User defined conflict resolution routines for PostgreSQL or PostgreSQL Database as a Service to Oracle
To create conflict resolution routines, you write PL/SQL procedures that direct the action of SharePlex when a conflict occurs. Business rules vary widely from company to company, so it is impossible to create a standard set of conflict resolution rules and syntax that apply in every situation. You will probably need to write your own routines. It is good practice to write more than one procedure, such as making site or system priority the primary routine and timestamp a secondary routine. SharePlex invokes one routine after another until one succeeds or there are no more procedures available.
SharePlex provides the following tools that can be used as a basis for your routines:
Important!
- This documentation provides guidelines, examples and templates to assist you, but do not use them as your own routines.
- Test your conflict resolution routines before you put them into production to make sure they work as intended, and to make sure that one routine does not counteract another one.
- By default, SharePlex does not stop for out-of-sync conditions. If failed attempts at conflict resolution are not resolved, the databases can become more and more out of synchronization. Check the Event Log frequently to monitor for out-of-sync warnings by using the show log command in sp_ctrl. See the SharePlex Reference Guide for more information about show log and other SharePlex commands.
- Updates are occasionally made to the conflict resolution logic, so refer to the Release Notes and documentation for your version of SharePlex for any additional information that augments or supersedes these instructions.
|
How to write a routine using the SharePlex generic interface
SharePlex provides a generic conflict resolution PL/SQL package that can be used to pass information to and from the procedural routines that you write.
Before you get started, understand that any table to be accessed through PL/SQL for conflict resolution requires implicitly granted privileges from the owner of the object to SharePlex. For additional guidelines for Oracle, see the How to write a routine for oracle section and for PostgreSQL, see the How to write a routine section.
Note: If you ran the SharePlex conflict resolution demonstration in the SharePlex Installation and Setup Guide, you can view a sample generic conflict resolution routine by viewing the od_employee_gen routine that was installed in the database used for the demonstration.
Procedure interface
For the procedure interface information of Oracle, see Procedure interface for Oracle.
For the procedure interface information of PostgreSQL, see Procedure interface for PostgreSQL.
List the routines in conflict_resolution.sid
After you create the conflict resolution procedure(s), construct the conflict resolution file. This file tells SharePlex which procedures to use for which objects and operation types, and in which order.
Where to find the conflict resolution file
A blank conflict_resolution.oraA, where oraA is a sid of OracleDB, was included in the data sub-directory of the SharePlex variable-data directory when SharePlex was installed. Use the file on the target system.
If this file does not exist, you can create one in ASCII format in an ASCII text editor. It must be named conflict_resolution.oraA, where oraA is a sid of OracleDB.
Important! There can be only one conflict_resolution.sid file per active configuration.
How to make entries in the conflict resolution file
Use the following template to link a procedure to one or more objects and operation types.
| SchemaName.tableName |
IUD |
schema.procedure |
where:
- IUD is the type of operation that creates the conflict that is resolved with the specified procedure.
- schema.procedure is the schema and name of the conflict resolution procedure that will handle the specified object and operation type.
Syntax rules
- There must be at least one space between the object specification, the operation type specification, and the procedure specification.
- The order in which you list the procedures in the conflict resolution file determines their priority of use (in descending order). If you list a table-specific procedure, SharePlex uses it before procedures that are specified with a wildcarded object name.
Example conflict resolution file
| scott.sal |
IUD |
scott.sal_cr |
| scott.cust |
IUD |
scott.cust_cr |
| !DEFAULT |
IUD |
scott.sal_cr5 |
How it works:
- The scott.sal_cr routine is used for the scott.sal table before the scott.sal_cr5 procedure is used for that table.
- For scott.cust, a procedure scott.cust_cr is called for IUD before the default routines are used for all operations.
How to specify SharePlex prepared routines in the conflict resolution file
To use the SharePlex prepared routines for all tables in the replication configuration, use the !DEFAULT parameter instead of specifying an schema and object name.
A custom routine takes priority over a SharePlex prepared routine. A prepared routine is used only if the custom routine fails. This is true regardless of the order in which the !DEFAULT-associated routine appears in the file.
The !DEFAULT parameter is case-sensitive. It must be typed in all capital letters.
| !DEFAULT |
IUD |
proc0 |
| schema.table1 |
IUD |
proc1 |
| james.table1 |
IUD |
proc2 |
| james.table1 |
IUD |
proc3 |
How to change the conflict resolution file while replication is active
You can change the conflict resolution file any time during replication to add and remove tables and procedures. After you change the conflict resolution file, stop and re-start the Post process.
Log information about resolved conflicts for Oracle database
You can configure the Post process to log information about successful conflict resolution operations if you are using the SharePlex prepared routines. This feature is disabled by default. For more information, see Log information about resolved conflicts for Oracle database.
SharePlex Prepared Routines
SharePlex provides optional prepared routines for use in conjunction with custom routines. These options can be used with basic and generic conflict resolution formats. There are no limitations on column types.
Supplemental logging of primary and unique keys must be enabled in the database.
Supported source and target database combinations
-
Oracle to Oracle
-
PostgreSQL to PostgreSQL
-
PostgreSQL to Oracle
-
PostgreSQL Database as a Service to PostgreSQL Database as a Service
-
PostgreSQL Database as a Service to Oracle
-
PostgreSQL Database as a Service to PostgreSQL
Considerations
Review the following considerations before implementing SharePlex prepared routines.
!HostPriority
This prepared conflict resolution routine works for INSERT, UPDATE, and DELETE operations. It provides host-based conflict resolution by assigning priority to the row change that originated on the trusted source system. To define the trusted source, set the SP_OPO_TRUSTED_SOURCE (Oracle source) or SP_OPX_TRUSTED_SOURCE (PostgreSQL source) parameter to the name of the source system.
Resolution logic
|
INSERT |
If the source is the one specified with SP_OPO_TRUSTED_SOURCE (Oracle source) or SP_OPX_TRUSTED_SOURCE (PostgreSQL source), convert the INSERT to an UPDATE and overwrite the existing row.
Otherwise, discard the change record and do nothing to the target row. |
| UPDATE |
If the source is the one specified with SP_OPO_TRUSTED_SOURCE (Oracle source) or SP_OPX_TRUSTED_SOURCE (PostgreSQL source), overwrite the existing row using an UPDATE and use only the key columns in the WHERE clause. Otherwise, discard the change record and do nothing to the target row. |
| DELETE |
Ignore the out-of-sync error and do nothing to the target row. |
Syntax in conflict resolution file
owner.table {I | U | D} !HostPriority
!LeastRecentRecord
This prepared routine works for INSERT, UPDATE, and DELETE operations. It provides time-based conflict resolution by assigning priority to the least recent row change, as determined by a timestamp.
To capture the timestamp, tables using this routine must have a non-NULL timestamp column that is updated with every INSERT and UPDATE on the table. If the timestamp column in the DML, or in the existing row, is NULL, this routine cannot resolve the conflict.
This routine requires the SP_OCT_REDUCED_KEY parameter for Oracle and SP_CAP_REDUCED_KEY parameter for PostgreSQL to be set to 0 on the source system, so that all of the pre-image values of UPDATES are available to the Post process.
Resolution logic
|
INSERT
and
UPDATE |
- If the value of the timestamp column of the replicated operation is greater than or equal to the timestamp column of the row in the target, discard the replicated operation and do nothing to the target row.
- If the timestamp column of the replicated operation is less than the timestamp column of the row in the target, overwrite the existing row using an UPDATE and use only the key columns in the WHERE clause.
|
| DELETE |
Ignore the conflict (out-of-sync message). |
Syntax in conflict resolution file
owner.table {I | U | D} !LeastRecentRecord(col_name)
Where col_name is the timestamp column to be used by the routine.
|
NOTEs:
-
The recommended data type for col_name in a PostgresSQL database is timestamp, as DATE data type does not store time value. As a result, if a date data type is used, a conflict will not be resolved if the same date is updated at both peers at the same time
-
The case sensitivity of the col_name for the Oracle peer depends on the source database.
-
If the data is being replicated from Oracle to Oracle, the col_name should be in uppercase.
-
If the data is being replicated from PostgreSQL to Oracle, the col_name should be in lowercase.
-
If the data is being replicated from both Oracle and PostgreSQL sources to Oracle, there should be two different entries of conflict resolution routines for col_name – one in uppercase and the other in lowercase. |
!MostRecentRecord
This prepared routine works for INSERT, UPDATE, and DELETE operations. It provides time-based conflict resolution by assigning priority to the most recent row change, as determined by a timestamp.
To capture the timestamp, tables using this routine must have a non-NULL timestamp column that is updated with every INSERT and UPDATE on the table. If the timestamp column in the DML, or in the existing row, is NULL, this routine cannot resolve the conflict.
This routine requires the SP_OCT_REDUCED_KEY parameter for Oracle and SP_CAP_REDUCED_KEY parameter for PostgreSQL to be set to 0 on the source system, so that all of the pre-image values of UPDATES are available to the Post process.
Resolution logic
|
INSERT
and
UPDATE |
- If the timestamp of the replicated operation is greater than the timestamp of the row in the target, overwrite the existing row using an UPDATE and use only the key columns in the WHERE clause.
- If the timestamp of the replicated operation is less than or equal to the timestamp of the row in the target, discard the change record and do nothing to the target row.
|
| DELETE |
Ignore the conflict (out-of-sync message). |
Syntax in conflict resolution file
owner.table {I | U | D} !MostRecentRecord(col_name)
Where col_name is the timestamp column to be used by the routine.
|
NOTEs:
-
The recommended data type for col_name in a PostgresSQL database is timestamp, as DATE data type does not store time value. As a result, if a date data type is used, a conflict will not be resolved if the same date is updated at both peers at the same time
-
The case sensitivity of the col_name for the Oracle peer depends on the source database.
-
If the data is being replicated from Oracle to Oracle, the col_name should be in uppercase.
-
If the data is being replicated from PostgreSQL to Oracle, the col_name should be in lowercase.
-
If the data is being replicated from both Oracle and PostgreSQL sources to Oracle, there should be two different entries of conflict resolution routines for col_name – one in uppercase and the other in lowercase. |
!UpdateUsingKeyOnly
This routine works for UPDATE operations. It provides conflict resolution that relies solely on the key value of the changed row. Normally, when SharePlex builds a SQL statement to post data, the WHERE clause uses both the key and the pre-image of the columns that changed to ensure synchronization. The !UpdateUsingKeyOnly routine directs SharePlex to post the data even though the pre-image values do not match, assuming the keys match.
If appropriate, this routine can be used as the sole routine for UPDATEs, but with the understanding that it does not include logic that assigns priority, such as system or time priority, in case of multiple concurrent UPDATEs. To avoid out-of-sync errors, Quest recommends using !UpdateUsingKeyOnly in conjunction with other, more specific routines, relying on !UpdateUsingKeyOnly as a final option if the custom routines fail.
Important:!UpdateUsingKeyOnly must be the last entry in the list of routines, thus assigning it last priority.
In the following example, when there is a conflict for owner.table1 during an UPDATE, SharePlex calls the two custom routines first (in order of priority) and then calls the !UpdateUsingKeyOnly routine.
| owner.table1 |
u |
owner.procedure_up_A |
| owner.table1 |
u |
owner.procedure_up_B |
| owner.table1 |
u |
!UpdateUsingKeyOnly |
The !UpdateUsingKeyOnly name is case sensitive. It must be typed exactly as shown in these instructions, with no spaces between words. Do not list an owner name with this routine in the configuration file. For INSERT and DELETE operations, custom logic must be used.
Log information about resolved conflicts for Oracle database
You can configure the Post process to log information about successful conflict resolution operations if you are using the SharePlex prepared routines. This feature is disabled by default.
To enable the logging of conflict resolution:
- Run sp_ctrl on the target system.
-
Issue the following command:
sp_ctrl> set param SP_OPO_LOG_CONFLICT {1 | 2}
-
A setting of 1 enables the logging of conflict resolution to the SHAREPLEX_CONF_LOG table.
Note: A setting of 1 will not update the columns EXISTING_TIMESTAMP and TARGET_ROWID (when existing data is not replaced) in the SHAREPLEX_CONF_LOG table.
-
A setting of 2 enables the logging of conflict resolution to the SHAREPLEX_CONF_LOG table with Post query for additional meta data.
Using LeastRecentRecord or MostRecentRecord prepared routines Post will query the target database for the timestamp column of the existing record. The query result is logged into the EXISTING_TIMESTAMP column of the SHAREPLEX_CONF_LOG table.
For any prepared routines, on rows that aren't replaced by the incoming record, Post will query the TARGET_ROWID of the existing row that could have been replaced. Otherwise the ROWID of the existing row will not be logged.
Note: A setting of 2 may affect the performance of Post as a result of making the query.
- Restart Post.
Post logs the information to a table named SHAREPLEX_CONF_LOG. The following describes this table.
| CONFLICT_NO |
NUMBER NOT NULL |
The unique identifier of the resolved conflict. This value is generated from the shareplex_conf_log_seq sequence. |
| CONFLICT_TIME |
TIMESTAMP DEFAULT SYSTIMESTAMP |
The timestamp of the conflict resolution |
| CONFLICT_TABLE |
VARCHAR2(100) |
The name of the target table that was involved in the conflict |
| CONFLICT_TYPE |
VARCHAR2(1) |
The type of conflict, either I for insert, U for update, or D for delete |
| CONFLICT_RESOLVED |
VARCHAR2(1) NOT NULL |
Indicator of whether the conflict was resolved or not.
Y = yes, the conflict was resolved
N = no, the conflict was not resolved. Unresolved conflicts are logged to the ID_errlog.sql file, where ID is the source database identifier. |
| TIMESTAMP_COLUMN |
VARCHAR2(50) |
The name of the column that contains the timestamp that Post compared to determine which record was most recent. |
| INCOMING_TIMESTAMP |
DATE |
The timestamp that the row was inserted, updated, or deleted on the source system |
| EXISTING_TIMESTAMP |
DATE |
The current timestamp of the row in the target database. This applies only if the SP_OPO_LOG_CONFLICT parameter is set to 2, which directs Post to query the target database to get this value. |
| PRIMARY_KEYS |
VARCHAR2(4000) |
The names of the primary key columns |
| MESSAGE |
VARCHAR2(400) |
A message that states which row won in the conflict. The row that wins depends on which conflict resolution routine was used. For example, the following message is returned when the !MostRecentRecord routine is used and the most recent record is the source record:
Incoming timestamp > existing timestamp. Incoming wins, overwrite existing.
If the target record was the most recent one or has the same timestamp as the source record, then the message would be:
Incoming timestamp <= existing timestamp. Existing wins, discard incoming. |
| SQL_STATEMENT |
LONG |
The final SQL statement that got executed as a result of the conflict resolution |
| CONFLICT_CHECKED |
VARCHAR2(1) |
Indicates whether or not someone reviewed the conflict. The default is N for No. The person who reviews the conflict can change this value to Y. |
Log information about resolved conflicts for PostgreSQL database
You can configure the Post process to log information about successful conflict resolution operations if you are using the SharePlex prepared routines. This feature is disabled by default.
To enable the logging of conflict resolution:
- Run sp_ctrl on the target system.
-
Issue the following command:
sp_ctrl> set param SP_OPX_LOG_CONFLICT {1 | 2}
-
A setting of 1 enables the logging of conflict resolution to the shareplex_conf_log table.
Note: A setting of 1 will not update the column existing_timestamp (when existing data is not replaced) in the shareplex_conf_log table.
-
A setting of 2 enables the logging of conflict resolution to the shareplex_conf_log table with Post query for additional meta data.
Using LeastRecentRecord or MostRecentRecord prepared routines Post will query the target database for the timestamp column of the existing record. The query result is logged into the existing_timestamp column of the shareplex_conf_log table.
Note: A setting of 2 may affect the performance of Post as a result of making the query.
- Restart Post.
Post logs the information to a table named shareplex_conf_log. The following describes this table.
| conflict_no |
bigserial primary key |
The unique identifier of the resolved conflict. This value is generated from the shareplex_conf_log_conflict_no_seq sequence. |
| conflict_time |
timestamp |
The timestamp of the conflict resolution. |
| src_host |
varchar(64) |
The host name of source host. |
| curr_host |
varchar(64) |
The host name of current host. |
| trusted_host |
varchar(64) |
The host name of trusted host. It will be used in case of !HostPriority prepared routine. |
| src_db |
varchar(150) |
The source database name. |
| source_rowid |
varchar(20) |
The source table rowid. For PostgreSQL source, this column is not applicable. Its value will be N/A. |
| target_rowid |
varchar(20) |
The target table rowid. For PostgreSQL target, this column is not applicable. Its value will be N/A. |
| conflict_table |
varchar(300) |
The name of the target table that was involved in the conflict. |
| conflict_type |
char(1) |
The type of conflict, either I for insert, U for update, or D for delete. |
| conflict_resolved |
char(1) not null |
Indicator of whether the conflict was resolved or not.
Y = yes, the conflict was resolved
N = no, the conflict was not resolved. Unresolved conflicts are logged to the ID_errlog.sql file, where ID is the source database identifier. |
| odbc_error |
varchar(20) |
Indicates odbc error which caused the conflict. Its format is <native error>:<error sqlstate> |
Configure Replication through an intermediary system
These instructions show you how to set up cascading replication, also known as multi-tiered replication. This strategy replicates data from a source system to an intermediary system, and then from the intermediary system to one or more remote target systems.
Cascading replication can be used to support various replication objectives as a workaround in such conditions as the following:
- Your replication strategy exceeds the 1024 routes that are allowed directly from a given source system: You can send data to the intermediary system and then broadcast to the additional targets from there.
- The source has no direct connection to the ultimate target, because of firewall restrictions or other factors. You can cascade to a system that does allow remote connection from the source system.
To use a cascading strategy, the source machine must be able to resolve the final target machine name(s), although the ability to make a direct connection is not required.
Supported sources
Oracle and PostgreSQL
Supported targets
Oracle
Oracle and Open Target (final target)
Capabilities
This replication strategy supports the following:
- Replication to one or more target systems
- Identical or different source and target names
- Use of vertically partitioned replication
- Use of horizontally partitioned replication
- Use of named export and post queues
Requirements
-
Prepare the system, install SharePlex, and configure database accounts according to the instructions in the SharePlex Installation Guide.
Important! Create the same SharePlex user on all systems if you will be using SharePlex to post to a database on the intermediary system.
-
Disable triggers that perform DML on the target objects.
- No DML or DDL should be performed on the target tables except by SharePlex. Tables on the target system that are outside the replication configuration can have DML and DDL operations without affecting replication.
-
If sequences are unnecessary on the target system, do not replicate them. It can slow down replication. Even if a sequence is used to generate keys in a source table, the sequence values are part of the key columns when the replicated rows are inserted on the target system. The sequence itself does not have to be replicated.
DDL Replication Support
DDL replication from source to target through an intermediary system is supported in accordance with the information found in the DDL that SharePlex Supports chapter of the Administration Guide, with the following exceptions:
- DDL initiated on the intermediary system, as opposed to the source, will cause inconsistencies leading to Post errors and should be avoided unless the DDL is synchronized across all systems.
- All systems must be monitored to ensure that latency or errors on the intermediary system do not cause inconsistencies.
Important! These instructions assume you have a full understanding of SharePlex configuration files. They use abbreviated representations of important syntax elements. For more information, see Configure SharePlex to Replicate Data.
Conventions used in the syntax
In the configuration syntax in this topic, the placeholders represent the following:
- source_specification[n] is the fully qualified name of a source object (owner.object) or a wildcarded specification.
- target_specification[n] is the fully qualified name of a target object or a wildcarded specification.
- host is the name of a system where SharePlex runs. Different systems are identified by appending a letter to the names, like hostB.
- db is a database specification. The database specification consists of either o. or r. prepended to the Oracle SID, TNS alias, or database name, as appropriate for the connection type. A database identifier is not required if the target is JMS, Kafka, or a file.
Important! Configure SharePlex to Replicate Data.
Deployment options
To cascade data, you have the following options:
-
If there is a database on the intermediary system, you can configure SharePlex to post to that database and then capture the data again to replicate it to one or more remote targets.
-
If there is not a database on the intermediary system, you can configure SharePlex to import, queue, and then export the data to one or more remote targets. There is no Capture process on the system. This is known as a pass-through configuration. It passes the data directly from the source system to the target(s).
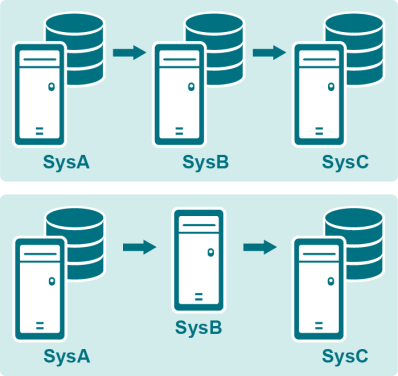
Cascade with posting on intermediate system
To use this configuration:
- SharePlex database accounts must exist on all systems and must be the same name on all systems. This account is usually created when SharePlex is installed. See the SharePlex Installation Guide for more information.
- Triggers must be disabled in the intermediary database, as well as on the target system.
-
Oracle DDL replication is not supported from an Oracle database on the intermediary system to the target systems. It is supported only from the source system to the intermediary system.
- You create two configuration files: one on the source system, and one on the intermediary system.
-
Enable archive logging on the source and intermediary systems in case the redo logs wrap before Capture is finished with them.
Configuration options on source system
This configuration replicates from the source system to the database on the intermediary system.
Note: In this template, hostB is the intermediary system.
|
datasource_specification |
|
|
| source_specification1 |
target_specification1 |
hostB@o.SID |
| source_specification2 |
target_specification2 |
hostB@o.SID |
Example on source system
| Datasource:o.oraA |
|
|
| hr.emp |
hr.emp2 |
hostB@o.oraB |
| hr.sal |
hr.sal2 |
hostB@o.oraB |
| cust.% |
cust.% |
hostB@o.oraB |
Note: In this same configuration, you could route data from other source objects directly to other targets, without cascading through the intermediary system. Just specify the appropriate routing on a separate line.
Configuration options on intermediary system
This configuration captures the data from the database on the intermediary system, then replicates it to the target system(s). The tables that were the target tables in the source configuration are the source tables in this configuration. The target can be any supported SharePlex target.
|
datasource_specification |
|
|
| source_specification1 |
target_specification1 |
hostC[@db][+...] |
| source_specification2 |
target_specification2 |
hostD[@db][+...] |
Example on intermediary system
| Datasource:o.oraB |
|
|
| hr.emp |
hr.emp2 |
hostC@o.oraC |
| hr.sal |
hr.sal2 |
hostD@o.oraD+hostE@r.mssE |
| cust.% |
cust.% |
!cust_partitions |
Note: The last entry in this example shows the use of horizontally partitioned replication to distribute different data from the sales.accounts table to different regional databases. For more information, see Configure Horizontally Partitioned Replication.
Required parameter setting on intermediary system
(Oracle intermediary database) Set the SP_OCT_REPLICATE_POSTER parameter to 1 if the intermediary database is Oracle. This instructs the Capture process on the intermediary system to capture the changes posted by SharePlex and replicate them to the target system. (The default is 0, meaning that Capture ignores Post activity on the same system.)
In sp_ctrl, issue the following command. The change takes effect the next time Capture starts.
set param SP_OCT_REPLICATE_POSTER 1
Cascade with pass-through on intermediary system
To use this configuration:
Configuration options on source system
Note: In this template, hostB is the intermediary system.
|
datasource_specification |
| source_specification1 |
target_specification1 |
hostB*hostC[@db] |
| source_specification2 |
target_specification2 |
hostB*hostD[@db][+hostB*hostE[@db][+...] |
| source_specification3 |
target_specification3 |
hostB*hostX[@db]+hostY[@db] |
- The hostB*host syntax configures the pass-through behavior.
- If using a compound routing map where all data passes through the intermediary system first, make certain to use the hostB* component in each target route.
- You can also use a compound routing map where data from a source object is replicated directly to one target, and also through the intermediary system to another target, as in the third line of this configuration file.
Example
| Datasource:o.oraA |
|
|
| hr.emp |
hr.emp2 |
hostB*hostC@o.oraC |
| hr.emp |
hr."Emp_3" |
hostB*hostC@r.mssB |
| cust.% |
cust.% |
hostB*hostD@o.oraD+hostE@o.oraE |
