
이 장에는 수평으로 파티셔닝된 복제 및 수직으로 파티셔닝된 복제의 고급 SharePlex 구성 옵션을 사용하기 위한 지침이 포함되어 있습니다. 이러한 옵션은 특정 요구 사항을 충족하기 위해 데이터를 분할하고 병렬화하며 필터링할 수 있는 추가적인 유연성을 제공합니다. 계속하기 전에 구성 파일 생성에 관한 개념과 프로세스를 이해했는지 확인하십시오.
이 장에는 수평으로 파티셔닝된 복제 및 수직으로 파티셔닝된 복제의 고급 SharePlex 구성 옵션을 사용하기 위한 지침이 포함되어 있습니다. 이러한 옵션은 특정 요구 사항을 충족하기 위해 데이터를 분할하고 병렬화하며 필터링할 수 있는 추가적인 유연성을 제공합니다. 계속하기 전에 구성 파일 생성에 관한 개념과 프로세스를 이해했는지 확인하십시오.
수평으로 파티셔닝된 복제를 사용하여 테이블 행을 별도의 처리 스트림으로 나눕니다. 수평으로 파티셔닝된 복제를 사용하여 다음을 수행할 수 있습니다.
PostgreSQL에서 PostgreSQL, Oracle, SQL Server 및 Kafka로
Oracle에서 모든 타겟으로
PGDB as a Service에서 PGDB as a Service로
PGDB as a Service에서 Oracle로
PGDB as a Service에서 PostgreSQL로
테이블에 대해 수평으로 파티셔닝된 복제를 구성하는 단계는 다음과 같습니다.
행 파티션을 정의하고 이를 파티션 scheme에 연결합니다.
행 파티션은 그룹으로 복제할 소스 테이블 행의 하위 집합입니다.
파티션 scheme은 행 파티션의 논리적 컨테이너입니다.
파티션 scheme의 행 파티션은 다음 중 하나를 기반으로 할 수 있습니다.
다음과 같은 목적으로 컬럼 조건에 따라 행 파티션을 사용할 수 있습니다.
여러 행 파티션을 사용하여 테이블의 행을 나누어 각 행 집합이 다른 타겟에 복제되도록 합니다. 예를 들어 CORPORATE.SALES라는 테이블에는 "East"와 "West"라는 두 개의 행 파티션이 있을 수 있습니다. 이에 따라 컬럼 조건이 정의됩니다. 여기서, REGION = EAST를 충족하는 행은 한 위치에 복제되고 REGION = WEST를 충족하는 행은 다른 위치에 복제됩니다. 파티션 scheme 이름은 "Sales_by_region"일 수 있습니다.
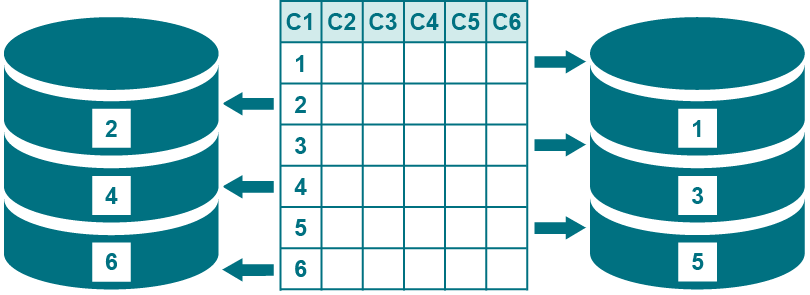
타겟 테이블에 더 빠르게 게시하기 위해 다중 행 파티션을 사용하여 테이블의 행을 병렬 처리 스트림(병렬 Export-Import-Post 스트림)으로 나눕니다. 예를 들어 크게 업데이트된 타겟 테이블에 대한 복제 흐름을 개선할 수 있습니다. 이 목적으로 컬럼 조건을 사용하는 것은 병렬 Post 프로세스 간에 처리를 균등하게 분할할 수 있는 컬럼이 테이블에 포함된 경우에만 적합합니다.
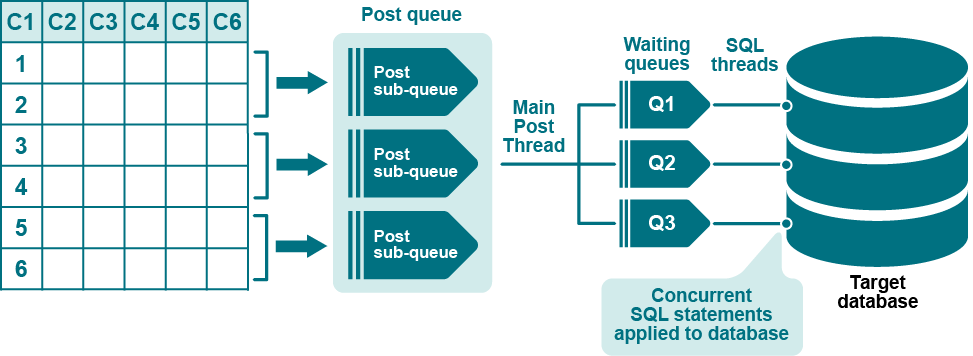
타겟 테이블에 더 빠르게 게시하기 위해 해시 값을 기반으로 행 파티션을 사용하여 테이블의 행을 병렬 처리 스트림(병렬 Export-Import-Post)으로 나눌 수 있습니다. 파티션을 생성하기 위해 컬럼 조건보다 해시 값을 사용하면 WHERE 절에서 테이블 컬럼을 참조할 필요 없이 행이 SharePlex에 의해 자동으로 균등하게 나눠지는 이점이 있습니다. 그러나 컬럼 기반 파티션 scheme와 달리 해시 기반 파티션 scheme에는 SharePlexcompare 또는 repair 명령을 사용할 수 없습니다.
수평으로 파티셔닝된 복제와 수직으로 파티셔닝된 복제를 결합하여 정보가 배포되는 방식을 최대한 제어할 수 있습니다.
예를 들면 다음과 같습니다.
수평으로 파티셔닝된 복제는 동일한 테이블에 대한 전체 테이블 복제와 함께 사용할 수 있습니다. 예를 들어 행 그룹을 다른 보고 시스템으로 라우팅하고 모든 행을 백업 시스템으로 라우팅할 수 있습니다.
해시 기반 파티셔닝은 다음을 지원하지 않습니다.
해시 기반 파티셔닝은 행을 다른 파티션으로 마이그레이션하는 작업도 지원하지 않습니다. 이러한 작업의 예는 다음과 같습니다.
add partition 명령을 사용하여 행 파티션을 만들고 이를 파티션 scheme에 할당할 수 있습니다.
컬럼 조건에 따라 행을 분할하려면 다음을 수행합니다.
지정된 파티션 scheme에서 생성할 각 행 파티션에 대해 add partition을 실행합니다. 첫 번째 행 파티션을 생성할 때 SharePlex는 파티션 scheme도 생성합니다.
sp_ctrl> add partition to scheme_name setcondition = column_condition and route = routing_map [and name = name] [and tablename =owner.table] [and description =description]
해시 값에 따라 행을 파티셔닝하려면 다음을 수행합니다.
생성할 해시 파티션 수를 지정하려면 add partition을 한 번 실행합니다.
sp_ctrl> add partition to scheme_name set hash = value and route = value
참고: add partition과 toScheme_name 및 set 키워드를 지정하면 다른 모든 구성 요소는 순서에 관계없이 가능합니다.
| 구성 요소 | 설명 |
|---|---|
| to scheme_name |
to는 scheme_name에 행 파티션이 추가됨을 나타내는 필수 키워드입니다. scheme_name은 파티션 scheme의 이름입니다. 파티션 scheme은 사용자가 실행하는 첫 번째 add partition 명령에 의해 생성되며, 파티셔닝할 첫 번째 행 집합도 지정합니다. 수평 파티셔닝을 많이 사용하는 경우 파티션 scheme에 대한 명명 규칙을 설정하는 것이 도움이 될 수 있습니다. |
|
set |
행 파티션 정의를 시작하는 필수 키워드입니다. |
| condition = column_condition |
컬럼 조건에 따라 행 파티션을 생성합니다. 조건은 따옴표로 묶어야 합니다. ((region_id = West) and region_id is not null)과 같은 표준 WHERE 조건부 구문을 사용합니다. condition 및 hash 구성 요소는 상호 배타적입니다. |
| hash = value |
해시 값을 기반으로 행 파티션을 생성합니다. 지정된 값은 파티션 scheme의 행 파티션 수를 결정합니다. condition 및 hash 구성 요소는 상호 배타적입니다. |
| route = routing_map |
이 파티션의 경로입니다. 이는 다음 중 하나일 수 있습니다. 컬럼 조건에 따른 파티션: 표준 SharePlex 라우팅 맵을 지정합니다(예: sysB@o.myora, sysB:q1@o.myora 또는 sysB@o.myora+sysC@o.myora(복합 라우팅 맵)). 타겟이 JMS, Kafka 또는 파일인 경우 타겟을 x.jms, x.kafka 또는 x.file로 지정해야 합니다(예: sysA:hpq1@x.kafka). 이름이 다른 여러 타겟 테이블로 파티션을 라우팅하려면 다음을 수행합니다.
해시 기반 파티션: 다음 형식을 사용하여 SharePlex에 각 파티션에 대한 명명된 Post 큐를 생성하도록 지시합니다. host:basename|#{o.SID | r.database} 여기서,
|
| name = name |
(권장) 이 파티션의 짧은 이름입니다. 이 옵션은 컬럼 조건을 기반으로 하는 파티션에만 유용합니다. 짧은 이름을 사용하면 나중에 파티션을 수정하거나 삭제해야 하는 경우 긴 컬럼 조건을 입력할 필요가 없습니다. |
| tablename = owner.table |
(선택 사항) 타겟 테이블이 여러 개 있고 하나 이상의 이름이 다른 경우 이 옵션을 사용합니다. 각 이름에 대해 별도의 add partition 명령을 실행합니다. 테이블 이름은 정규화되어야 합니다. 대소문자를 구분하는 경우 이름을 따옴표로 묶어 지정해야 합니다. 예: add partition to scheme1 set name = p1 and condition = "C1 > 200" and route = sysb:p1@o.orasid and tablename = myschema.mytable |
| description = description | (선택 사항) 이 파티션에 대한 설명입니다. |
여러 Post 큐를 통해 다양한 행 집합 라우팅:
sp_ctrl> add partition to scheme1 set name = q1 and condition = "C1 >= 200" and route = sysb:q1@o.orasid
sp_ctrl> add partition to scheme1 set name = q2 and condition = "C1 < 200" and route = sysb:q2@o.orasid
여러 행 집합을 소스의 다양한 타겟 시스템과 다양한 테이블 이름으로 라우팅합니다.
sp_ctrl> add partition to scheme1 set name = east and condition = "area = east" and route = sys1e@o.orasid and tablename = ora1.targ
sp_ctrl> add partition to scheme1 set name = west and condition = "area = west" and route = sys2w@o.orasid and tablename = ora2.targ
행을 4개의 파티션으로 나누고 각 파티션은 서로 다른 Post 큐를 통해 처리됩니다.
sp_ctrl> add partition to scheme1 set hash = 4 and route = sysb:hash|#@o.ora112
다음은 컬럼 조건 생성에 대한 가이드라인입니다. 이러한 가이드라인은 해시 값으로 생성된 행 파티션에는 적용되지 않습니다.
컬럼 조건의 기반이 되는 컬럼 유형은 데이터 소스에 따라 다릅니다.
PRIMARY 또는 UNIQUE 키 컬럼과 같이 값이 변경되지 않는 컬럼에 대한 기본 컬럼 조건입니다. 목표는 파티션 이동을 방지하는 것입니다. 여기서, 파티션의 조건부 컬럼을 변경하면 기본 데이터가 다른 파티션의 조건을 충족하거나 충족하지 않을 수 있습니다.
파티션 이동 사례 1: 새 값이 더 이상 컬럼 조건을 충족하지 않도록 컬럼 값이 업데이트됩니다.
파티션 이동 사례 2: 하나의 컬럼 조건을 충족하는 행이 다른 조건을 충족하도록 업데이트됩니다.
다음 방법을 사용하여 컬럼 조건 값 변경으로 인한 동기화 중단 행을 복원할 수 있습니다.
또한 구성 파일을 활성화하기 전에 소스에 다음과 같은 매개변수를 설정하여 데이터가 제대로 복제되는지 확인할 수 있습니다.
참고: 컬럼 조건에 따라 키가 아닌 컬럼을 사용하고 수평으로 파티셔닝된 복제를 활성화하여 성능이 저하되는 경우, 해당 컬럼에 대한 로그 그룹을 추가합니다.
SharePlex는 컬럼 조건에서 다음과 같은 데이터 유형을 지원합니다.
참고:
|
다음 목록은 컬럼 조건에서 SharePlex가 지원하는 조건부 구문을 보여줍니다. 여기서,
|
column = value
not (column = value)
column > value
value > column
column < value
column <= value
column >= value
column <> value
column != value
column like value
column between value1 and value2
not (column between value1 and value2 )
column is null
column is not null |
조건은 괄호와 AND, OR 및 NOT 논리 연결을 사용하여 중첩된 표현식으로 결합할 수 있습니다.
다음을 수행하지 마십시오.
전체 테이블 복제가 있는 테이블과 파티셔닝된 복제를 사용할 테이블을 포함하여 지정된 데이터 소스에서 복제할 모든 데이터에 대해 하나의 구성 파일을 사용합니다.
| Datasource:o.SID | ||
| src_owner.table | tgt_owner.table |
!partition_scheme |
| ! | routing_map | |
| 구성 요소 | 설명 | |
|---|---|---|
|
o.database |
데이터 소스 지정입니다. Oracle 소스에는 r. 표기법을 사용합니다. 데이터베이스의 경우 ORACLE_SID을 지정합니다. | |
| src_owner.table 및 tgt_owner.table | 각각 소스 및 타겟 테이블의 사양입니다. | |
| !partition_scheme |
지정된 소스 및 타겟 테이블에 사용할 파티션 scheme의 이름입니다. ! 기호가 필요합니다. 이름은 대소문자를 구분합니다. 여러 파티션 scheme의 복합 라우팅은 지원되지 않습니다(예: !schemeA+schemeB). 동일한 소스 테이블에 사용할 각 파티션 scheme에 대해 별도의 항목을 만듭니다. 예를 참조하십시오. | |
| ! routing_map |
자리 표시자 라우팅 맵입니다. 이 맵은 파티션 scheme에 사용한 경로가 구성 파일의 어딘가에 나열되지 않은 경우에만 필요합니다. SharePlex는 파티션 scheme에 나와 있더라도 모든 경로가 구성 파일에 있어야 합니다.
예를 참조하십시오. |
| Datasource: o.mydb | ||
| scott.emp | scott.emp_2 | !partition_emp |
| Datasource: o.mydb | ||
| scott.emp | scott.emp_2 | !partition_schemeA |
| scott.emp | scott.emp_3 | !partition_schemeB |
| ! targsys1 |
| ! targsys2@o.ora2+targsys3@o.ora3 |
이 자리 표시자는 컬럼 조건을 기반으로 하는 파티션에만 필요합니다.
view partitions 명령을 사용하면 하나의 파티션 scheme의 행 파티션을 보거나 수평으로 파티셔닝된 복제 구성의 모든 파티션 scheme을 볼 수 있습니다.
행 파티션을 보려면 다음을 수행합니다.
모든 파티션을 보려고 하거나 특정 파티션 scheme의 파티션만 보려는지 여부에 따라 두 옵션 중 하나를 사용하여 다음 명령을 실행합니다.
sp_ctrl> view partitions for {scheme_name | all}
다음 예에서는 해시 기반 파티션 scheme과 컬럼 기반 파티션 scheme을 보여줍니다.
sp_ctrl> view partitions all
Scheme Name Route Hash Condition ----------- ------------- ------------------------------ ------ --------------- HASH4 hash sys02:hash|#@o.ora112 4 ROWID TEST_CT highvalues sys02:highvalues@o.ora112 sales>=10000 TEST_CT lowvalues sys02:lowvalues@o.ora112 sales<10000
파티션 Post 큐를 보려면 다음을 수행합니다.
타겟의 qstatus 명령은 수평으로 파티셔닝된 복제와 관련된 Post 큐를 표시합니다.
sp_ctrl sys02> qstatus
Queues Statistics for sys02
Name: highvalues (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: lowvalues (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Queues Statistics for sys02
Name: hash1 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash2 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash3 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
Name: hash4 (o.ora11-o.ora112) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
파티션 scheme을 관리하는 데 다음 명령이나 매개변수를 사용할 수 있습니다. 자세한 내용은 SharePlex 참조 안내서을 참조하십시오.
|
작업 |
명령/매개변수 |
설명 |
|---|---|---|
|
파티션 수정 |
modify partition 명령 |
행 파티션 정의의 속성을 수정합니다. |
|
파티션 scheme 제거 |
drop partition scheme 명령 |
파티션 scheme과 scheme 내에 있는 모든 행 파티션을 제거합니다. |
|
해시 알고리즘 변경 |
SP_OCF_HASH_BY_BLOCK |
해시 알고리즘을 기본값인 rowid 기반에서 블록 기반으로 변경합니다. 블록 기반 알고리즘을 활성화하려면 1로 설정합니다. |
PostgreSQL, Oracle, SQL Server 및 Kafka
|
참고:
|
테이블에 대해 수평으로 파티셔닝된 복제를 구성하는 단계는 다음과 같습니다.
행 파티션을 정의하고 이를 파티션 scheme에 연결합니다.
행 파티션은 그룹으로 복제할 소스 테이블 행의 하위 집합입니다.
파티션 scheme은 행 파티션의 논리적 컨테이너입니다.
다음과 같은 목적으로 컬럼 조건에 따라 행 파티션을 사용할 수 있습니다.
여러 행 파티션을 사용하여 테이블의 행을 나누어 각 행 집합이 다른 타겟에 복제되도록 합니다. 예를 들어 CORPORATE.SALES라는 테이블에는 "East"와 "West"라는 두 개의 행 파티션이 있을 수 있습니다. 이에 따라 컬럼 조건이 정의됩니다. 여기서, REGION = EAST를 충족하는 행은 한 위치에 복제되고 REGION = WEST를 충족하는 행은 다른 위치에 복제됩니다. 파티션 scheme 이름은 "Sales_by_region"일 수 있습니다.
타겟 테이블에 더 빠르게 게시하기 위해 다중 행 파티션을 사용하여 테이블의 행을 병렬 처리 스트림(병렬 Export-Import-Post 스트림)으로 나눕니다. 예를 들어 크게 업데이트된 타겟 테이블에 대한 복제 흐름을 개선할 수 있습니다. 이 목적으로 컬럼 조건을 사용하는 것은 병렬 Post 프로세스 간에 처리를 균등하게 분할할 수 있는 컬럼(기본 또는 null이 아닌 유니크 키를 사용하는 것을 권장)이 테이블에 포함된 경우에만 적합합니다.
수평으로 파티셔닝된 복제와 수직으로 파티셔닝된 복제를 결합하여 정보가 배포되는 방식을 최대한 제어할 수 있습니다.
예를 들면 다음과 같습니다.
수평으로 파티셔닝된 복제는 동일한 테이블에 대한 전체 테이블 복제와 함께 사용할 수 있습니다. 예를 들어 행 그룹을 다른 보고 시스템으로 라우팅하고 모든 행을 백업 시스템으로 라우팅할 수 있습니다.
add partition 명령을 사용하여 행 파티션을 만들고 이를 파티션 scheme에 할당할 수 있습니다.
컬럼 조건에 따라 행을 파티셔닝하려면 다음을 수행합니다.
지정된 파티션 scheme에서 생성할 각 행 파티션에 대해 add partition을 실행합니다. 첫 번째 행 파티션을 생성할 때 SharePlex는 파티션 scheme도 생성합니다.
sp_ctrl> add partition to scheme_name setcondition = column_condition and route = routing_map [and name = name] [and tablename =schema.table] [and description =description]
참고: add partition과 toScheme_name 및 set 키워드를 지정하면 다른 모든 구성 요소는 순서에 관계없이 가능합니다.
| 구성 요소 | 설명 |
|---|---|
| to scheme_name |
to는 scheme_name에 행 파티션이 추가됨을 나타내는 필수 키워드입니다. scheme_name은 파티션 scheme의 이름입니다. 파티션 scheme은 사용자가 실행하는 첫 번째 add partition 명령에 의해 생성되며, 파티셔닝할 첫 번째 행 집합도 지정합니다. 수평 파티셔닝을 많이 사용하는 경우 파티션 scheme에 대한 명명 규칙을 설정하는 것이 도움이 될 수 있습니다. |
|
set |
행 파티션 정의를 시작하는 필수 키워드입니다. |
| condition = column_condition |
컬럼 조건에 따라 행 파티션을 생성합니다. 조건은 따옴표로 묶어야 합니다. ((region_id = West) and region_id is not null)과 같은 표준 WHERE 조건부 구문을 사용합니다. |
| route = routing_map |
이 파티션의 경로입니다. 이는 다음 중 하나일 수 있습니다. 컬럼 조건에 따른 파티션: 표준 SharePlex 라우팅 맵을 지정합니다(예: sysB@r.dbname, sysB:q1@r.dbname 또는 sysB@r.dbname+sysC@r.dbname(복합 라우팅 맵)). 이름이 다른 여러 타겟 테이블로 파티션을 라우팅하려면 다음을 수행합니다.
|
| name = name |
(권장) 이 파티션의 짧은 이름입니다. 이 옵션은 컬럼 조건을 기반으로 하는 파티션에만 유용합니다. 짧은 이름을 사용하면 나중에 파티션을 수정하거나 삭제해야 하는 경우 긴 컬럼 조건을 입력할 필요가 없습니다. |
| tablename = schemaname.table |
(선택 사항) 타겟 테이블이 여러 개 있고 하나 이상의 이름이 다른 경우 이 옵션을 사용합니다. 각 이름에 대해 별도의 add partition 명령을 실행합니다. 테이블 이름은 정규화되어야 합니다. 대소문자를 구분하는 경우 이름을 따옴표로 묶어 지정해야 합니다. 예: add partition to scheme1 set name = p1 and condition = "C1 > 200" and route = sysb:p1@r.dbname and tablename = myschema.mytable |
| description = description | (선택 사항) 이 파티션에 대한 설명입니다. |
여러 Post 큐를 통해 다양한 행 집합 라우팅:
sp_ctrl> add partition to scheme1 set name = q1 and condition = "C1 >= 200" and route = sysb:q1@r.dbname
sp_ctrl> add partition to scheme1 set name = q2 and condition = "C1 < 200" and route = sysb:q2@r.dbname
여러 행 집합을 소스의 다양한 타겟 시스템과 다양한 테이블 이름으로 라우팅합니다.
sp_ctrl> add partition to scheme1 set name = east and condition = "area = east" and route = sys1e@r.dbname and tablename = schema1.targ
sp_ctrl> add partition to scheme1 set name = west and condition = "area = west" and route = sys2w@r.dbname and tablename = schema2.targ
다음은 컬럼 조건 생성에 대한 가이드라인입니다.
컬럼 조건의 기반이 되는 컬럼 유형은 데이터 소스에 따라 다릅니다.
PRIMARY 또는 UNIQUE 키 컬럼과 같이 값이 변경되지 않는 컬럼에 대한 기본 컬럼 조건입니다. 목표는 파티션 이동을 방지하는 것입니다. 여기서, 파티션의 조건부 컬럼을 변경하면 기본 데이터가 다른 파티션의 조건을 충족하거나 충족하지 않을 수 있습니다.
파티션 이동 사례 1: 새 값이 더 이상 컬럼 조건을 충족하지 않도록 컬럼 값이 업데이트됩니다.
파티션 이동 사례 2: 하나의 컬럼 조건을 충족하는 행이 다른 조건을 충족하도록 업데이트됩니다.
또한 구성 파일을 활성화하기 전에 소스에 다음과 같은 매개변수를 설정하여 데이터가 제대로 복제되는지 확인할 수 있습니다.
참고: 컬럼 조건에 따라 키가 아닌 컬럼을 사용하고 수평으로 파티셔닝된 복제를 활성화하여 성능이 저하되는 경우, 해당 컬럼에 대한 로그 그룹을 추가합니다. PostgreSQL에서는 복제본 ID를 FULL로 설정하여 이 매개변수를 사용할 수 있습니다.
SharePlex는 컬럼 조건에서 다음과 같은 데이터 유형을 지원합니다.
SMALLINT
INT
BIGINT
NUMERIC
CHAR (<=2000 in length)
VARCHAR (1<=4000 in length)
DATE
BOOLEAN (condition = "column_name =1" or condition = "column_name = 0")
참고:
|
다음 목록은 컬럼 조건에서 SharePlex가 지원하는 조건부 구문을 보여줍니다. 여기서,
|
column = value
not (column = value)
column > value
value > column
column < value
column <= value
column >= value
column <> value
column != value
column like value
column between value1 and value2
not (column between value1 and value2 )
column is null
column is not null |
조건은 괄호와 AND, OR 및 NOT 논리 연결을 사용하여 중첩된 표현식으로 결합할 수 있습니다.
다음을 수행하지 마십시오.
전체 테이블 복제가 있는 테이블과 파티셔닝된 복제를 사용할 테이블을 포함하여 지정된 데이터 소스에서 복제할 모든 데이터에 대해 하나의 구성 파일을 사용합니다.
| Datasource:r.dbname | ||
| srcschemaname.table | targetschemaname.table |
!partition_scheme |
| ! | routing_map | |
| 구성 요소 | 설명 | |
|---|---|---|
|
r.dbname |
데이터 소스 지정입니다. PostgreSQL 소스에 r. 표기법을 사용합니다. | |
| src_schema.table 및 tgt_schema.table | 각각 소스 및 타겟 테이블의 사양입니다. | |
| !partition_scheme |
지정된 소스 및 타겟 테이블에 사용할 파티션 scheme의 이름입니다. ! 기호가 필요합니다. 이름은 대소문자를 구분합니다. 여러 파티션 scheme의 복합 라우팅은 지원되지 않습니다(예: !schemeA+schemeB). 동일한 소스 테이블에 사용할 각 파티션 scheme에 대해 별도의 항목을 만듭니다. 예를 참조하십시오. | |
| ! routing_map |
자리 표시자 라우팅 맵입니다. 이 맵은 파티션 scheme에 사용한 경로가 구성 파일의 어딘가에 나열되지 않은 경우에만 필요합니다. SharePlex는 파티션 scheme에 나와 있더라도 모든 경로가 구성 파일에 있어야 합니다.
|
파티션 scheme을 지정하려면 다음을 수행합니다.
| Datasource: r.mydb | ||
| scott.emp | scott.emp_2 | !partition_emp |
동일한 소스 테이블에 대해 여러 파티션 scheme을 지정하려면 다음을 수행합니다.
| Datasource: r.mydb | ||
| scott.emp | scott.emp_2 | !partition_schemeA |
| scott.emp | scott.emp_3 | !partition_schemeB |
자리 표시자 라우팅 맵을 지정하려면 다음을 수행합니다.
| ! targsys1 |
| ! targsys2@r.dbname2+targsys3@r.dbname3 |
이 자리 표시자는 컬럼 조건을 기반으로 하는 파티션에만 필요합니다.
view partitions 명령을 사용하면 하나의 파티션 scheme의 행 파티션을 보거나 수평으로 파티셔닝된 복제 구성의 모든 파티션 scheme을 볼 수 있습니다.
행 파티션을 보려면 다음을 수행합니다.
모든 파티션을 보려고 하거나 특정 파티션 scheme의 파티션만 보려는지 여부에 따라 두 옵션 중 하나를 사용하여 다음 명령을 실행합니다.
sp_ctrl>view partitions for {scheme_name | all}
다음 예에서는 컬럼 기반 파티션 scheme을 보여줍니다.
sp_ctrl> view partitions all
| scheme | Name | Route | Tablename | Condition |
|---|---|---|---|---|
| product | lessQuantity | 10.250.40.27@r.testdb | splex.prod_1 | id between 1 and 100 |
| product | moreQuantity | 10.250.40.27@r.testdb | splex.prod_2 | id between 101 and 200 |
| product | largeQuantity | 10.250.40.27@r.testdb | splex.prod_3 | id between 201 and 300 |
| sales_by_region | east | 10.250.40.27@r.testdb | splex.sales_dst1 | ((region = 'East') and region is not null) |
| sales_by_region | west | 10.250.40.27@r.testdb | splex.sales_dst2 | ((region = 'west') and region is not null) |
| city_scheme | Pune | 10.250.40.27:pune_queue@r.testdb | splex.student_target1 | ((stud_name = 'Pune') and stud_name is not null) |
| city_scheme | Mumbai | 10.250.40.24:mumbai_queue@r.testdb | splex.student_target2 | ((stud_name = 'Mumbai') and stud_name is not null) |
city_scheme column-based partition scheme
파티션 Post 큐를 보려면 다음을 수행합니다.
타겟의 qstatus 명령은 수평으로 파티셔닝된 복제와 관련된 Post 큐를 표시합니다.
sp_ctrl (pslinuxpgsp11:2200)> qstatus
Queues Statistics for pslinuxpgsp11
Name: pune_queue (r.testdb-r.testdb) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)sp_ctrl (pslinuxpgsp08:2200)> qstatus
Queues Statistics for pslinuxpgsp08
Name: mumbai_queue (r.testdb-r.testdb) (Post queue)
Number of messages: 0 (Age 0 min; Size 1 mb)
Backlog (messages): 0 (Age 0 min)
파티션 scheme을 관리하는 데 다음 명령이나 매개변수를 사용할 수 있습니다. 자세한 내용은 SharePlex 참조 안내서를 참조하십시오.
|
작업 |
명령/매개변수 |
설명 |
|---|---|---|
|
파티션 수정 |
modify partition 명령 |
행 파티션 정의의 속성을 수정합니다. |
|
파티션 scheme 제거 |
drop partition scheme 명령 |
파티션 scheme과 scheme 내에 있는 모든 행 파티션을 제거합니다. |
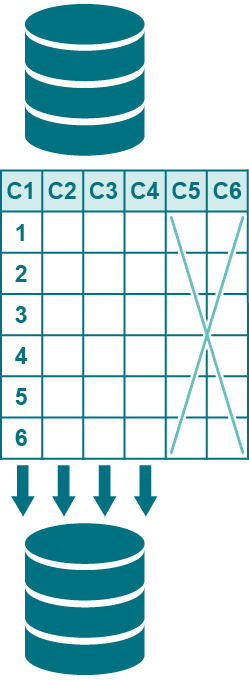
수직으로 파티셔닝된 복제를 사용하여 테이블 컬럼의 하위 집합을 복제합니다. 예를 들어 다이어그램에 표시된 것처럼 C1, C2, C3, C4에 대한 데이터 변경 사항을 복제할 수 있지만 C5 및 C6에 대한 변경 사항은 복제할 수 없습니다.
PostgreSQL에서 PostgreSQL, Oracle, SQL Server 및 Kafka로
Oracle에서 모든 타겟으로
PGDB as a Service에서 PGDB as a Service로
PGDB as a Service에서 Oracle로
PGDB as a Service에서 PostgreSQL로
수직으로 파티셔닝된 복제를 포함하는 구성 파일을 생성할 때 다음 가이드라인을 따릅니다.
수직으로 파티셔닝된 복제는 보고 및 기타 데이터 공유 전략에 적합하지만 고가용성 환경에는 적합하지 않습니다. 수직으로 파티셔닝된 복제를 위해 테이블을 구성하면 SharePlex는 다른 컬럼을 인식하지 못하므로 해당 컬럼의 데이터가 복제되지 않습니다.
수평으로 파티셔닝된 복제와 수직으로 파티셔닝된 복제를 결합하여 배포되는 정보와 배포 위치를 최대한 제어할 수 있습니다.
예: 회사에는 본사와 지역 부서가 있습니다. 본사는 기업 데이터베이스를 유지 관리하고 각 지역 부서는 지역 데이터베이스를 유지 관리합니다. 본사는 수직으로 파티셔닝된 복제를 사용하여 테이블의 컬럼 데이터 중 일부를 해당 위치와 공유하며, 다른 민감한 데이터는 본사에 보관합니다. 공유 컬럼에 대한 행 변경 사항은 적절한 지역 데이터베이스에 복제하기 위해 수평으로 추가로 파티셔닝됩니다.
수직으로 파티셔닝된 복제를 구성하려면 구성 파일에 컬럼 파티션 또는 제외 컬럼 파티션을 지정합니다.
두 유형의 컬럼 파티션을 지정하려면 다음 규칙을 따릅니다.
수직으로 파티셔닝된 복제에 대한 항목을 구성하려면 다음 구문을 사용합니다. 구성 파일을 생성하는 방법에 대한 자세한 내용은 데이터 복제를 위해 SharePlex 구성을 참조하십시오.
| datasource_specification | ||
|
# table specification with column partition | ||
|
src_owner.table (src_col,src_col,...) |
tgt_owner.table [(tgt_col,tgt_col,...)] | routing_map |
|
# table specification with exclusion column partition | ||
| src_owner.table !(src_col,src_col,...) | tgt_owner.table | routing_map |
| 구성 구성 요소 | 설명 |
|---|---|
| src_owner.table 및 tgt_owner.table | 각각 소스 및 타겟 테이블의 사양입니다. |
|
(src_col, src_col,...) |
복제에 포함할 컬럼을 나열하는 컬럼 파티션을 지정합니다. 복제 시작 후 추가된 컬럼의 데이터를 포함하여 다른 컬럼 데이터는 복제되지 않습니다(DDL 복제가 활성화된 것으로 가정). |
|
!(src_col,src_col,...) |
복제에서 제외할 컬럼을 나열하는 제외 컬럼 파티션을 지정합니다. 복제 시작 후 추가된 컬럼의 데이터를 포함하여 다른 모든 컬럼 데이터는 복제되지 않습니다(DDL 복제가 활성화된 것으로 가정). 참고: 제외 컬럼 파티션을 사용하는 경우 해당 소스 및 타겟 컬럼 이름이 동일해야 하며 제외된 컬럼은 키 정의에 사용할 수 없습니다. 자세한 내용은 유니크 키 정의 를 참조하십시오. |
| (tgt_col,tgt_col,...) |
타겟 컬럼입니다. 소유자나 이름이 다른 타겟 컬럼에 소스 컬럼을 매핑하려면 이 옵션을 사용합니다. 소스 컬럼과 타겟 컬럼의 소유자나 이름이 동일한 경우 타겟 컬럼을 생략할 수 있습니다. 소스 컬럼을 타겟 컬럼에 매핑하려면 다음 규칙을 따릅니다.
|
| routing_map |
컬럼 파티션의 라우팅 맵입니다. 라우팅 맵은 다음 중 하나일 수 있습니다.
중요! 여러 타겟을 별도의 항목에 나열하지 않고 복합 라우팅 맵을 사용해야 합니다. 소스 테이블당 하나의 컬럼 조건만 구성 파일에 나열될 수 있기 때문입니다. 복합 라우팅 맵을 사용하려면 모든 타겟 테이블의 소유자와 이름이 동일해야 합니다. 자세한 내용은 구성 파일의 라우팅 사양을 참조하십시오. |
다음은 복합 라우팅 맵을 사용하여 여러 타겟에 복제하는 수직으로 파티셔닝된 복제 구성입니다. 이 소스 테이블에 복합 라우팅 맵을 사용하려면 모든 타겟의 이름을 scott.sal로 지정해야 합니다.
| Datasourceo.oraA | ||
| scott.emp (c1,c2) | scott.sal |
sysB@o.oraB+sysC@o.oraC |
다음은 단일 타겟에 복제하는 수직으로 파티셔닝된 복제 구성이며, 여기서 타겟 컬럼의 이름은 소스의 이름과 다릅니다.
| Datasourceo.oraA | ||
| scott.emp (c1,c2) | scott.sal (c5,c6) |
sysB@o.oraB |
다음 구성 파일은 구성 파일에서 scott.emp (c1, c2)의 동일한 컬럼 파티션을 두 번 반복하기 때문에 유효하지 않습니다.
| Datasourceo.oraA | ||
| scott.emp (c1,c2) | scott.cust (c1,c2) |
sysB@o.oraB |
| scott.emp (c1,c2) | scott.sales (c1,c2) | sysC@o.oraC |
PostgreSQL, Oracle, SQL Server 및 Kafka
참고: PostgreSQL-SQL Server 복제는 수직으로 파티셔닝된 데이터에 대해 BOOLEAN, TIME, TIME WITH TIME ZONE 및 BYTEA 데이터 유형을 지원하지 않습니다.
수직으로 파티셔닝된 복제를 구성하려면 다음을 수행합니다.
수직으로 파티셔닝된 복제를 구성하려면 구성 파일에 컬럼 파티션 또는 제외 컬럼 파티션을 지정합니다.
두 유형의 컬럼 파티션을 지정하려면 다음 규칙을 따릅니다.
수직으로 파티셔닝된 복제에 대한 항목을 구성하려면 다음 구문을 사용합니다.
| datasource_specification | ||
|
# table specification with column partition | ||
|
src_schema.table (src_col,src_col,...) |
tgt_schema.table [(tgt_col,tgt_col,...)] | routing_map |
|
# table specification with exclusion column partition | ||
| src_schema.table !(src_col,src_col,...) | tgt_schema.table | routing_map |
| 구성 구성 요소 | 설명 |
|---|---|
| src_schema.table 및 tgt_schema.table | 각각 소스 및 타겟 테이블의 사양입니다. |
| (tgt_col,tgt_col,...) |
타겟 컬럼입니다. 스키마나 이름이 다른 타겟 컬럼에 소스 컬럼을 매핑하려면 이 옵션을 사용합니다. 소스 컬럼과 타겟 컬럼의 스키마나 이름이 동일한 경우 타겟 컬럼을 생략할 수 있습니다. 소스 컬럼을 타겟 컬럼에 매핑하려면 다음 규칙을 따릅니다.
|
| routing_map |
컬럼 파티션의 라우팅 맵입니다. 라우팅 맵은 다음 중 하나일 수 있습니다.
중요! 여러 타겟을 별도의 항목에 나열하지 않고 복합 라우팅 맵을 사용해야 합니다. 소스 테이블당 하나의 컬럼 조건만 구성 파일에 나열될 수 있기 때문입니다. 복합 라우팅 맵을 사용하려면 모든 타겟 테이블의 스키마와 이름이 동일해야 합니다. |
다음은 복합 라우팅 맵을 사용하여 여러 타겟에 복제하는 수직으로 파티셔닝된 복제 구성입니다. 이 소스 테이블에 복합 라우팅 맵을 사용하려면 모든 타겟의 이름을 scott.sal로 지정해야 합니다.
| Datasource: r.dbname | ||
| scott.emp (c1,c2) | scott.sal |
sysB@r.dbname1 + sysC@r.dbname2 |
다음은 단일 타겟에 복제하는 수직으로 파티셔닝된 복제 구성이며, 여기서 타겟 컬럼의 이름은 소스의 이름과 다릅니다.
| Datasource: r.dbname | ||
| scott.emp (c1,c2) | scott.sal (c5,c6) |
sysB@r.dbname1 |
다음 구성 파일은 구성 파일에서 scott.emp (c1, c2)의 동일한 컬럼 파티션을 두 번 반복하기 때문에 유효하지 않습니다.
| Datasource: r.dbname | ||
| scott.emp (c1,c2) | scott.cust (c1,c2) |
sysB@r.dbname1 |
| scott.emp (c1,c2) | scott.cust (c1,c2) | sysC@r.dbname2 |
이 장에는 변경 내역 타겟을 유지하기 위해 SharePlex를 구성하는 방법에 대한 지침이 포함되어 있습니다. SharePlex를 사용하면 이 내역을 유지하는 한편 동일한 데이터 세트를 복제하여 최신 타겟을 유지할 수 있습니다.