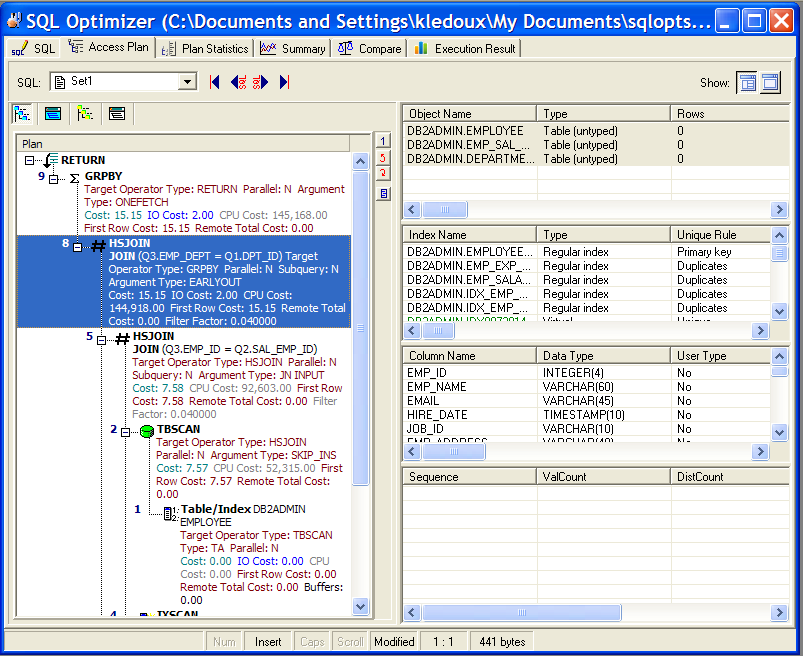
The Access Plan tab in the SQL Optimizer window uses the following panes to display access plan details for the currently selected alternative and information about the objects that the alternative syntax accesses:
Column Values Distribution Statistics
You can rerun the Generate Indexes function to obtain the latest index recommendations.
Note: This process will clear all existing SQL and index-set alternative in this SQL Optimizer session.
To regenerate virtual index sets
Right-click within any of the statistics panes, and select Recommend Virtual Indexes.
You can add your own index sets to this SQL Optimizer session.
To create your own virtual index sets
Right-click within any of the statistics panes, and select Create Virtual Indexes.
Use the pane-control buttons to reorganize the panes.
To display the Access Plan, and the Table, Index, Column, and Column Value Distribution panes
Click .
To display only the Access Plan pane
Click .
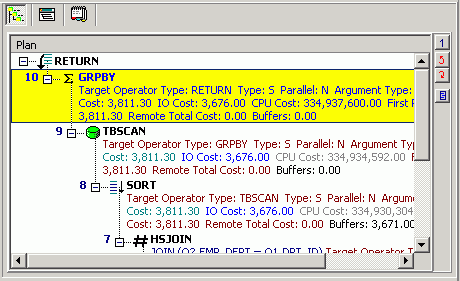
The access plan is a combination of steps the DB2 LUW database optimizer chooses to execute a SQL statement. Each node represents how the database optimizer will physically retrieve rows of data from the database or how the data is prepared. By examining the access plan, you can see exactly how the database executes your SQL statement.
The Access Plan pane contains a right-click menu that allows you to perform the following functions:
|
Function |
Description |
|---|---|
|
|
Sends the access plan in its current view to the printer, to display on the screen (print preview), or to a file. |
|
Copy |
Copies the access plan to the clipboard. |
|
View Plan |
Changes how the access plan is displayed. |
|
Animated Plan Steps |
Highlights one-by-one the access plan steps. |
|
Plan Options |
Opens the Access Plan Options window so you can select the specific detailed information that is displayed in the access plan. You can also choose to display specific information in individual columns. |
|
Get Help on plan_step |
Displays the help text for the currently selected step in the access plan. |
|
Help on Access Plan |
Opens online help for the access plan. |

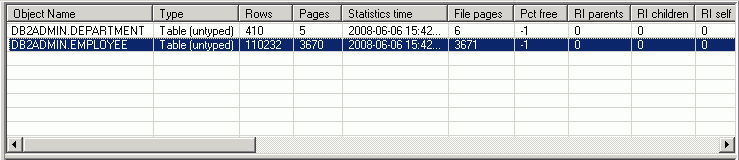
The Object Statistics pane is displayed on the Access Plan tab in the SQL Optimizer window. It lists information for each table, view, or alias referenced in the access plan. If the operation in the selected access plan step accesses a specific object, this object is automatically highlighted in the Table Statistics pane. You can do the following in this pane:
Select an object in this pane to view statistics about its indexes and columns (in the Index and Column Statistics panes, respectively).
Right-click a specific object to update its catalog statistics.
The method in which rows are inserted on pages in the table or view:
|
Value |
Description |
|---|---|
|
Rows appended |
New rows are inserted at the end of the data. |
|
Rows inserted |
New rows are inserted into existing spaces if available. |
The number of check constraints defined on the table or view.
This information is based on the CHECKCOUNT value for the table or view in SYSCAT.TABLES.
The number of columns in the table or view.
This information is based on the COLCOUNT value for the table or view in SYSCAT.TABLES.
Total number of pages allocated for this table.
This information is based on the FPAGES value for the table or view in SYSCAT.TABLES.
The name of the tablespace that holds all the indexes created for the table or view.
This information is based on the INDEX_TBSPACE value for the table or view in SYSCAT.TABLES.
The number of columns that make up the primary key for the table or view.
This information is based on the KEYCOLUMNS value for the table or view in SYSCAT.TABLES.
The number of unique constraints (other than a primary key constraint) defined for the table or view.
This information is based on the KEYUNIQUE value for the table or view in SYSCAT.TABLES.
The name of the tablespace that holds all long data (for LONG or LOB column types) for the table or view.
This information is based on the LONG_TBSPACE value for the table or view in SYSCAT.TABLES.
The preferred lock granularity when DML statements are executed on the table:
|
Value |
Description |
|---|---|
|
Row |
Row-level lock |
|
Lock |
Table-level lock |
|
blank |
Not applicable |
The qualified name of the table or view.
This information is based on the TABSCHEMA and TABNAME values for the table or view in SYSCAT.TABLES.
Total number of overflow records in the table or view. An overflow record is an updated record that is too large to fit on the page in which it is currently stored. The record is copied to another page, and its original location is replaced with a pointer to the new page.
This information is based on the OVERFLOW value for the table or view in SYSCAT.TABLES.
Total number of pages that contain data for the table or view.
This information is based on the NPAGES value for the table or view in SYSCAT.TABLES.
Percentage of each page in the table or view to be reserved for future inserts.
This information is based on the PCTFREE value for the table or view in SYSCAT.TABLES.
The mode used to distribute data in the table or view within a partitioned database:
|
Value |
Description |
|---|---|
|
Hash on partition key |
Hash on the partitioning key |
|
Replicate across partitions |
Replicate table or view data across partitions |
|
blank |
No partitioning. The table, view, or alias exists in a single partition nodegroup with no partitioning key defined. A blank also appears for nicknames. |
The number of referential constraints in which the table or view is a parent (that is, the number of dependent tables of this table).
This information is based on the CHILDREN value for the table or view in SYSCAT.TABLES.
The number of referential constraints in which the table or view is a dependent (that is, the number of parent tables of this table).
This information is based on the PARENTS value for the table or view in SYSCAT.TABLES.
The number of referential constraints in which the table or view is both a parent and a dependent.
This information is based on the SELFREFS value for the table or view in SYSCAT.TABLES.
Total number of data rows in the table or view.
This information is based on the CARD value for the table or view in SYSCAT.TABLES.
The timestamp for the last time a change was made to statistics for the table or view.
This information is based on the STATS_TIME value for the table or view in SYSCAT.TABLES.
Status type for the object from which information is retrieved:
|
Value |
Description |
|
Normal |
Normal status for the table, view, alias, or nickname. |
|
Check |
CHECK PENDING status on the table or nickname. Constraint checking is turned off, and SELECT, INSERT, UPDATE, and DELETE operations are not allowed on the table. |
|
X |
Inoperative view or nickname. This status can occur when the underlying tables of the view or nickname have been dropped. |
The name of the primary tablespace for the table or view.
This information is based on the TBSPACE value for the table or view in SYSCAT.TABLES.
The type of table or view from which information is retrieved:
|
Value |
Description |
|
Table |
Normal table |
|
Hierarchy |
The hierarchy table associated with the implementation of a typed table hierarchy |
|
Summary |
Summary table |
|
View |
Normal view |
|
Alias |
An indirect reference to a table |
|
Nickname |
A reference to a table (data source) in a federated database |
|
Typed table |
Table created from a structured type |
|
Type view |
A view created from a structured type |
The indicator showing whether the table or view has been declared volatile. A volatile table is a table whose contents vary greatly--from empty to large--at any point in time. To generate the access plan for a volatile table, DB2's SQL optimizer tends not to rely on existing table statistics and, therefore, often uses an index scan instead of a table scan. Values for this detail include:
|
Value |
Description |
|
Cardinality of table is volatile |
Table is volatile |
|
blank |
Table is not volatile |
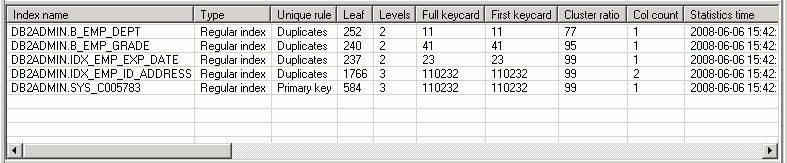
The Index Statistics pane is displayed on the Access Plan tab in the SQL Optimizer window. It lists information about each index that exists for the highlighted object in the Object Statistics pane. Additionally, if the operation in the selected access plan step uses an index, this index is automatically highlighted in the Index Statistics pane. You can do the following in this pane:
Select any index to view statistics about the columns for the index. (The appropriate column rows are highlighted in the Column Statistics pane.)
Right-click a specific index to update its catalog statistics.
Note: If the object highlighted in the Object Statistics pane is a view, then no indexes display in the Index Statistics pane.
For each index listed in the Index Statistics pane, the following information is obtained from the SYSCAT.INDEXES catalog view:
The number of columns that make up the index key for the index, plus any INCLUDE columns, which are additional non-key columns maintained in a unique index.
This information is based on the COLCOUNT value for the index in SYSCAT.INDEXES.
The ratio of the number of table rows that are ordered on data pages in index key sequence to the total number of table rows. This value is expressed as a decimal value between 0 and 1, with a higher precision than the Cluster Ratio. The optimizer uses this statistic to estimate the I/O cost of reading data pages into the bufferpool. The value –1 is used to indicate that no statistics are available.
Note: Either this statistic or the Cluster Ratio—not both—is recorded in the SYSCAT.INDEXES catalog. Generally, only one of the indexes for a table can have a high degree of clustering.
This information is based on the CLUSTERFACTOR value for the index in SYSCAT.INDEXES.
The ratio of the number of table rows that are ordered on data pages in index key sequence to the total number of table rows. This value is expressed as a percentage (a whole number between 0 and 100). The optimizer uses this statistic to estimate the I/O cost of reading data pages into the bufferpool. The value –1 is used to indicate that no statistics are available.
Note: Either this statistic or the Cluster Factor—not both—is recorded in the SYSCAT.INDEXES catalog. Generally, only one of the indexes for a table can have a high degree of clustering.
This information is based on the CLUSTERRATIO value for the index in SYSCAT.INDEXES.
The user who created the index.
This information is based on the DEFINER value for the index in SYSCAT.INDEXES.
The ratio of the Seq Pages value to the total number of pages occupied by the index. This ratio is expressed as a percentage.
This information is based on the DENSITY value for the index in SYSCAT.INDEXES.
The type of table on which the index is based:
|
Value |
Description |
|
Untyped Table |
A regular table or view (or the alias or nickname referring to a regular table). In a regular table, the data type for each column is defined separately in the CREATE TABLE statement. |
|
Typed Table |
A table based on a user-defined structured type. In a typed table, the column definitions are derived from attributes in the structured type on which the table was created. Note that a typed table can be a supertable or a subtable within a table hierarchy. (A subtable inherits its column definitions from the supertable.) |
|
Hierarchy Table |
A hierarchy table, which contains one column for each unique column in the table hierarchy. DB2's SQL optimizer uses this table to generate access plans for queries written against the individual tables in the hierarchy. |
The number of distinct key values based on the first column in the index key.
This information is based on the FIRSTKEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct keys using the first two columns of the index. (The value -1 is used if statistics have never been updated or if this statistic does not apply to the index key.)
This information is based on the FIRST2KEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct keys using the first three columns of the index. (The value -1 is used if statistics have never been updated or if this statistic does not apply to the index key.)
This information is based on the FIRST3KEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct keys using the first four columns of the index. (The value -1 is used if statistics have never been updated or if this statistic does not apply to the index key.)
This information is based on the FIRST4KEYCARD value for the index in SYSCAT.INDEXES.
The number of distinct values for the index key. If the index key is unique, the Full Keycard value is equal to the number of rows in the table, or the table’s cardinality. If the index key is not unique, the Full Keycard value is equal to the number of distinct values available for the key. For example, if the index key is made up of one column called Status, which has three possible values--Paid, Billed, or Late, the Full Keycard value is 3.
This information is based on the FULLKEYCARD value for the index in SYSCAT.INDEXES.
The qualified name of the index.
This information is based on the INDSCHEMA and INDNAME values for the index in SYSCAT.INDEXES.
The internal ID of the index.
This information is based on the IID value for the index in SYSCAT.INDEXES.
The number of leaf pages in the index.
This information is based on the NLEAF value for the index in SYSCAT.INDEXES.
The number of non-leaf and leaf levels in the B+ structure of the index.
This information is based on the NLEVELS value for the index in SYSCAT.INDEXES.
Indicator as whether the index was converted from a non-unique to a unique index to support a unique or primary key constraint. (If you drop the constraint, the index reverts to non-unique.)
|
Value |
Description |
|
Yes |
The index was converted to unique. |
|
No |
The index remains as it was created. |
The minimum percentage of used space allowed before the online index reorganization feature merges index pages. (This number is expressed as an integer between 0 and 99.) This statistic is not available for a nickname.
This information is based on the MINPCTUSED value for the index in SYSCAT.INDEXES.
A list of integer pairs that provide page fetch estimates for different buffer sizes. The first integer in a given pair represents the number of pages in a hypothetical buffer. The second integer in the pair represents the number of pages fetches required to scan the table with the index using the hypothetical buffer. DB2's SQL optimizer uses this information to estimate the cost of reading data pages into the bufferpool when the Cluster Ratio statistic is not available.
This information is based on the PAGE_FETCH_PAIRS value for the index in SYSCAT.INDEXES.
The percentage of space on each leaf page that is available for future inserts. (This value is determined when the index is created.)
This information is based on the PCTFREE value for the index in SYSCAT.INDEXES.
Indicator as to whether the index supports reverse scans, enabling DB2's Index Manager to scan the index in a forward and backward direction to retrieve data:
|
Value |
Description |
|
Yes |
The index supports reverse scan. |
|
No |
The index does not support reverse scans. |
The number of leaf pages located physically located in index key order with few or not large gaps between them.
This information is based on the SEQUENTIAL_PAGES value for the index in SYSCAT.INDEXES.
The timestamp for the last time a change was made to statistics for the index.
This information is based on the STATS_TIME value for the index in SYSCAT.INDEXES.
Indicator as to whether the index is required by the system:
|
Value |
Description |
|
1 |
The index is required for a primary or unique key constraint or is required as the index on the OID column in a typed table. |
|
2 |
The index is required for a primary or unique key constraint and is required as the index on the OID column in a typed table. |
|
3 |
The index is not required. |
The type of index. This value is based on the INDEXTYPE value for the index in SYSCAT.INDEXES.
|
Value |
Description |
|
Block |
A composite block index, which contains the key columns for all dimensions in a multi-dimensional clustering (MDC) table |
|
Clustering |
The table’s clustering index |
|
Dimension block |
An index containing pointers to each occupied extent for a single dimension in a multi-dimensional clustering (MDC) table |
|
Regular* |
A non-clustering index on the table |
|
Virtual (R) |
A recommended virtual index on the table |
|
Virtual (U) |
A user-defined virtual index on the table |
The number of columns that make up the unique key in the index (if the index has a unique key).
This information is based on the UNIQUE_COLCOUNT value for the index in SYSCAT.INDEXES.
The type of unique constraint that the Database Manager enforces using the index key during the execution of any operation--such as an INSERT or UPDATE--that changes data values in the table.
|
Value |
Description |
|
Duplicates |
The index key has no unique constraint. Duplicate key values are allowed in the table. |
|
Primary Index |
The index key enforces a primary key constraint. No two primary key values in the table can be equal. The columns that make up the primary key cannot contain NULL values. |
|
Unique |
The index key enforces a unique constraint on the table. No two unique key values in the table can be equal. The columns that make up the unique key cannot contain NULL values. |
The indicator as to whether the index is user defined (using the CREATE INDEX statement) or system defined.
|
Value |
Description |
|
Yes |
The index is user defined and has not been dropped. |
|
No |
The index is system defined or automatically created at the time when the database was installed. |
