Understanding the concept of synchronization
Understand the Concept of Synchronization
The concept of synchronization applies mainly to table-to-table replication, where Post performs integrity checks to make certain that only one row in the target matches the row change that is being replicated. It does not apply to file, messaging targets, and change-history targets, which contain a record of every operation replicated by Post, some of which may be identical over time. The Post process does not perform integrity checks on those targets.
Characteristics of synchronized tables
The basic characteristics of synchronized source and target tables are as follows (unless the transformation feature is used).
- If a row exists in the source database, it exists in the target.
- Corresponding columns in source and target tables have the same structure and data types.
- Data values in corresponding rows are identical, including the values of the key.
Ensuring data integrity is the responsibility of the Post process. Post applies a WHERE clause to compare the key values and the before values of the SQL operations that it processes. Post uses the following logic to validate synchronization between source and target tables:
-
Post applies a replicated INSERT but a row with the same key already exists in the target. Post applies the following logic:
- If all of the current values in the target row are the same as the INSERT values, Post considers the rows to be in-sync and discards the operation.
- If any of the values are different from those of the INSERT, Post considers this an out-of-sync condition.
Note: You can configure Post so that it does not consider non-key values when posting an INSERT (applicable only when replicating data from Oracle to Oracle). See the SP_OPO_SUPPRESSED_OOS parameter in the SharePlex Reference Guide.
-
Post applies a replicated UPDATE but either cannot find a row in the target with the same key value as the one in the UPDATE or Post finds the correct row but the row values do not match the before values in the UPDATE. Post applies the following logic:
- If the current values in the target row match the after values of the UPDATE, Post considers the rows to be in-sync and discards the operation.
- If the values in the target row do not match the before or after values of the UPDATE, Post considers this an out-of-sync condition.
Note: You can configure Post so that it returns an out-of-sync message if the current values in the target row match the after values of the UPDATE (applicable only when replicating data from Oracle to Oracle). See the SP_OPO_SUPPRESSED_OOS parameter in the SharePlex Reference Guide.
- A DELETE is performed on the source data, but Post cannot locate the target row by using the key. When Post constructs its DELETE statement, it includes only the key value in its WHERE clause. If the row does not exist in the target, Post discards the operation.
Hidden out-of-sync conditions
Post only verifies the integrity of the rows that are being changed by its current SQL operation. It does not verify whether other rows in that table, or in other tables, are out of synchronization in the target database. A hidden out-of-sync condition may not show up until much later, when a change to the affected row is eventually replicated by SharePlex or a discrepancy is detected in the course of using that data.
Example of a detectable out-of-sync condition
Someone logs into the target and updates the COLOR column in the target table from “blue” to “red” in Row1. Then, an application user on the source system makes the same change to the source table, and SharePlex replicates it to the target. In the WHERE clause used by Post, the pre-image for the target table is “blue,” but the current value in the target row is “red.” Post generates an out-of-sync error alerting you to the out-of-sync condition.
Example of a hidden out-of-sync condition
Someone logs into the target and updates the COLOR column in the target table from “blue” to “red” in Row2, but the change is not made to the source table and is not replicated. The two tables are now out-of-sync, but Post does not return an error message, because there is no replication performed on that row. No matter how many subsequent updates are made to other columns in the row (SIZE, WEIGHT), the hidden out-of-sync condition for the COLOR column persists (and users on the target have inaccurate information) until someone updates the COLOR column in the source table. When that change is replicated, only then does Post compare the pre-images and return an error message.
The majority of time, the cause of out-of-sync data is not anything done wrong by replication, but rather DML applied on the target, an incomplete backup restore, or some other hidden out-of-sync condition, which goes undetected until replication affects the row. Solving out-of-sync conditions can be time-consuming and disruptive to user activity. Once replication is started, it is recommended that you:
- Prevent write access to the target tables, so that DML and DDL cannot be applied to them.
- Use the compare command to compare source and target data regularly to verify synchronization and detect hidden out-of-sync conditions. You can use the repair command to repair any out-of-sync rows. For more information about these commands, see the SharePlex Reference Guide.
How SharePlex responds to an out-of-sync condition
You can decide how you want SharePlex to respond to transactions that generate an out-of-sync error:
-
The default Post behavior when a transaction contains an out-of-sync operation is to continue processing other valid operations in the transaction to minimize latency and keep targets as current as possible. Latency is the amount of time between when a source transaction occurs and when it is applied to the target. Different factors affect the amount of latency in replication, such as unusually high transaction volumes or interruptions to network traffic.
Post logs the SQL statement and data for the out-of-sync operation to the ID_errlog.sql log file, where ID is the database identifier. This file is in the log sub-directory of the variable-data directory on the target system.
-
You can configure Post to stop when it encounters an out-of-sync condition by setting the following parameter to 1:
- Oracle targets: SP_OPO_OUT_OF_SYNC_SUSPEND
- Open Target targets: SP_OPX_OUT_OF_SYNC_SUSPEND
-
You can configure Post to roll back and discard a transaction if any operation in that transaction generates an out-of-sync error. The entire transaction is logged to a SQL file, but not applied to the target.You can edit the SQL file to fix the invalid DML and then run the SQL file to apply the transaction. This feature is enabled by setting the SP_OPO_SAVE_OOS_TRANSACTION to 1.
Strategies for information availability
With SharePlex, you can put a replica database to work as a reliable, continuously updated alternate database that can be used in many different ways. The following strategies enable you to get the right data to the people who need it, when they need it.
Note: Support for these topologies may vary depending on the type of database involved.
Figure 1: SharePlex replication strategies at a glance
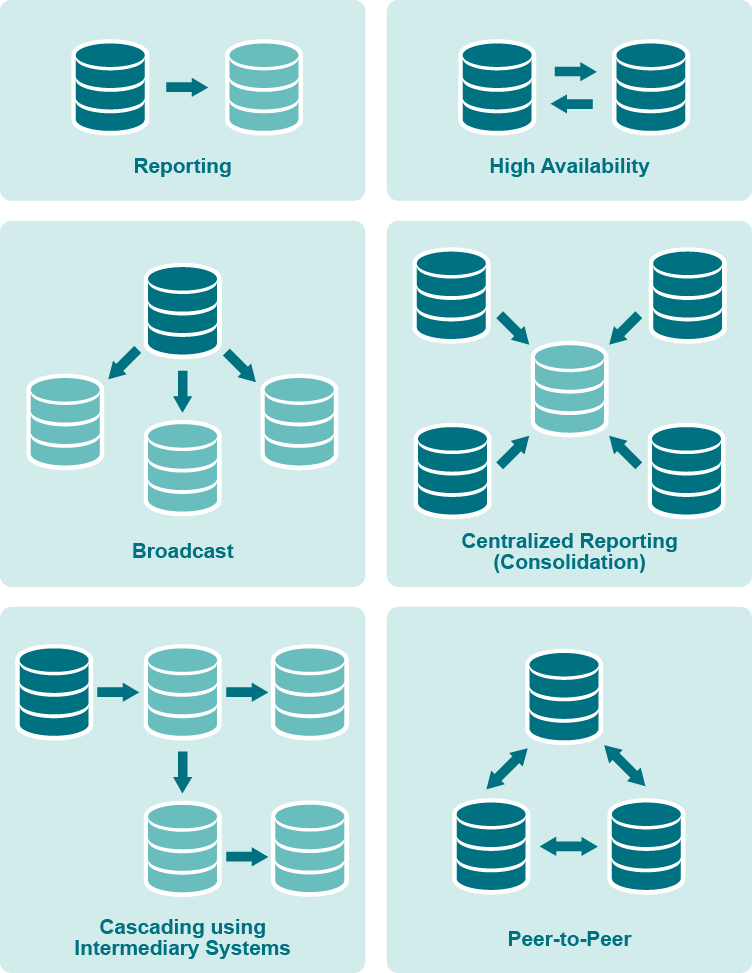
Reporting instances
Targets maintained by SharePlex are ideal for offloading report and query processing because they are accessible while being kept up-to-date, and they can be optimized with keys and indexes designed for optimal query performance. You can run reports all day long, without complaints about performance from your OLTP users. Even during busy reporting times such as the end of the month or quarter, application response time will be unaffected by heavy reporting. And, your organization’s decision-makers will appreciate the accuracy of the data reflected in the reports. For more information, see Configure Replication to Share or Distribute Data.
Broadcast and cascade
When many remote users access or use data stored in a primary database, you can move their processing to one or more secondary databases that are kept current through SharePlex replication. That way, you can keep the primary database and system optimized for transactions. SharePlex also can cascade data through an intermediary system to remote systems, providing access for remote users who have no direct network connection to the primary database. For more information, see Configure Replication through an Intermediary System
Data warehousing
SharePlex can replicate from numerous source systems to one target system. This configuration is ideal for consolidating data in a data warehouse or a data mart so that information is available enterprise-wide for queries and reports. You have control over the data that is replicated and the option to transform any data to conform to a different target structure. These capabilities enable you to populate your data warehouse with the specific, timely information that users need to make good decisions. For more information, see Configure Replication to Maintain a Central Datastore.
High availability and disaster recovery
SharePlex can be used to maintain duplicate databases over local or wide-area networks. Production can move to the alternate sites in an emergency or in a planned manner when routine maintenance is performed on the primary server. SharePlex replication enables the secondary database to be used for queries and reporting. For more information, see Configure Replication to Maintain High Availability.
Peer-to peer
SharePlex supports replication among multiple source databases where applications on each system can make changes to the same data while SharePlex maintains synchronization. In this strategy, the databases are usually mirror images of each other, with all objects existing in their entirety on all systems. Although similar in benefit to a high-availability strategy, the difference between the two is that peer-to-peer allows concurrent changes to the same data, while high availability permits changes to the secondary database only in the event that the primary database goes offline. A few ways to use peer-to-peer replication are to maintain the availability and flexibility of a database by enabling access from different locations or to distribute heavy online transaction processing volumes among multiple access points. For more information, see Configure Peer-to-Peer Replication .
Test before you deploy
Before you implement SharePlex on production systems, make certain to perform tests in a mirror of the production environment to ensure that you configured SharePlex properly to support your requirements. Testing can uncover issues such as configuration errors and unexpected environmental issues, for example network or resource issues that affect replication performance or availability.
Additionally, it is assumed that your organization has in place an infrastructure that supports the use of enterprise applications such as SharePlex. These include, but are not limited to, the following:
- Availability and use of the database and SharePlex documentation
- Training programs for users
- Rollout and upgrade plans that ensure minimal interruption to business. When SharePlex is implemented as part of an application’s infrastructure, it is strongly recommended to test new application functionality in conjunction with SharePlex in a non-production environment.
- Database or system maintenance procedures that consider SharePlex dependencies, such as the proper shutdown of SharePlex processes and the preservation of unprocessed transaction records and replication queues to accommodate system or database maintenance.
- Sufficient security that prevents unauthorized persons from accessing SharePlex data records or making configuration changes.
The SharePlex Professional Services team can help you prepare for, install, and deploy SharePlex in your environment.
Run SharePlex
This chapter contains instructions for running SharePlex on UNIX and Linux.
Contents
Run SharePlex on UNIX
Run SharePlex on Unix and Linux
On Unix and Linux systems, you start SharePlex by running the sp_cop program. After you activate a configuration, sp_cop spawns the necessary child replication processes on the same system. Each instance of sp_cop that you start is a parent to its own set of child replication processes. The sp_cop process must be started on each system that is part of the replication configuration.
You can start sp_cop in one of two ways:
- From the operating system command line.
- At system startup as part of the startup file.
IMPORTANT: Run SharePlex from either the korn (ksh) or C shell (csh) shell.
- Do not use the Bourne shell (sh), because the way it handles background processes is not compatible with SharePlex. If you must use the Bourne shell, switch shells to ksh or csh to run SharePlex, then exit the shell and return to the Bourne shell.
- If using an Exceed X window emulator, switch from the default shell of POSIX to the ksh shell, then run sp_cop from the ksh shell only.
Startup sequence on Unix and Linux
When you start systems that are involved in replication, start the components in this order:
- Start the system.
- Start the source and target databases.
- Start SharePlex.
- Start sp_ctrl.
-
Verify that the SharePlex processes are started by issuing the lstatus command in sp_ctrl.
sp_ctrl> lstatus
- Allow users on the system.
Start SharePlex on Unix and Linux
To start SharePlex, you must log onto the system as a SharePlex Administrator. Your user name must be assigned to the SharePlex admin group in the /etc/group file. For more information, see Assign SharePlex Users to Security Groups.
Table 1: SharePlex startup syntax
| From root, with full path |
$ /productdir/bin/sp_cop [-uidentifier] & |
| CD to the product directory |
$ cd /productdir/bin
$./sp_cop [-uidentifier] & |
| From a startup script |
#!/bin/ksh
cd productdir\bin
nohup sp_cop [-uidentifier] & |
Table 2: Description of SharePlex startup syntax
| & |
Causes SharePlex to run in the background. |
| nohup |
Directs the startup of SharePlex to continue in the background after the current user logs out. |
| -uidentifier |
Starts sp_cop with a unique identifier. Use this option when there are multiple instances of sp_cop running on a system, which is required for some SharePlex configurations. For more information, see Run Multiple Instances of SharePlex.
Some suggestions for identifier are:
- the SharePlex port number (such as -u2100)
- the identifier of the database for which replication is running (such as -uora12c)
- any descriptive identifier (such as -utest)
|
Identify SharePlex processes on Unix and Linux
Every session of sp_cop has a process ID number. The ID is returned after startup and then the command prompt reappears. If a configuration was activated during a former session of sp_cop, replication begins immediately. Without an active configuration, sp_cop runs passively in the background.
On Unix and Linux systems, you can use the ps -ef | grep sp_ command to view the SharePlex processes that are running.
Each child process has the same -uidentifier as its parent sp_cop process. This makes it easier to identify related processes when multiple session of sp_cop are running.
Stop SharePlex on Unix and Linux
To stop SharePlex, issue the shutdown command in sp_ctrl. This is a graceful shutdown that saves the state of each process, performs a checkpoint to disk, read/releases buffered data, and removes child processes. Data in the queues remains safely in place, ready for processing when sp_cop starts again. The shutdown process can take some time if SharePlex is processing large operations.
You can use the force option with the shutdown command to forcefully shut down replication if necessary. It terminates sp_cop immediately, bypassing normal shutdown procedures. See the SharePlex Reference Guide for more information about this command.
Shutdown considerations on Unix and Linux
You can safely shut down SharePlex for a short time while there is still transactional activity. The next time you start SharePlex, replication resumes at the correct place in the redo logs or the archive logs, if needed. However, the best practice is to leave SharePlex running while there is transactional activity. Otherwise, SharePlex may need to process a large volume of redo backlog when you start it again, and there will be latency between the source and target data.
If the redo logs wrap and the archive logs cannot be accessed, resynchronization of the source and target data may be the only option. Take this possibility into account whenever you stop SharePlex while redo is still being generated.
Note: If you want to shut down both SharePlex and the database, shut down SharePlex first. Otherwise, SharePlex will interpret that the database is failing and generate a warning message.
As an alternative to stopping SharePlex, you can use the stop command in sp_ctrl to stop individual SharePlex replication processes as needed. See the SharePlex Reference Guide for more information about this command.
