Modify Partition for PostgreSQL
Use the modify partition command to modify a row partition of a partition scheme in a horizontally partitioned replication configuration.
Reactivate the configuration file if the command affects a table that is already being replicated. SharePlex will only lock tables for which there are configuration changes.
For more information about how to configure horizontally partitioned replication, see the SharePlex Administration Guide.
Usage
| Supported source: |
PostgreSQL (on-prem), Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Supported targets: |
PostgreSQL, Oracle, SQL Server, Kafka, Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Issues on: |
source system |
| Related commands: |
add partition, drop partition, drop partition scheme, view partitions |
Syntax
|
modify partition in scheme_name
set
keyword=value
[and keyword=value]
[...]
where
keyword=value
[and keyword=value]
[...] |
Syntax description
Note: See add partition for additional descriptions of these options.
| scheme_name |
The name of the partition scheme. Do not modify this component, or the row partition will shift to a new partition scheme. |
| keyword |
Any of the following syntax components except scheme_name. |
| condition |
Column condition that defines a row partition. |
| route |
The routing map for this partition. |
| tablename |
Fully qualified target table name. |
| name |
Short name of this partition. |
| description |
Description of this partition. |
Examples
sp_ctrl> modify partition in scheme1 set condition = "C1 > 400" and route = sysc:q1@r.dbname where name = q1
sp_ctrl> modify partition in scheme1 set condition = "C1 > 400" where condition = "C1 > 300"
Purge config for PostgreSQL
Use the purge config command to remove the data from all queues associated with a configuration without removing the queues themselves or deactivating the configuration. Avoiding a deactivation avoids the need for SharePlex to recalculate the configuration data. This saves time when the tables are large and numerous, enabling replication can start sooner.
Issue the purge config command on the source system to affect the source system and all target systems in the configured routes. Should any SharePlex process stop prior to or during the purge config activity, the command also stops working. When the process starts again, the command resumes working. Thus, purge config works even when the network is temporarily unavailable — the command remains in the queues until the connection is restored.
Cautions for using the purge config command:
Do not activate a configuration and then follow the activate config command with a purge config command. You might be purging more than just queued data, including the configuration information that controls replication, thus rendering the activation invalid.
Usage
| Supported source: |
PostgreSQL (on-prem), Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Supported targets: |
PostgreSQL, Oracle, SQL Server, Kafka, Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Issued for: |
source and target systems |
| Related commands: |
abort config, deactivate config |
Syntax
Syntax description
| filename |
The name of the configuration that you want to purge. Configuration names are case-sensitive.
Example:
sp_ctrl(sysA)>purge config sales |
Reconcile for PostgreSQL
Use the reconcile command as part of a procedure to synchronize (instantiate) source and target data with minimal interruption to the database users. The reconcile command coordinates the results of ongoing replication with a copy of the source data that is applied to the target system, such as that applied by a hot-backup or a native copy utility. The reconcile function compares the replicated changes in the post queue with the state of the target database after the recovery process. It differentiates between the transactions that were applied during recovery from those that have not yet been applied (still waiting in the post queue), and it only posts the non-duplicated changes so that both systems are synchronized.
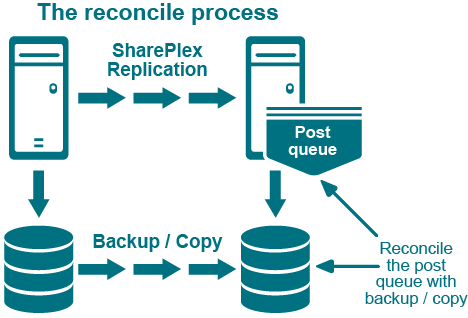
Although the reconcile command is designed for use in high-volume environments, it can be used in low-volume environments with an understanding that the reconcile process can, in some circumstances, seem to stall. This happens because the reconcile command depends on data continuing to arrive from the source system. If there is no replication activity on the source system after the hot backup or copy, the reconcile process waits until source activity resumes.
Considerations when using the reconcile command
The reconcile command should be used when following specific procedures for the initial synchronization of source and target data. It is not meant to be a standalone command. For initial synchronization procedures, see the SharePlex Administration Guide.
|
Notes:
-
Ensure that the transactions committed before the LSN are replicated at the target
-
Transactions that are not committed will not be removed and will be in the post queue
-
If ROLLBACK / COMMIT is before the LSN, then transaction will be removed from post queue
-
If ROLLBACK / COMMIT is after the LSN, then transaction will remain in the post queue |
Usage
| Supported source: |
PostgreSQL (on-prem), Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Supported targets: |
PostgreSQL, Oracle, SQL Server, Kafka, Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Issued for: |
target system |
| Related commands: |
flush |
Syntax
| reconcile queuequeuenamefordatasource-datadest |
[to flush]
[pglsn Log Sequence Number] |
Syntax description
| queue |
queue is a required part of the command. |
| queuename |
The post queue on the target system that you want to reconcile. Valid values are:
- The name of the source system if using default queues
- The name of the queue if using named queues
When using named post queues, issue the reconcile command for each one. To determine the queue name, issue the qstatus command in sp_ctrl. Queue names are case-sensitive on all platforms. |
| fordatasource-datadest |
-
datadest is expressed as o.SID, where SID is the ORACLE_SID of the target instance (for Oracle target).
-
datasource is expressed as r.dbname, where dbname is the database name of the source instance (for PostgreSQL source).
-
datadest is expressed as r.dbname, where dbname is the database name of the target instance (for PostgreSQL target).
Examples:
sp_ctrl (sysB)> reconcile queue SysA for r.dbname1-r.dbname2 (PostgreSQL to PostgreSQL implementation)
sp_ctrl (sysB)> reconcile queue SysA for r.dbname1-o.oraB (PostgreSQL to Oracle implementation) |
| pglsn LSN number |
Use LSN number in case of PostgreSQL implementation. We can provide LSN number in decimal or hexadecimal format.
Query to find current LSN:
select pg_current_wal_lsn();
Examples:
sp_ctrl (sysB)> reconcile queue SysA for r.dbname1-r.dbname2 pglsn 0/B817B360 (PostgreSQL to PostgreSQL - hexadecimal format LSN)
sp_ctrl (sysB)> reconcile queue SysA for r.dbname1-r.dbname2 pglsn 3088560992 (PostgreSQL to PostgreSQL - decimal format LSN)
sp_ctrl (sysB)> reconcile queue SysA for r.dbname1-o.oraB pglsn 3088560991 (PostgreSQL to Oracle decimal format LSN)
sp_ctrl (sysB)> reconcile queue SysA for r.dbname1-o.oraB pglsn 0/B817B361 (PostgreSQL to Oracle - hexadecimal format LSN) |
| to flush |
Use this option to reconcile to a flush marker that is established with the flush command. Use it for synchronizing multiple Oracle databases in a peer-to-peer replication environment.
The syntax must appear after the syntax for the basic command.
Example:
sp_ctrl (sysA)> reconcile queue SysA for r.dbname1-r.dbname2 to flush
Note: Before executing the Reconcile command on target, issue the Flush command at source, which creates a flush marker. Even if we issue the Reconcile command first, it will wait for the flush marker to be created on the source machine. |
Rename config for PostgreSQL
Use the rename config command to give a configuration file a different name. Use a name that is unique among the configuration files on the system.
Usage
| Supported source: |
PostgreSQL (on-prem), Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Supported targets: |
PostgreSQL, Oracle, SQL Server, Kafka, Amazon RDS for PostgreSQL, Amazon Aurora for PostgreSQL, Azure Database for PostgreSQL Flexible Server, and Google Cloud SQL for PostgreSQL |
| Issued for: |
source system |
| Related commands: |
copy config, edit config, list config, view config |
Syntax
| rename config {filename to newname |
Syntax description
| filename to newname |
- filename is the name of the configuration that you want to rename. Configuration names are case-sensitive.
- to is a required part of the syntax.
- newname is the new name you are giving the configuration.
Example:
sp_ctrl(sysA)> rename config sales to sales2 |
