Recover replication if the primary system fails
In an unplanned failure of the primary (source) machine, replicated data remaining in the SharePlex queues on that system will be unrecoverable as a result of buffering and the likelihood that the queues are corrupted. In a high-availability environment, you can move replication to the secondary (target) machine along with the database users to maintain data availability. When the primary system is restored, you can move users and replication back to that system with minimal downtime using a hot backup of the secondary instance.
For this procedure, you will activate a configuration file and then use the reconcile command to synchronize the results of the backup with ongoing replicated user changes after the copied instance is recovered.
Supported databases
Oracle database on Unix or Linux
Requirements
Procedure 1: Move replication to the secondary system
To move replication to the secondary system after an unplanned failure of the primary system:
-
Verify that Export is stopped on the secondary system.
sp_ctrl> stop export
-
Use the qstatus command to view the post queue, and keep issuing this command until the number of backlogged messages is 0. Note: Do not wait for the actual numberof messages to be 0. If the primary system failed before the commit for some transactions were received, messages for these partial transactions will remain in the queue until cleared later in this procedure.
sp_ctrl> qstatus
- Run the script that grants INSERT, UPDATE and DELETE access to all users on the secondary system.
- Run the script that enables triggers and constraints on the secondary system when users begin using this system.
- Implement the failover procedure for relocating users to the secondary system, including starting the applications.
- Move users to the secondary system and let them resume working, but do not start Export. Their transactions will now be accumulating in the export queue awaiting restoration of the source database.
Note: If started, Export will repeatedly try to connect to the primary system, wasting system resources.
- Go to Procedure 2: Move replication to the restored primary system.
Procedure 2: Move replication to the restored primary system
This procedure moves users back to the primary machine after it is recovered from an unplanned failure. Follow each segment in the order presented.
Restore the replication environment on the primary system
To restore the replication environment on the primary system:
- On the primary system, recover the SharePlex directories, system files and Oracle files from the backups and archives.
-
On the primary system, start sp_cop &.
Note: After starting SharePlex, you can manually stop the processes (Capture, Read, Export, Import, Post).
- On the primary system, start sp_ctrl.
-
On the primary system, deactivate the configuration file. When you copied the archived SharePlex variable-data directory to the primary system, you copied the configuration that was active before the system failed. This causes the Capture process to set the transaction number to “1” when replication from the primary system resumes.
sp_ctrl> deactivate config filename
Purge the queues
To purge the queues:
- Run sp_ctrl on the primary and secondary systems.
-
On the primary system, delete the capture queue.
sp_ctrl> delete capture queue for datasrc [on host]
Example: sp_ctrl> delete capture queue for o.oraA
-
On the primary system, delete the export queue.
sp_ctrl> delete export queue quename [on host]
Example: sp_ctrl> delete export queue sysA
-
On the secondary system, delete the post queue.
sp_ctrl> delete post queue quename for datasrc-datadst [cleartrans] [on host]
Example: sp_ctrl> delete post queue sysA for o.oraA-o.oraB
|
Note:
- You are issuing the delete queue command on the primary system because you restored the old capture and export queues when you restored the archived SharePlex directories.
- You are issuing the delete queue command on the secondary system because data remaining in the post queue cannot be posted. The primary system failed before Post received a COMMIT for remaining transactions. SharePlex will rebuild the queues when you reactivate the configuration and the two systems are reconciled.
|
Start replication from secondary to primary system
To start replication from secondary to primary system:
-
On the primary system, verify that all SharePlex processes are stopped.
sp_ctrl> status
-
On the primary system, stop Post.
sp_ctrl> stop post
-
On the secondary system, start Export. This establishes communication between the primary and secondary systems.:
sp_ctrl> start export
Synchronize the source and target data
To synchronize the source and target data:
- On the secondary system, run an Oracle hot backup.
-
When the hot backup is finished, switch log files on the secondary system and make a note of the highest archive-log sequence number.
- On the primary system, recover the primary database from the backup by using the UNTIL CANCEL option in the RECOVER clause, and cancel the recovery after the log with the number you recorded has been fully applied.
-
Open the database with the RESETLOGS option.
Note: This resets the sequences on the primary system to the top of the cache upon startup.
-
On the primary system, issue the reconcile command using the sequence number of the log that you noted previously. If you are using named post queues, issue the command for each one. If you do not know the queue names, issue the qstatus command first.
sp_ctrl> qstatus
sp_ctrl> reconcile queue queuename for datasource-datadest seq sequence_number
Example: reconcile queue SysB for o.oraA-o.oraA seq 1234
- On the primary system, disable triggers on the tables, or run the sp_add_trigger.sql utility script so that the triggers ignore the SharePlex user.
- On the primary system, disable check constraints and scheduled jobs that perform DML.
- On the primary system, log onto SQL*Plus as the SharePlex Oracle user and run the cleanup.sql utility from the bin sub-directory of the SharePlex product directory. This truncates the SharePlex tables and updates the SHAREPLEX_ACTID table.
- On the secondary system, truncate the SHAREPLEX_TRANS table. This table contains transaction information that the Post process was using before the primary system failed, and therefore that information is obsolete. Truncating the table restores transaction consistency between the two systems.
Activate replication on the primary system
To activate replication on the primary system:
-
On the primary system, activate the configuration file.
sp_ctrl> activate config filename
-
On the primary system, start Post.
sp_ctrl> start post
Restore the object cache
To restore the object cache:
-
On the primary system, view the status of the SharePlex processes.
sp_ctrl> status
Note: This command shows that Post stopped due to an error, which occurred because the object cache is missing.
-
On the primary system, issue the show log command with the filter option, and filter on the keyword "objcache."
sp_ctrl> show log filter=objcache
-
Look for a Post error message that refers to a file with a name similar to the following example:
0x0a0100c5+PP+sys4+sp_opst_mt+o.quest-o.ov-objcache_sp_opst_mt.18
You are looking for a string that contains the string “objcache_sp_opst_mt,” followed by a number. This is the object-cache file that the Post process needs. If you are using named post queues, there will be more than one error message, each referring to a different object-cache file but ending with the same number, such as the number .18 in the example.
-
Make a note of the full pathname of the Post object-cache file(s) named in the error message. The path will be the state directory in the SharePlex variable-data directory, for example:
splex_vardir/state/0x0a0100c5+PP+sys4+sp_opst_mt+o.quest-o.ov-objcache_sp_opst_mt.18
-
On the secondary system, shut down SharePlex.
sp_ctrl> shutdown
-
On the secondary system, change directories to the state sub-directory of the SharePlex variable-data directory and locate the Capture object-cache file. This file will have a name similar to the one in the following example.
o.quest-objcache_sp_ocap.18
Important! If there are more than one of these files, use the one with the most recent number at the end of it — this number should match the number at the end of the Post object-cache file, such as .18 in the example.
- Copy the Capture object-cache file to the primary system and rename it to the full pathname of the Post object-cache file that you noted previously.
-
On the primary system, start Post.
sp_ctrl> start post
Switch users back to the primary system
To switch users back to the primary system:
- On the secondary system, stop user access to the database.
-
On the primary system, view the post queue and continue to issue the command until the number of messages is 0.
sp_ctrl> qstatus
-
On the secondary system, shut down the Oracle instance.
svrmgr1> shutdown
-
On the secondary system, start the Oracle instance.
svrmgr1> startup
Note: This resets the sequence on the secondary system to the top of the cache to synchronize with the primary system.
- On the primary system, enable database objects that were disabled.
- On the secondary system, start SharePlex.
-
On the secondary system, stop Post.
sp_ctrl> stop post
- On the secondary system, disable triggers on the tables, or run the sp_add_trigger.sql utility script so that the triggers ignore the SharePlex user.
- On the secondary system, disable check constraints and scheduled jobs that perform DML.
-
On the secondary system, start Post.
sp_ctrl> start post
-
On the primary system, view the number of messages in the post queue, and keep checking until the number of messages is 0.
sp_ctrl> qstatus
- When the number of messages is 0, switch users back to the primary system.
-
On the secondary system, stop Export to prevent accidental changes made on that system from being replicated to the primary system.
sp_ctrl> stop export
Note: The secondary system is now in a failover-ready state again, with:
- no users
- an active configuration
- disabled or modified triggers, constraints, and scheduled jobs
- a stopped Export process
|
Recover replication if the secondary Oracle instance fails
In an unplanned failure of the secondary (target) Oracle instance, the replication environment from that system to the primary system is corrupted. This procedure enables you to restore the replication configuration without affecting the database users on the primary system, and without the need to reactivate the configuration file on the primary system. Only the secondary configuration is affected.
This procedure cleans out the SharePlex queues and restores the target instance by means of a hot backup from the source system. You will use the reconcile command to synchronize the results of the backup with ongoing replicated user changes after the copied instance is recovered.
Supported databases
Oracle database on Unix or Linux
Requirements
Procedure
This procedure is divided into logical segments. Follow them in the order presented.
Purge the queues
To purge the queues:
-
On the secondary system, stop Post.
sp_ctrl> stop post
-
On the secondary system, deactivate the configuration file.
sp_ctrl> deactivate config filename
Note: The deactivation causes the error “Error in sp_cnc.” in the Event Log. You may ignore it and continue with the procedure.
- On the primary system, run sp_ctrl.
-
On the primary system, delete the post queue.
sp_ctrl> delete post queue quename for datasrc-datadst [cleartrans] [on host]
Example: sp_ctrl> delete queue sysB:P for o.oraA-o.oraB
Note: You are deleting the queues on the primary system because there could be messages remaining from uncommitted transactions sent from the secondary instance before it failed.
- On the primary system, truncate the SHAREPLEX_TRANS internal table in the SharePlex schema. This table contains transaction information that the Post process on that system was using before the secondary instance failed, and therefore the information is obsolete. Truncating the tables restores transaction consistency.
- On the secondary system, run sp_ctrl.
-
On the secondary system, delete the capture queue.
sp_ctrl> delete capture queue for datasrc [on host]
Example: sp_ctrl> delete queue o.oraB:C
-
On the secondary system, delete the export queue.
sp_ctrl> delete export queue quename [on host]
Example: sp_ctrl> delete queue sysB:X
Note: You are deleting the queues on the secondary system because the capture and export queues on that system still retain a record of the transactions that have already been processed.
Synchronize the data
To synchronize the data:
- On the primary system, begin a hot backup of the primary Oracle instance.
-
On the primary system, switch log files.
On-premises database:
svrmgr1> alter system switch logfile;
Amazon RDS database:
Use Amazon RDS procedure rdsadmin.rdsadmin_util.switch_logfile.
- Make a note of the highest sequence number of the archive logs.
- On the secondary system, recover the secondary database from the hot backup using the UNTIL CANCEL option in the RECOVER clause. Cancel the recovery after Oracle has fully applied the log from the previous step.
- On the secondary system, open the secondary database with the RESETLOGS option. This resets the sequence on the secondary system to the top of the cache upon startup
- On the secondary system, run SQL*Plus as the SharePlex database user.
-
In SQL*Plus, run the cleanup.sql script from the bin subdirectory of the SharePlex product directory.
-
On the secondary system, issue the reconcile command using the sequence number of the log that you noted previously. If you are using named post queues, issue the command for each one. If you do not know the queue names, issue the qstatus command first.
sp_ctrl> qstatus
sp_ctrl> reconcile queue queuename for datasource-datadest seq sequence_number
Example: reconcile queue SysA for o.oraA-o.oraA seq 1234
- On the secondary system, disable triggers on the tables, or run the sp_add_trigger.sql utility script so that the triggers ignore the SharePlex user.
- On the secondary system, disable check constraints and scheduled jobs that perform DML.
-
On the secondary system, after the sp_ctrl prompt returns, stop Export. This ensures that nothing accidentally gets replicated to the primary system when you activate the configuration on the secondary system.
sp_ctrl> stop export
Start replication on the secondary system
To start replication on the secondary system:
-
On the secondary system, activate the configuration file.
sp_ctrl> activate config filename
-
On the secondary system, start Post.
sp_ctrl> start post
-
Use the status command to determine if any other SharePlex processes have a status of Stopped due to Error and start them.
sp_ctrl> status
sp_ctrl> start process
Note: The secondary system is now prepared for future failover.
Move replication during planned failover and failback
In a planned failover of database activity to a secondary Oracle instance, you can quickly move SharePlex to the secondary system. While users continue their transactions on that system, SharePlex captures their changes and stores them until the primary system is back online and activity is moved back to that system.
Supported databases
Oracle database on Unix or Linux
Requirements
Procedure
This procedure is divided into logical segments. Follow them in the order presented. Do not shut down the primary instance until prompted in the procedure.
Switch users to the secondary system
To switch users to the secondary system:
- On the primary system, stop user access to the primary instance.
-
On the primary system, flush the data in the queues to the secondary system. This command stops Post on the secondary system and places a marker in the data stream to establish a synchronization point between the primary and secondary data.
sp_ctrl> flush datasource
where: datasource is the datasource specification of the primary Oracle instance, for example o.OraA.
-
On the secondary system, verify that Post stopped. (Continue to issue this command until it shows that Post stopped.)
sp_ctrl> status
-
On the primary system, verify that there are no messages in the capture and export queues. The Number of Messages and the Backlog (messages) fields must be 0.
sp_ctrl> qstatus
-
On the secondary system, verify that there are no messages in the post queue. The Number of Messages and the Backlog (messages) fields must be 0.
sp_ctrl> qstatus
- On the primary system, shut down SharePlex.
-
On the primary system, shut down the Oracle instance with the abort option. Do not use the immediate option.
svrmgr1> shutdown abort
Note: This resets the sequence on the primary system to the top of the cache when the database starts.
-
On the secondary system, verify that Export is stopped. This prevents user changes from being replicated to the primary system until it is back online and SharePlex is ready to receive them. Stop Export if needed.
sp_ctrl> status
sp_ctrl> stop export
- On the secondary system, run the script that grants INSERT, UPDATE and DELETE access to all users.
- On the secondary system, run the script that enables triggers and constraints on the secondary instance.
- Run your failover procedure for relocating users to the secondary system, including starting the applications and starting jobs that were running on the primary system.
- Move the users to the secondary system to resume working, but do not start the Export process.
Switch users back to the primary system
To switch users back to the primary system:
- On the primary system, open the Oracle instance. The sequence on this system should now be at the top of the cache.
- On the primary system, disable triggers on the tables, or run the sp_add_trigger.sql utility script so that the triggers ignore the SharePlex user.
- On the primary system, disable check constraints and scheduled jobs that perform DML.
- On the primary system, start SharePlex.
-
On the secondary system, start Export so that SharePlex sends the accumulated replicated data to the primary system.
sp_ctrl> start export
Note: SharePlex passes any sequence updates from the secondary system back to the primary system when Export starts.
-
On the primary system, stop Export.
sp_ctrl> stop export
-
On the primary system, allow Post to process the message backlog that was sent from the primary system.
- On the secondary system, stop user access to the Oracle instance.
-
On the secondary system, flush the data in the queues to the primary system.
sp_ctrl> flush datasource
where: datasource is the datasource specification of the secondary Oracle instance, for example o.OraB.
-
On the primary system, verify that Post stopped. (Continue to issue this command until it shows that Post stopped.)
sp_ctrl> status
-
On the secondary system, verify that there are no messages in the capture and export queues. The Number of Messages and the Backlog (messages) fields must be 0.
sp_ctrl> qstatus
-
On the primary system, verify that there are no messages in the post queue. The Number of Messages and the Backlog (messages) fields must be 0.
sp_ctrl> qstatus
-
On the secondary system, shut down SharePlex.
sp_ctrl> shutdown
-
On the secondary system, shut down the Oracle instance with the abort option. Do not use the immediate option.
svrmgr1> shutdown abort
Note: This resets the sequence on the secondary system to the top of the cache when the database starts.
-
On the secondary system, start the Oracle instance.
svrmgr1> startup
Note: The sequence on the secondary system is now at the top of the cache. When the next value is selected on the primary system, a new cache is acquired and is replicated to the secondary system. Now, the primary system is at the start of a cache, and the secondary system is at the top of a cache.
- On the primary system, run the script that grants INSERT, UPDATE and DELETE access to all users.
- On the primary system, run the script that enables triggers and constraints on the primary system when users begin using this system.
- Run your failover procedure for moving users back to the primary system, including starting the applications and starting jobs that were running on the secondary system.
- Switch the users to the primary system to resume working, but do not start the Export process. This prevents replicated data from being sent to the secondary system until SharePlex is ready to receive it there.
Resume replication to maintain the secondary instance
To resume replication to maintain the secondary instance:
- On the secondary system, disable triggers on the tables, or run the sp_add_trigger.sql utility script so that the triggers ignore the SharePlex user.
- On the secondary system, disable check constraints and scheduled jobs that perform DML.
- On the secondary system, start SharePlex.
-
On the secondary system, stop Export. This prevents any accidental DML on that system from being replicated to the primary system.
sp_ctrl> stop export
-
On the primary system, start export.
sp_ctrl> start export
-
On the secondary system, start Post.
sp_ctrl> start post
Replication from the primary instance to the secondary instance is now active to keep the two databases synchronized and ready for future failover when needed.
Resume replication after failure and recovery
The procedure is typically used in these situations:
- When the source system fails and replication must be switched to a standby database system
- When replication must be positioned back in time to re-read old archive logs.
Requirements to support SharePlex replication recovery
To resume replication when the source, target or both have failed, there must be the following in place at the onset of replication:
- A disaster recovery (DR) solution that provides a physically identical copy of the production source instance and another physical copy of the production target instance. Methods such as Oracle Data Guard or disk mirroring, tape backups and other methods support this requirement.
- The SP_OPO_UPDATE_SCN parameter must be set to a value of 1. This parameter directs SharePlex to keep a record of the SCNs of the transactions that it processes. When you set this parameter to 1, it also disables the Post Enhanced Performance feature.
Overview of initial setup
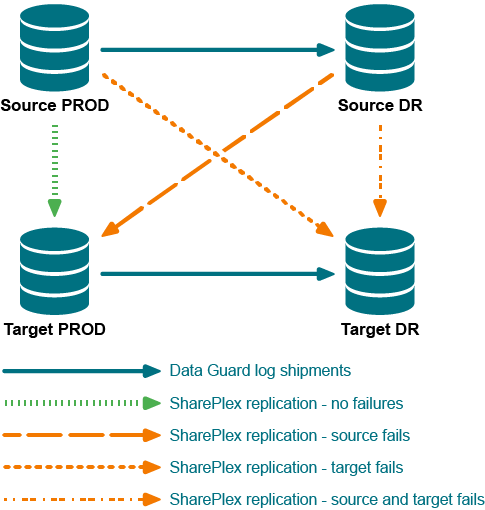
The following diagram depicts a DR configuration at the onset of replication. There is a source production instance and a mirrored source DR instance that is kept current by Oracle Data Guard. Similarly, there is a production target instance and a mirrored DR target instance that is kept current by Oracle Data Guard.
- The solid (blue) lines represent the Oracle Data Guard DR deployment.
- The dotted (bright green) line between the production source instance and the production target instance represent SharePlex replication under normal operating circumstances.
- The dashed lines (red, orange or aqua) show possible replication recovery paths if the source, target or both fail.
Figure 2: DR configuration at the onset of replication
Example failure/recovery scenario
This example illustrates one of the potential failure/recovery scenarios, in this case where the production target instance fails. The recovery path is shown as the diagonal, orange dotted line in the DR configuration at the onset of replication diagram.
Normal replication
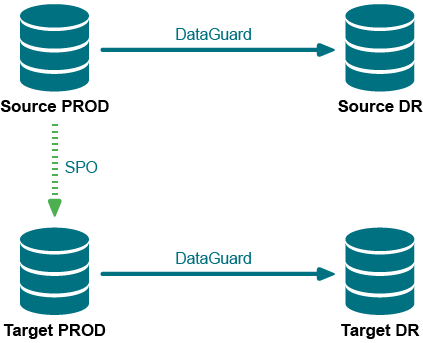
The following diagram illustrates the configuration and the names that are used in this example:
- The production source is named Source PROD and the DR source is named Source DR.
- The production target is named Target PROD and the DR target is named Target DR.
- SharePlex (SPO in the diagram) replicates from Source PROD to Target PROD.
Figure 3: Normal replication and mirroring configuration
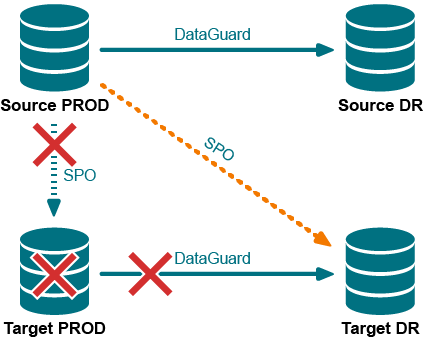
Production target fails
The Target PROD target fails, as represented by the red X across it in the following diagram. SharePlex can no longer replicate to Target PROD, as represented by the red X over the original replication data stream.
Because Target PROD is offline, Oracle Data Guard can no longer keep Target DR up to date. However, SharePlex can. SharePlex (SPO in the diagram) is able to resume replication from Source PROD to Target DR, thus resuming data availability.
Figure 4: Failure and recovery by SharePlex (SPO)
Resume replication after failover
In this procedure you will do the following to direct SharePlex to recover replication:
- Direct SharePlex to capture the correct Oracle SCN of the last committed transaction processed by each post queue.
- Direct SharePlex, through the reconcile command, to discard all transactions that were committed to the target before the failure, so that SharePlex resumes replication at the correct point in the data stream.
Note: This procedure requires the following:
- The source instance is recovered to a later point in time than the target instance; otherwise, this method will not work.
- The SP_OPO_UPDATE_SCN parameter is set to 1.
To resume replication:
Note: In these instructions, the source and target systems are whichever source and target are operational after the failover.
-
Shut down SharePlex on the source system, if it is still running.
sp_ctrl> shutdown
-
On the target, start sp_cop if it is not running already.
$ /productdir/bin/sp_cop &
-
On the target, use the qstatus command to make certain that all of the message in the queues are posted to the target database. The command output should show 0 backlog in the post queue.
sp_ctrl> qstatus
-
From the command line of the target, run the show_scn utility from the bin subdirectory of the SharePlex product directory. For ORACLE_SID use the ORACLE_SID of the target database.
$ /productdir/bin/show_scn ORACLE_SID
- Keep the output of the show_scn utility open. The output displays the complete reconcile command that you will use for each of your post queues to reposition Post to the correct transaction for recovery. It also shows the SCN to which you will activate the configuration later in these steps.
-
Shut down sp_cop on the source and target.
sp_ctrl> shutdown
-
Run ora_cleansp on the source and target to clean out the queues.
$ /productdir/bin/ora_cleansp
-
Start sp_cop on the source and target.
$ /productdir/bin/sp_cop &
-
On the target, stop Post.
sp_ctrl> stop post
-
On the source, issue the activate config command with the scn option to activate the configuration. For scn_value, use the value that is shown in the output of the show_scn utility on the line that states On source activate to scn=nnnnnnn.
sp_ctrl> activate config configname scn=scn_value
Example:
sp_ctrl> activate config myconfig scn=510012416
-
On the target, copy the first reconcile command from the show_scn output and then execute it in sp_ctrl. Then do the same for the second reconcile command, and work your way down the list.
Example:
sp_ctrl> reconcile queue spx11 for o.ora112-o.ora112 scn 235690
sp_ctrl> reconcile queue pq1 for o.ora112-o.ora112 scn 132436
sp_ctrl> reconcile queue pq2 for o.ora112-o.ora112 scn 246843
sp_ctrl> reconcile queue pq3 for o.ora112-o.ora112 scn 123457
The reconcile command may seem stalled until new data comes in. However, the command is working.
-
On the target, start Post.
sp_ctrl> start post
