After initial index creation in a SQL Server database, everything is properly ordered, which means that the logical index page order perfectly matches the physical index page order within the datafile. This is the ideal scenario and it allows for maximum query performance. If the table contains data that never changes, the index will remain perfectly ordered.
Here is an example of how an Index is ordered after it was created and ordered by the CityName table column. This example shows two pages, both of them full.

The index is logically and physically ordered by the CityName. When a new record has to be added, for example “Detroit”, SQL Server will aim to add Detroit in between the Dallas and Houston.

Since that page is already full and there is no room , in order to accommodate new data, SQL Server will allocate a new page for that index and it will move the Houston and Los Angeles records from its original page to a new page to accommodate the new entry. Now when the space is granted in the page, SQL Server will insert “Detroit” into the original page.
The result will be as follows

The operation that was performed by SQL Server to accommodate the newly inserted data is called a page split. So, what is the problem? The new page was moved by SQL Server from an entirely different part of the datafile. The result is that now the logical order of pages is mismatched with its physical order. This mismatching between the logical and physical order of the index pages is referred to as index fragmentation. The more frequently new data are added into a table, the more fragmented the index will become, which means that SQL Server will require additional work to get the data with each query. Index fragmentation can be fixed, though, by applying either rebuild or reorganize operations.
In a situation where data is fragmented logically, SQL Server incurs additional physical I/O activity to get the data required by a query. A significantly higher logical and physical I/O activity that is produced for accomplishing the executed query will be registered with PAGEIOLATCH_XX wait types.
The most common of these are:
PAGEIOLATCH_SH (SH states for “share”) – the process is waiting for data page to be loaded from disk into the buffer pool to read its content. This is the most common wait type that will be registered as a consequence of the index fragmentation
PAGEIOLATCH_UP (UP states for “update”) – the process is waiting for data page to be loaded from disk into the buffer pool to update its content
PAGEIOLATCH_EX (EX states for “exclusive”) – the process is waiting for data page with exclusive latch to be loaded from disk into the buffer pool to modify its content
But what has to be understand is that index fragmentation is not an issue by itself.
Whether it will cause an issue or not, depends on what type of queries are executed against that table, or better say what kind of index operation will be performed. If an index seek operation (WHERE ColumnId=@Parameter) is going to be performed over a fragmented index, there will be no difference between the non-fragmented and fragmented index. Therefore, fixing index fragmentation will not gain any performance improvement and in such situation the doesn’t require any fixing.
It is index scan operations that have to be addressed (WHERE ColumnId BETWEEN @Parameter1 and @Parameter2) because it could experience performance issues due to index fragmentation.
Here is an example where a highly fragmented index caused a high PAGEIOLATCH_SH wait time.
I used BigAdwentureWorks2014 and the following query
SELECT * FROM dbo.bigProduct WHERE ListPrice between 1 and 200001 ORDER by [Name] DESC
To check the wait statistic for executed queries in ApexSQL Monitor, open the Query waits tab. What can be noticed immediately, is that there is a query that stands out from others by its wait time.
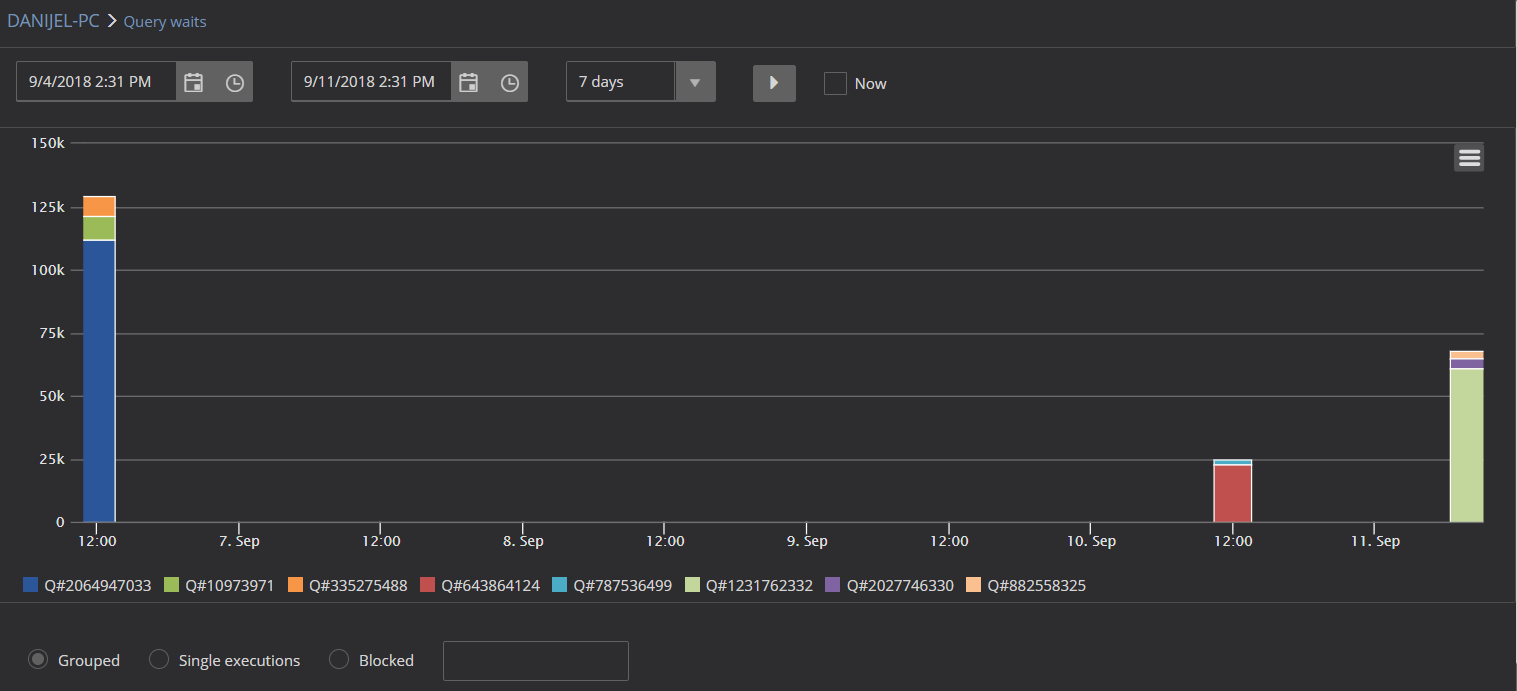
By hoovering over the query, basic information about the query such as wait types involved and wait times for each of them, SQL handle of the query and the query’s T-SQL. For more detailed information, expand the query on the right side (in this particular example it is the query #9). Here, besides the graphical presentation of the wait types involved and their wait values, some additional information such as CPU time (ms), Physical and Logical reads, Logical writes, IO (quite high IO in this particular case) and elapsed time for that specific query execution.
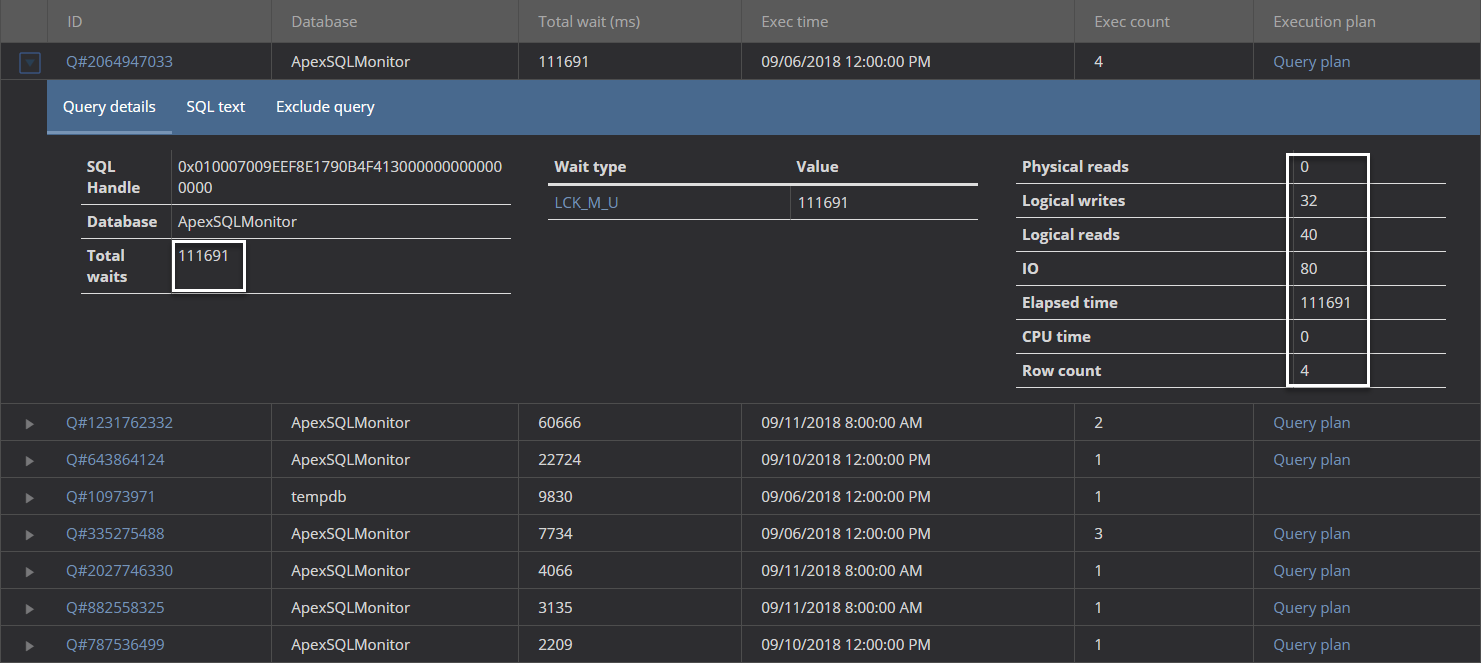
As it can be seen, LCK_M_U is accompanied with the high wait values of the CXPACKET wait type, which is almost a certain indicator that a large clustered index scans occurred in parallel, and in this case index fragmentation is a very possible cause of this issue.
If we press the Query plan link in query grid of the Q#2064947033, ApexSQL Monitor will display the execution plan for this query
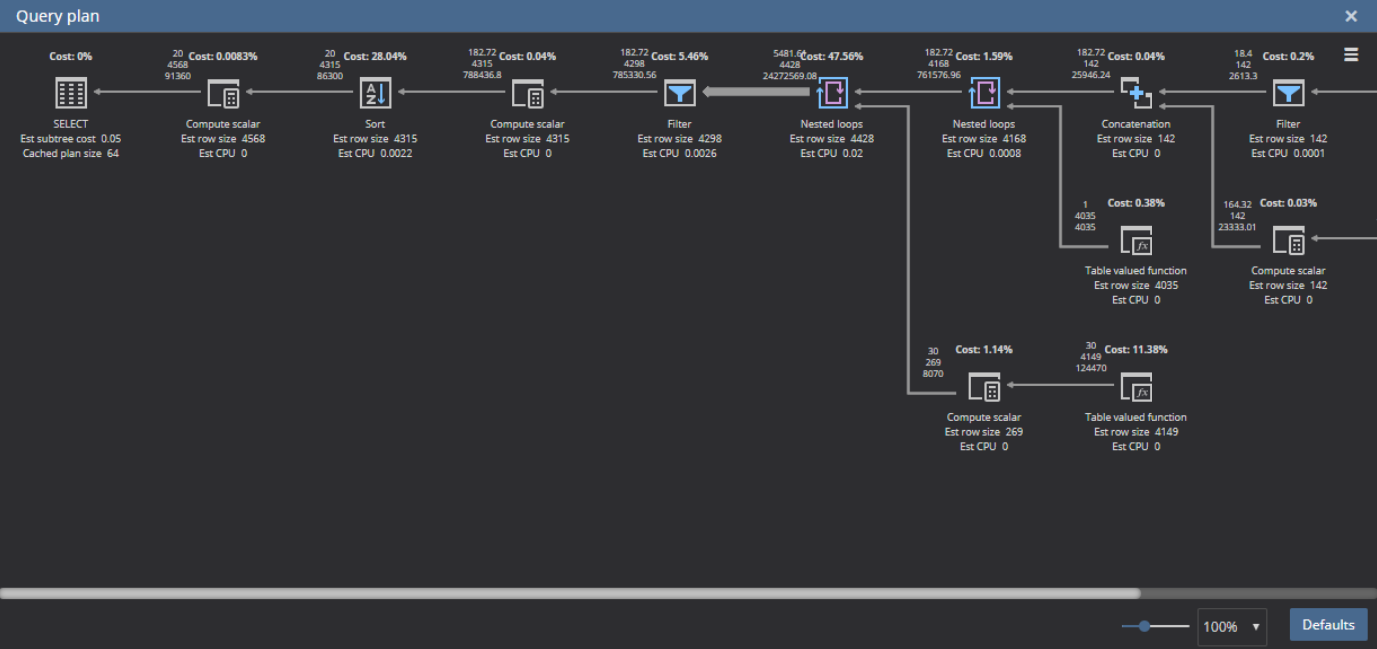
So, the plan just confirmed that the index scan is the operation with the highest cost performed by this query. This appears to confirm that particular index should probably be optimized.
But even in a situation explained above, there are other segments that have to be taken in account when deciding whether to deal with index fragmentation.
One of the typical examples where fixing the index fragmentation/fixing index fragmentation will not improve performance is already mentioned, when the index seek operation is the only operation that will be performed over a fragmented index. With the introduction of SSD disks and the way the SSD works with data, index fragmentation becomes much less relevant. It is even possible that fixing the index will degrade SQL Server performance when it is using SSDs.
Let’s assume that there is a highly-fragmented index B-tree (balanced search tree) and there is nothing ordered on the disk. In that case, an index scan operation will issue a large number of 8KB I/O requests. While that would cause a performance issue when SQL Server is using standard (mechanical) hard drives since they tend to use sequential reading (using fewer large blocks of data), SSD uses a method, optimized for reading a large number of small blocks of data. In situations where the index is rebuilt, which will defragment the B-Tree, the operation can go with single requests of up to 512KB in size. Due to SSD’s default mode of operation, such large requests will cause higher latencies as SSD will be forced to breaks down those large chunks into small 8KB sized chunks internally. The higher the latency, the slower the query will be, so in such case index rebuilds will actually worsen the performance. In addition it will cause an unnecessary waste of the SSD write cycles (SSD life time is limited by the number of write cycles it can perform), which will just shorten the life of SSD.
In cases, where a database is hosted on SSD and an index is highly fragmented, the query wait statistic will show different results.
By checking the ApexSQL Monitor query waits page for the same query from above, and with the same highly fragmented index that is now hosted on a SSD, the following results could be expected
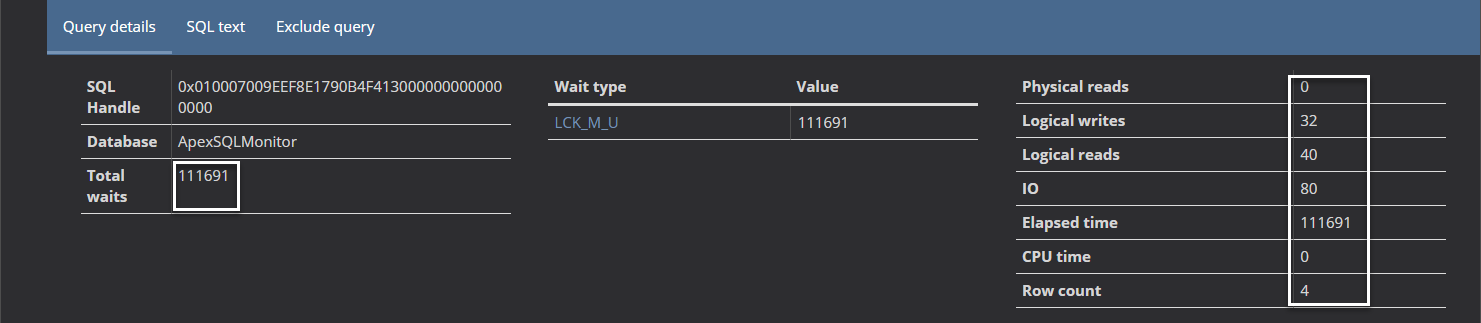
So, in situations where the SSD is used, it is highly unlikely that a highly fragmented index will affect SQL Server performance. To be sure in that, check the executed queries wait statistics, and it will be clear that LCK_M_U wait type will not pop up in the ApexSQL Monitor query waits tab.
Now that it is clear when the index fragmentation will affect database performance and when it will not, we’ll segue, in Part 2 of this series to situations when index fragmentation is the cause of performance issues that require use of the index maintenance operations, including rebuild and reorganize.
