This section describes the following topics:
|
1 |
On the navigation panel, under Dashboards, click the Insights tab, and then click Live Troubleshooter. |
|
4 |
|
5 |
Click Perform Analysis. |
|
• |
If a Normal |
|
• |
If the Attention |
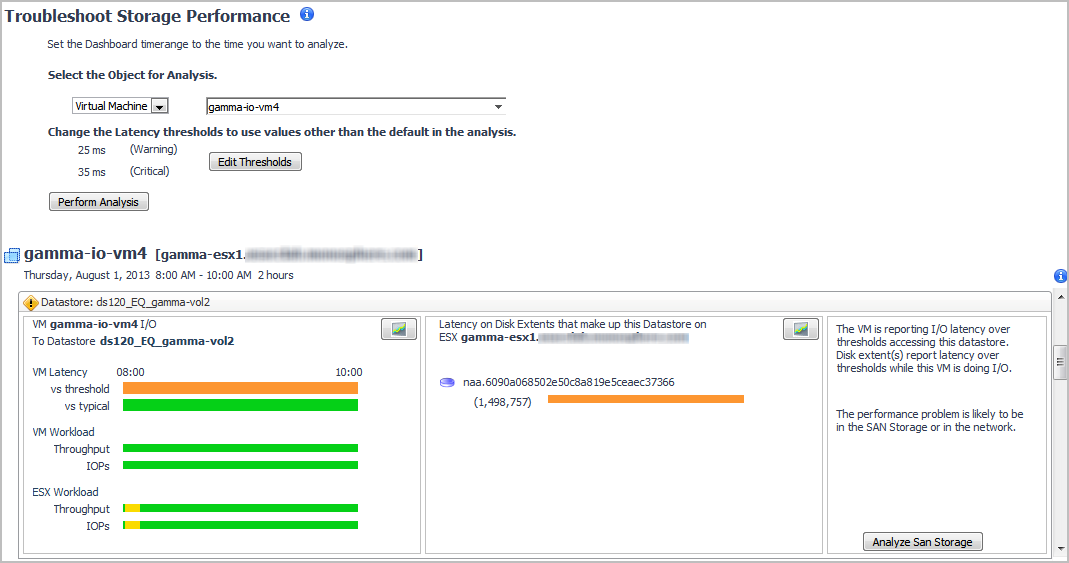
If the view for a datastore or RDM disk extent shows the Attention icon, the troubleshooting algorithm has discovered evidence of a performance problem related to storage. The problem may or may not be in the SAN Storage environment. Review the details to determine the cause of the performance issue.
Each datastore/RDM view has three summary panels (from left to right):
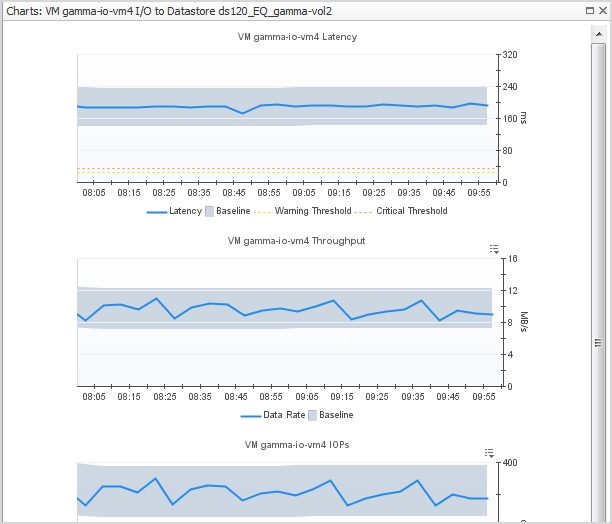
A virtual machine may be connected to multiple datastores and RDM disk extents, each of which may report varying degrees of problems. When a virtual machine has more than one datastore/RDM view, start by scanning the timeline bars in the VM I/O to Datastore/RDM panel to identify a datastore/RDM with consistently slow I/O performance or significant changes from typical performance.
|
1 |
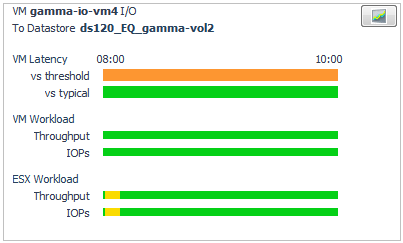
In a view showing the Attention |
|
2 |
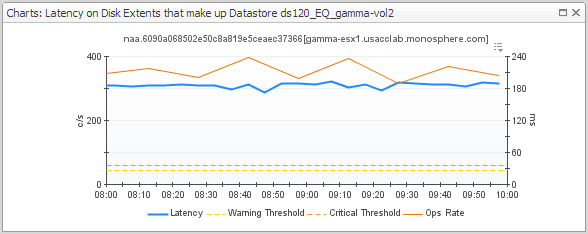
Now look at the Latency for Disk Extents summary (middle panel) to identify the disk extents that are contributing to the problem. |
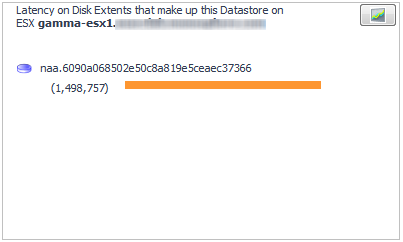

|
a |
|
c |
|
5 |
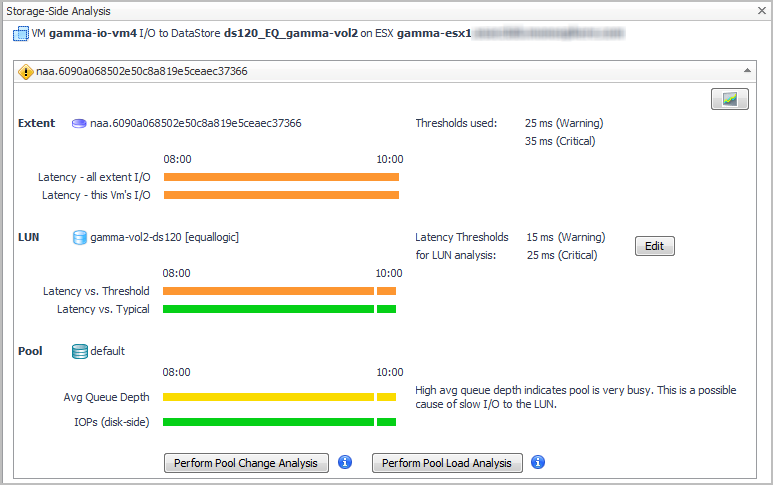
In the Diagnosis panel, click Analyze SAN Storage. |
|
• |
|
• |
Perform Pool Change Analysis. The Pool Change analyzer identifies the LUNs primarily responsible for increased I/O. It compares LUN activity in the problem time range with LUN activity during the same time range in the past. Changes are reported in terms of average operations rate and change amount. |
|
• |
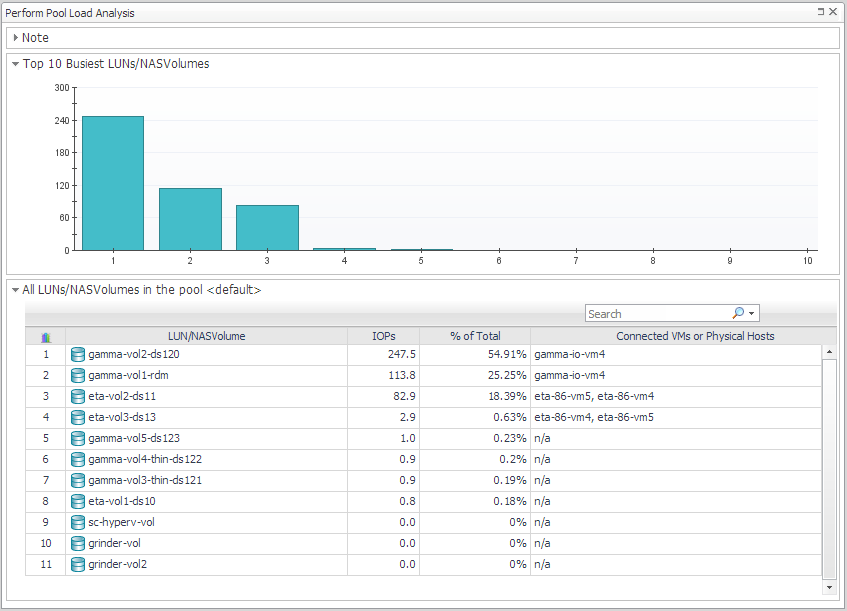
Perform Pool Load Analysis. The Pool Load analyzer identifies the busiest LUNs and ranks them based on their activity during the same time range over the last 30 days (not the current time frame). Activity is measured in operations per second. |
|
1 |
From the Server-Side Analysis window or the Pool Explorer window, click Perform Pool Change Analysis. |
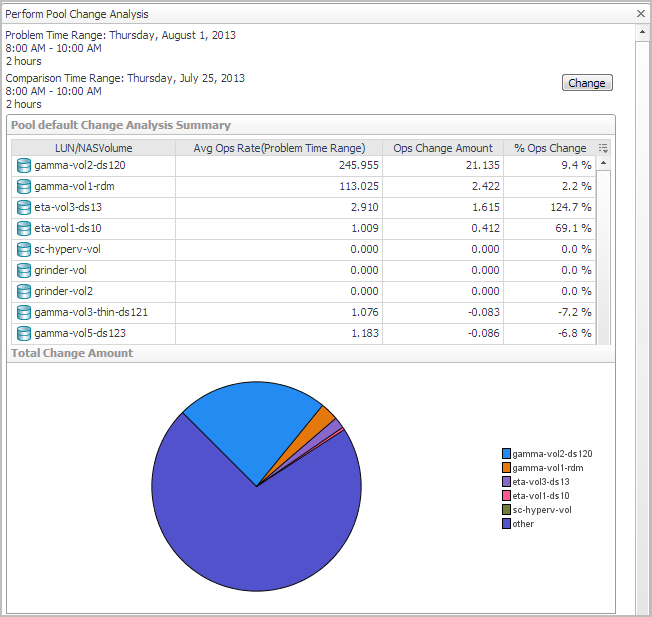
|
TIP: You can change the comparison time range by clicking Change and selecting a new date and time range. |
|
3 |
Click Perform Pool Load Analysis. |