencies they have and their individual transactional activity. Run the command over a period of time that captures typical database activity, and then view the command output.
- Assign each post queue a unique name.
- If objects are linked by relational dependencies, process all of those objects through the same named post queue. If interdependent objects are not replicated through the same post queue, parent and child operations may be applied out of order and will cause database errors. As an alternative to processing interdependent objects through the same queue, you can disable their referential constraints on the target. This may be acceptable, because the constraints are satisfied on the source system and then replicated to the target.
- When using multiple Posts, the target objects might not be changed in the same order as the corresponding source objects, possibly causing the target database to be inconsistent with the source database at any given point in time.
- If you implement named post queues for objects in an active configuration (thus changing the routing) SharePlex locks those objects to update its internal directions.
-
SharePlex has a maximum number of allowed queues. For more information, see Routing specifications in a configuration file.
Note: If Post returns the error message "shs_SEMERR: an error occurred with the semaphore" on a Windows system, the number of semaphores may need to be increased to accommodate the queues that you created. For more information, see Post stopped .
Configure a named post queue
If you are using named export queues, SharePlex creates a named post queue-process pair for each one by default. If you are not using named export queues, use the following syntax to define a named post queue in the configuration file by adding the :queue component to the routing map:
host:queue@target
Configuration with named post queue in routing map
| Datasource: o.SID |
| src_owner.table |
tgt_owner.table |
host:queue[@database_specification] |
| host |
The name of the target system. |
| queue |
The unique name of the post queue. Queue names are case-sensitive on all platforms. One word only. Underscores are permissible, for example:
sys2:post_q1@o.myora |
| database_specification |
One of the following for the datasource:
o.oracle_SID
One of the following if the target is a database:
-
o.oracle_SID
o.tns_alias
o.PDBname
r.database_name
c.oracle_SID |
NoteS:
Examples
The following configuration creates one post queue named Queue1 that routes data from table scott.emp and another post queue named Queue2 that routes data from table scott.cust.
| Datasource:o.oraA |
|
|
| scott.emp |
scott.emp |
sysB:Queue1@o.oraC |
| scott.cust |
scott.cust |
sysB:Queue2@o.oraC |
The following shows how a named post queue is specified when you are routing data in a pass-through configuration using an intermediary system. For more information, see Configure replication to share or distribute data.
| Datasource:o.oraA |
|
|
| scott.emp |
scott.emp |
sysB*sysC:Queue1@o.oraC |
How to identify a named post queue
A named post queue is identified by the datasource (source of the data) and one of the following:
- the name of an associated named export queue (if the Import is linked to a named export queue)
- the user-assigned post-queue name (if the Import is linked to a default export queue).
You can view named post queues through sp_ctrl:
- Use the qstatus command to view all queues on a system.
- Use the show command to view all Post processes with their queues.
See the SharePlex Reference Guide for more infomation about theses commands.
Configure partitioned replication
Configure partitioned replication
This chapter contains instructions for using the advanced SharePlex configuration options of horizontally partitioned and vertically partitioned replication. These options provide an additional level of flexibility to divide, parallelize, and filter data to meet specific requirements. Before proceeding, make certain you understand the concepts and processes in Configure data replication.
Contents
