These instructions show you how to set up SharePlex for the purpose of sharing or distributing data from one source system to one or more target systems.
This strategy supports business requirements such as the following:
- reporting to support real-time decision making
- data sharing to support research and transparency requirements
- data integration throughout an enterprise
- customer service inquiries and other query-intensive applications
- data auditing and archiving
Supported sources
Oracle
Supported targets
All
Capabilities
This replication strategy supports the following:
- Replication to one or more target systems
- Replication between databases on the same system
- Replication between schemas in the same database (Oracle)
- Identical or different source and target names
- Use of vertically partitioned replication
- Use of horizontally partitioned replication
- Use of named export and post queues
- Use of transformation
Requirements
- Prepare the system, install SharePlex, and configure database accounts according to the instructions in the SharePlex Installation Guide.
- No DML or DDL should be performed on the target tables except by SharePlex. Tables on the target system that are outside the replication configuration can have DML and DDL operations without affecting replication.
-
If sequences are unnecessary on the target system, do not replicate them. It can slow down replication. Even if a sequence is used to generate keys in a source table, the sequence values are part of the key columns when the replicated rows are inserted on the target system. The sequence itself does not have to be replicated.
Important! These instructions assume you have a full understanding of SharePlex configuration files. They use abbreviated representations of important syntax elements.
For more information, see Configure Data Replication.
Conventions used in the syntax
In the configuration syntax in this topic, the placeholders represent the following:
- source_specification[n] is the fully qualified name of a source object (owner.object) or a wildcarded specification.
- target_specification[n] is the fully qualified name of a target object or a wildcarded specification.
- host is the name of a system where SharePlex runs. Different systems are identified by appending a letter to the names, like hostB.
- db is a database specification. The database specification consists of either o. or r. prepended to the Oracle SID, TNS alias, or database name, as appropriate for the connection type. A database identifier is not required if the target is JMS, Kafka, or a file.
Important! Configure Data Replication.
Replicate within the local system
Replication on the same system supports the following configurations:
- Within one Oracle instance, replicate to different tables within the same schema or to the same table in different schemas.
- Replicate to from an Oracle instance to any SharePlex-supported target on the same system.
Configuration options
|
datasource_specification |
|
|
| source_specification1 |
target_specification1 |
hostA[@db] |
| source_specification2 |
target_specification2 |
hostA[@db] |
Example
This example shows how you can replicate data to the same Oracle instance, to a different Oracle instance (Unix and Linux only), and to different target types, all on the same local system.
| Datasource:o.oraA |
|
|
| hr.emp |
hr.emp2 |
hostA@o.oraA |
| hr.sal |
hr.sal2 |
hostA@o.oraB |
| fin.* |
fin.* |
hostA@r.mss |
| act.* |
!file |
hostA |
Configuration when using SharePlex Manager
Replication from and to the same machine omits an Export process. However, SharePlex Manager expects an export queue to exist. If using this configuration with SharePlex Manager, you must explicitly configure an export queue as follows. The hostA* component in the routing map creates the export queue and an Export process, which sends the data to an Import process, then the post queue.
|
datasource_specification |
|
|
| source_specification1 |
target_specification1 |
hostA*hostA[@db] |
| source_specification2 |
target_specification2 |
hostA*hostA[@db] |
Replicate to a remote target system
Configuration options
|
datasource_specification |
|
|
| source_specification1 |
target_specification1 |
hostB[@db] |
| source_specification2 |
target_specification2 |
hostB[@db |
Example
The last line in this example shows how you can replicate data to different target types on the same remote target system.
| Datasource:o.oraA |
|
|
| hr.emp |
hr.emp2 |
hostB@o.oraB |
| hr.sal |
hr.sal2 |
hostB@o.oraB |
| fin.* |
!file |
hostB |
Replicate to multiple target systems
This topology is known as broadcast replication. It provides the flexibility to distribute different data to different target systems, or all of the data to all of the target systems, or any combination as needed. It assumes the source system can make a direct connection to all of the target systems. All routing is handled through one configuration file.
For more information, see Configure Replication through an Intermediary System.
Configuration options
If the target specification is identical on all targets
If the target specification of a source object is identical on all target systems, you can use a compound routing map, rather than type a separate entry for each route. For more information, see Configure Data Replication.
|
datasource_specification |
|
|
| source_specification1 |
target_specification1 |
hostB[@db]+hostC[@db][+...] |
| source_specification2 |
target_specification2 |
hostC[@db]+hostD[@db][+...] |
If the target specification is not identical on all targets
- When the target specification of a source object is different on some or all target systems, you must use a separate configuration entry to specify each one that is different.
- You can use a compound routing map for routes where the target specifications are identical.
|
datasource_specification |
|
|
| source_specification1 |
target_specification1 |
hostB[@db] |
| source_specification1 |
target_specification2 |
hostC[@db] |
Example (Oracle as a source)
Note: This example does not cover all possible source-target combinations. The last entry in this example shows the use of horizontally partitioned replication to distribute different data from the sales.accounts table to different regional databases.
| Datasource:o.oraA |
|
|
| hr.emp |
hr.emp2 |
hostB@o.oraB |
| hr.emp |
hr."Emp_3" |
hostC@r.mssB |
| hr.emp |
!jms |
hostX |
| cust.% |
cust.% |
hostD@o.oraD+hostE@o.oraE |
| sales.accounts |
sales.accounts |
!regions |
Example (PostgreSQL as a source and target)
| Datasource:r.source_DB |
|
|
| hr.emp |
hr.emp2 |
hostB@r.dbnameA |
| hr.emp |
hr."Emp_3" |
hostC@r.dbnameB |
| cust.% |
cust.% |
hostD@r.demoC+hostE@r.demoD |
Important! Use the same port number for SharePlex on all systems.
Configure Replication to Maintain a Central Datastore
These instructions show you how to set up SharePlex for the purpose of consolidated replication: replicating from multiple source systems to one central target system.
This strategy supports business requirements such as the following:
- Real-time reporting and data analysis
- The accumulation of big data into a central datastore/mart or warehouse
Supported sources
Oracle
Supported targets
Oracle and Open Target
Capabilities
This replication strategy supports the following:
- Identical or different source and target names
- Use of vertically partitioned replication
- Use of horizontally partitioned replication
- Use of named export and post queues
Requirements
-
Prepare the system, install SharePlex, and configure database accounts according to the instructions in the SharePlex Installation Guide.
- No DML or DDL should be performed on the target tables except by SharePlex. Tables on the target system that are outside the replication configuration can have DML and DDL operations without affecting replication.
-
Each source system must replicate a different set of data to the central target. If any source systems replicate the same data to the central target system, it is considered to be active-active replication. For more information, see Configure Peer-to-peer Replication .
- If sequences are unnecessary on the target system, do not replicate them. It can slow down replication. Even if a sequence is used to generate keys in a source table, the sequence values are part of the key columns when the replicated rows are inserted on the target system. The sequence itself does not have to be replicated.
Deployment options
You have two options for deploying SharePlex to replicate from many source systems to one target system.
In either deployment, if any source system cannot make a direct connection to the target system, you can use cascading replication for that route to enable SharePlex to cascade the data an intermediary system that allows connection to the target. For more information, see Configure Replication through an Intermediary System.
Note: The SharePlex compare and repair commands cannot be used in a cascading configuration.
Deploy with one instance of SharePlex on the target system
You can use one instance of SharePlex to process all incoming data on the target. For each source system, SharePlex creates an Import process on the central target system when replication starts. That, in turn, creates post queues and Post processes for each source-target replication stream, all controlled by one sp_cop process. You can control each source-target stream separately, but the post queues all share the same SharePlex variable-data directory on the target system.
A deployment with a single variable-data directory has the following potential risks:
- An event that interrupts processing to and from the disk that contains the variable-data directory will affect all replication streams.
- Any cleanup utilities that you use will affect all of the replication streams, because the cleanup is performed across the entire variable-data directory.
- A purge config command that is issued on one source system also deletes the data that is replicated from the other source systems, because the purge affects the entire variable-data directory. The use of named post queues eliminates this risk, but adds complexity to the naming, monitoring and management of the SharePlex objects in the deployment.
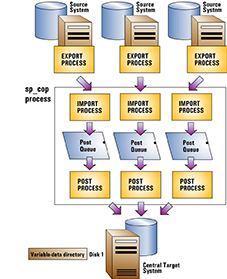
To use this deployment:
- Install SharePlex in the normal manner, with one port number and one variable-data directory on each system (sources and target).
- Make certain that when you install SharePlex, you create a database account for SharePlex for each installation.
Important! Use the same port number for SharePlex on all systems.
Deploy with multiple instances of SharePlex on the target system
You can deploy multiple instances of SharePlex on the target, one for each source system. A SharePlex instance is composed of the following elements:
- A unique sp_cop process
- A unique variable-data directory
- A unique port number on which sp_cop runs
- A unique database account that the processes of that instance use to interact with the database.
By running multiple, distinct instances of SharePlex, you can isolate each source-target replication stream from the others. It enables you to:
To use this deployment
Install on the target system first, if possible. This enables you to establish a port number for each variable-data directory, which you can then refer to when you set up SharePlex on the corresponding source system.
Steps on the target system
Select either of the setup options presented in Run Multiple Instances of SharePlex. These procedures will guide you through the steps to establish independent instances of SharePlex on the target. If you already installed SharePlex on the target, a variable-data directory, database account, and port number already exist. You can dedicate that SharePlex instance to one of the source systems, and then create additional instances on the target per those instructions.
Steps on the source systems
Install one instance of SharePlex on each source system, as directed in the SharePlex Installation Guide. Match the port numbers of those instances to the port numbers of their associated target variable-data directories. If you already installed SharePlex on the source systems, you can change the port numbers as needed. For more information, see Set the SharePlex Port Number.
Configuration
Create a configuration file on each source system that replicates the objects from that system to the central target. For more information about how to create a configuration file, see Configure Data Replication.
|
datasource_specification |
|
|
| source_specification |
target_specification |
central_host[@db] |
where:
- source_specification is the fully qualified name of a source object (owner.object) or a wildcarded specification.
- target_specification is the fully qualified name of a target object (owner.object) or a wildcarded specification.
- central_host is the target system.
- db is a database specification. The database specification consists of either o. or r. prepended to the Oracle SID, TNS alias, or database name, as appropriate for the connection type. A database identifier is not required if the target is JMS, Kafka or a file.
Example
This example shows data from datasource oraA on hostA and datasource oraB on hostB replicating to oraC on system hostC.
Data from hostA
| Datasource:o.oraA |
|
|
| hr.* |
hr.* |
hostC@o.oraC |
| fin.* |
fin* |
hostC@o.oraC |
Data from hostB
| Datasource:o.oraA |
|
|
| cust.* |
hr.* |
hostC@o.oraC |
|
mfg.* |
mfg.* |
hostC@o.oraC |
Recommended target configuration
Each source system in a consolidated configuration sends a discrete data stream that flows to its own Post process on the target. You can assign a unique identifier of your choosing to each source system, and then configure the Post process to include that identifier in each insert or update that it posts on the target.
By identifying rows in this manner, your environment is prepared to support the SharePlex compare and repair commands (which require a source ID) as well as any other work that may require the selection or identification of rows by their source. The compare and repair processes will use the source ID value to select only the rows that are valid for that source.
To configure each Post to write a source ID:
-
Create or alter the target table to include a column named SHAREPLEX_SOURCE_ID. This is the column that will contain the source ID value.
Note: You can change this name by running the target command with the set metadata option, before continuing further. See theSharePlex Reference Guide for more information.
- Choose a unique ID for each of the source systems. Any single alphanumeric string is permitted.
- On the target, run sp_ctrl for each Post process.
-
For each Post process, issue the target command with the set source option. This command sets the source ID that will be posted by that Post process. The following example shows the command for three Post processes:
sp_ctrl> target sys4 queue Q1 set source east
sp_ctrl> target sys4 queue Q2 set source central
sp_ctrl> target sys4 queue Q3 set source west
Configure Peer-to-peer Replication
These instructions show you how to set up SharePlex for the purpose of maintaining multiple databases, where applications on each system can make changes to the same data, while SharePlex keeps all of the data synchronized through replication. This is known as peer-to-peer, or active-active, replication. In this strategy, the databases are usually mirror images of each other, with all objects existing in their entirety on all systems. Although similar in benefit to a high-availability strategy, the difference between the two is that peer-to-peer allows concurrent changes to the same data, while high availability permits changes to the secondary database only in the event that the primary database goes offline.
This strategy supports the following business requirements:
- Maintain the availability of mission-critical data by operating multiple instances in different locations.
- Distribute heavy online transaction processing application (OLTP) loads among multiple points of access.
- Limit direct access to an important database, while still enabling users outside a firewall to make updates to their own copies of the data.
An example of peer-to-peer replication is an e-commerce company with three identical databases. When users access the application from a web browser, the web server connects to any of those databases sequentially in a round-robin configuration. If one of the databases is unavailable, the server connects to a different available database server. Thus the configuration serves not only as a failover resource, but also as a means of distributing the load evenly among all the peers. Should the company need to produce business reports, user access to one of the databases can be stopped temporarily, and that database can be used to run the reports.
Note: Data changes made in peer-to-peer replication are prevented from looping back from one machine to another because Capture ignores transactions performed on the local system by the Post process.
Peer-to-peer replication is not appropriate for all replication environments. It requires a major commitment to database design that might not be practical when packaged applications are in use. It also requires the development of conflict resolution routines to prioritize which transaction SharePlex posts to any given database if there are multiple changes to the same data at or near the same time.
Supported source-target combinations
Oracle to Oracle, PostgreSQL to PostgreSQL, Oracle to PostgreSQL, and PostgreSQL to Oracle
Capabilities
This replication strategy supports the following:
- Use of named export and post queues
This replication strategy does not support the following:
- Replication of LOBs. If tables with LOBs are included in replication the LOBs will be bypassed by conflict resolution, causing the potential for data to be out of synchronization.
- Column mapping and partitioned replication is not appropriate in a peer-to-peer configuration.
Requirements
- Every table involved in peer-to-peer replication must have a primary key or a unique key with no nullable columns. Each key must uniquely identify the same owner.table.row among all of the databases that will be involved in replication, and the logging of the key columns must be enabled in the database. See additional requirements in this topic.
-
Prepare the system, install SharePlex, and configure database accounts according to the instructions in the SharePlex Installation Guide.
- Enable supplemental logging for primary keys, unique keys, and foreign keys on all databases in the peer-to-peer configuration.
- Enable archive logging on all systems.
- You must understand the concepts of synchronization. For more information, see Understand the Concept of Synchronization.
-
Set the SP_OPX_CREATE_ORIGIN_PG to 1 before activation. Set it on the PostgreSQL peer for PostgreSQL to Oracle replication and on both peers for PostgreSQL to PostgreSQL replication.
Overview
In peer-to-peer replication, DML changes are allowed on copies of the same tables in different databases, usually on different systems, while SharePlex keeps them all current through replication. If a record is changed in more than one database at (or near) the same time, conflicts can occur, and conflict-resolution logic must be applied to resolve the discrepancy.
What causes a conflict in peer-to-peer replication?
To understand how SharePlex determines a conflict, refer to the following examples of normal and conflict situations. In the examples, three systems (SysA, SysB and SysC) are used. For the detailed information about what is a conflict, see What is a conflict?
The following tables are used in the example:
Scott.employee_source
jane.employee_backup
The column names and definitions are identical:
| EmpNo |
number(4) not null, |
| SocSec |
number(11) not null, |
| EmpName |
char(30), |
| Job |
char(10), |
| Salary |
number(7,2), |
| Dept |
number(2) |
The values for both tables in a synchronized state are:
| 1 |
111-22-3333 |
Mary Smith |
Manager |
50000 |
1 |
| 2 |
111-33-4444 |
John Doe |
Data Entry |
20000 |
2 |
| 3 |
000-11-2222 |
Mike Jones |
Assistant |
30000 |
3 |
| 4 |
000-44-7777 |
Dave Brown |
Manager |
45000 |
3 |
Example of peer-to-peer replication without a conflict
- At 9:00 in the morning, UserA on SysA changes the value of the Dept column to 2, where EmpNo is 1. SharePlex replicates that change to SysB and SysC, and both databases remain synchronized.
- At 9:30 that same morning, UserB on SysB changes the value of Dept to 3, where EmpNo is 1. SharePlex replicates that change to SysA and SysC, and the databases are still synchronized.
Now the row looks like this:
| EmpNo (key) |
SocSec |
EmpName |
Job |
Salary |
Dept |
| 1 |
111-22-3333 |
Mary Smith |
Manager |
50000 |
3 |
Example of peer-to-peer replication with an UPDATE conflict
- At 11:00 in the morning, UserA on SysA updates the value of Dept to 1, where EmpNo is 1. At 11:02 that morning, the network fails. Captured changes rest in the export queues on all systems.
- At 11:05 that morning, before the network is restored, UserB on SysB updates the value of Dept to 2, where EmpNo is 1. The network is restored at 11:10 that morning. Replication data transmission resumes.
- When SharePlex attempts to post the change from UserA to the database on SysB, it expects the value in the Dept column to be 3 (the pre-image), but the value is 2 because of the change made by UserB. Because the pre-images do not match, SharePlex generates an out-of-sync error.
- When SharePlex attempts to post the change from UserB to SysA, it expects the value of the column to be 3, but the value is 1 because of the change made by UserA. SharePlex generates an out-of-sync error.
- When SharePlex attempts to post the changes made by UserA and User B to the database on SysC, both of those statements fail because the pre-images do not match. SharePlex generates an out-of-sync error.
Note: For more information, see Appendix A: Peer-To-Peer Diagram.
Deployment
To deploy peer-to-peer replication, perform the following tasks:
- Evaluate the data for suitability to a peer-to-peer environment. Make any recommended alterations. For more information, see Evaluate the data.
- Configure SharePlex so that data from each system replicates to all other systems in the peer-to-peer environment. For more information, see Configure Oracle to Oracle Replication.
- Develop conflict resolution routines that provide rules for how Post handles conflicts. For more information, see Set up conflict resolution routines.
- Create a conflict resolution file. SharePlex refers to this file to determine the correct procedure to use when a conflict occurs. For more information, see Configure Peer-to-peer Replication .
Evaluate the data
To successfully deploy SharePlex in a peer-to-peer configuration, you must be able to:
- isolate keys
- prevent changes to keys
- control sequence generation
- control trigger usage
- eliminate cascading deletes
- designate a trusted host
- define priorities
These requirements must be considered during the architectural phase of the project, because they demand cooperation with the application. Consequently, many packaged applications are not suitable for a peer-to-peer deployment because they were not created within those guidelines.
Following are more detailed explanations of each of the requirements.
Keys
The only acceptable key in peer-to-peer replication is a primary key. If a table has no primary key but has a unique, not-NULL key, you can convert that key to a primary key. LONG columns cannot be part of the key.
If you cannot assign a primary key, and you know all rows are unique, you can create a unique index on all tables.
The primary key must be unique among all of the databases in the peer-to-peer replication network, meaning:
- it must use the same column(s) in each corresponding table in all databases.
- key columns for corresponding rows must have the same values.
The primary key must be created to contain enough information about a row so there can be no question about the uniqueness of that row, and so that there will be a conflict if a replicated operation would violate uniqueness.
The primary key value cannot be changed.
Supplemental logging of primary and unique keys must be enabled in the database.
Using only a sequence as the primary key probably will not suffice for peer-to-peer replication. For example, suppose the sample table uses sequences to generate values for key column EmpNo. Suppose UserA gets the next sequence value on SysA and inserts a row for “Jane Wilson.” UserB gets the next sequence value on SysB and also inserts a row for “Jane Wilson.” Even if the sequence numbers are different on each system, so there are no unique key violations on the replicated INSERTs, data integrity is compromised because there are now two entries for “Jane Wilson” in the databases, each with a different key. Subsequent UPDATEs will fail. The solution is to include other unique columns in the key, so that there is enough information to ensure uniqueness and ensure a conflict that can then be resolved through resolution logic.
Sequences
SharePlex does not support peer-to-peer replication of sequences. If the application uses sequences to generate all or part of a key, there must be no chance for the same range of values to be generated on any other system in the peer-to-peer configuration. You can use a sequence server or you can maintain sequences separately on each server and make sure you partition a unique range to each one. Quest recommends using n+1 sequence generation (where n = the number of systems in replication). Depending on the type of application, you can add a location identifier such as the system name to the sequence value in the primary key to enforce uniqueness.
Triggers
DML changes resulting from triggers firing on a source system enter the redo log and are replicated to the target system by SharePlex. If the same triggers fire on the target system, they return out-of-sync errors.
To handle triggers in a peer-to-peer configuration, you can do either of the following:
- Disable the triggers.
- Keep them enabled, but alter them to ignore the SharePlex user on all instances in the peer-to-peer configuration. SharePlex provides the sp_add_trigger.sql script for this purpose. This script puts a WHEN clause into the procedural statement of the trigger that tells it to ignore the Post process. For more information, see Set up Oracle Database Objects for Replication.
ON DELETE CASCADE constraints
ON DELETE CASCADE constraints can remain enabled on all instances in the peer-to-peer replication configuration, but you must set the following parameters to direct Post to ignore those constraints:
- SP_OPO_DEPENDENCY_CHECK parameter to 2
- SP_OCT_REDUCED_KEY parameter to 0
- SP_OPO_REDUCED_KEY parameter to 0 (although in other replication scenarios this parameter can be set to different levels, it must be set to 0 in a peer-to-peer configuration)
Balance values maintained by using UPDATEs
Applications that use UPDATE statements to record changes in quantity, such as inventory or account balances, pose a challenge for peer-to-peer replication. The following example of an online bookseller explains the reason why.
The bookseller’s Inventory table contains the following columns.
Book_ID (primary key)
Quantity
Suppose the following sequence of events takes place:
- A customer buys a book through the database on one server. The quantity on hand reduces from 100 books to 99. SharePlex replicates that UPDATE statement to the other server. (UPDATE inventory SET quantity = 99 WHERE book_ID = 51295).
- Before the original UPDATE arrives, another customer buys two copies of the same book on another server (UPDATE inventory SET quantity = 98 WHERE book_ID = 51295), and the quantity on that server reduces from 100 books to 98.
- When the Post process attempts to post the first transaction, it determines that the pre-image (100 books) on the first system does not match the expected value on the second system (it is now 98 as a result of the second transaction). Post returns an out-of-sync error.
A conflict resolution procedure could be written, but how would the correct value be determined? The correct value in both databases after the two transactions should be 97 books, but no matter which of the two UPDATE statements is accepted, the result is incorrect.
For this reason, peer-to-peer replication is not recommended for applications maintaining account or inventory balances using UPDATEs. If you can use a debit/credit method of maintaining balances, you can use INSERT statements (INSERT into inventory values “n”,...) instead of UPDATE statements. INSERT statements do not require a before-and-after comparison with a WHERE clause, as do UPDATE statements.
If your application must use UPDATE statements, you can write a conflict resolution procedure to determine the absolute (or net) change resulting from different UPDATE statements on different systems. For example, in the case of the preceding online bookseller example, when the first customer’s purchase is replicated to the second system, the following conflict resolution procedure fires:
if existing_row.quantity <> old.quantity then old.quantity - new.quantity = quantity_change; update existing_row set quantity = existing_row.quantity - quantity_change;
The conflict resolution logic tells SharePlex that, if the quantity value of the existing row in the target database (98) does not equal the old value (pre-image of 100), then subtract the new value (the replicated value of 99) from the pre-image to get the net change (1). Then, issue an UPDATE statement that sets the Quantity column to 98-1, which equals 97.
When the second user’s change is replicated to the first system, the same conflict resolution procedure fires. In this case, the net change (pre-image of 100 minus the new value of 98) is 2. The UPDATE statement on this system also results in a value of 97, which is 99 (the existing row value after the first customer’s purchase) minus the net change of 2. The result of this procedure’s logic is that the Quantity columns on each system are updated to 97 books, the net effect of selling three books.
The following example illustrates this concept using an account balance within a financial record:
account_number (primary key)
balance
- Suppose a row (an account) in the example table has a balance of $1500 on SysA. CustomerA makes a deposit of $500 on that system. The application uses an UPDATE statement to change the balance to $2000. The change is replicated to SysB as an UPDATE statement (such as UPDATE...SET balance=$2000 WHERE account_number=51295).
- Before the change arrives, CustomerA’s spouse makes a withdrawal of $250 on SysB, and the application updates the database on that system to $1250. When CustomerA’s transaction arrives from SysA and Post attempts to post it to SysB, there is a conflict, since the pre-image from the source system is $1500, but the pre-image on the target is $1250 because of the spouse’s transaction — not a match.
You can write a conflict resolution routine to accommodate this kind of transaction by calculating the absolute (or net) change in the account, then using that value to resolve the conflict. For example:
if existing_row.balance <> old.balance then old.balance - new.balance = balance_change; update existing_row set balance = existing_row.balance - balance_change;
The result of this procedure would be to update the account balance to $1750, the net effect of depositing $500 and withdrawing $250. On SysB, the routine directs SharePlex to subtract the new (replicated) balance of 2000 from the old balance of 1500 for a net change of -500. The UPDATE statement sets the balance value to 1250 - (-500) = 1750, the correct value.
On SysA, the replicated value of 1250 is subtracted from the old balance of 1500 to get the net change of 250. The UPDATE statement subtracts that value from the existing balance of 2000 to get the correct value of 1750.
Priority
When the environment is established to avoid or resolve conflict when SharePlex searches for the correct row to change, the only remaining conflict potential is on fact data — which change to accept when the values for the same column in the same row differ on two or more systems. For this, your application must be able to accept the addition of timestamp and source columns, with source being the name of the local system for the table.
The following explains how those columns play a vital role when using a conflict resolution routine to establish priority.
Trusted source
You must assign a particular database or server to be the prevailing, or trusted, source for two reasons:
- The conflict resolution routine has the potential to get quite large and complex the more systems you have. There are bound to be failures that require resynchronization at some point. One of the systems in the configuration must be considered the true source from which all other systems will be resynchronized if necessary.
- You can write your conflict resolution routines so that operations from the trusted source system take priority over conflicting operations from other systems. For example, changes on the server at corporate headquarters could take priority over the same changes made by a branch office.
Timestamp
It is recommended that you include a timestamp column in the tables and assign priority in the conflict resolution routine to the earliest or latest timestamp. However, the timestamp must not be part of a key, or it will cause conflicts. SharePlex cannot locate rows if a key value changes — and the key value will change if one of the columns is a timestamp.
For timestamp priority to work, you must make sure all of the servers involved agree on the date and time. Tables on servers in different time zones can use Greenwich Mean Time (GMT).
To handle the situation where servers involved are in different time zones, you can specify a 'TIMESTAMP WITH LOCAL TIME ZONE' column in tables to be used by the routine, and make sure that the 'DBTIMEZONE' of databases in peer to peer replication is the same.
The default date format for SharePlex conflict resolution is MMDDYYYY HH24MISS. Tables with default dates must use that format, or conflict resolution will return errors. Before creating a table with a default date, use the following command to change the date format in SQL*Plus.
ALTER SESSION SET nls_date_format = 'MMDDYYYYHH24MISS'
Configure Oracle to Oracle Replication
The configuration files on the systems in a peer-to-peer configuration are identical with the exception of the datasource specification and the routing.
Conventions used in the syntax
In the configuration syntax in this topic, the placeholders represent the following items in the environment. This documentation assumes three systems, but there can be more.
Important! See Configure Data Replication for more information about the components of a configuration file.
Configuration on hostA
|
Datasource:o.oraA |
| ownerA.object |
ownerB.object |
hostB@o.oraB |
| ownerA.object |
ownerB.object |
hostB@o.oraB |
| ownerA.object |
ownerC.object |
hostC@o.oraC |
| ownerA.object |
ownerC.object |
hostC@o.oraC |
Note: If all owner names and table names are the same on all systems, you can use a compound routing map for each of these configuration files.
For example, the compound routing for replication from hostA is as follows:
| Datasource:o.oraA |
| owner.object |
owner.object |
hostB@o.oraB+hostC@o.oraC |
Configuration on hostB
|
Datasource:o.oraB |
| ownerB.object |
ownerA.object |
hostA@o.oraA |
| ownerB.object |
ownerA.object |
hostA@o.oraA |
| ownerB.object |
ownerC.object |
hostC@o.oraC |
| ownerB.object |
ownerC.object |
hostC@o.oraC |
Configuration on hostC
|
Datasource:o.oraC |
| ownerC.object |
ownerA.object |
hostA@o.oraA |
| ownerC.object |
ownerA.object |
hostA@o.oraA |
| ownerC.object |
ownerB.object |
hostB@o.oraB |
| ownerC.object |
ownerB.object |
hostB@o.oraB |
Example
| Datasource:o.oraA |
| hr.emp |
hr.emp |
hostB@o.oraB |
| hr.sal |
hr.sal |
hostB@o.oraB |
| cust.% |
cust.% |
hostB@o.oraB |
Set up conflict resolution routines
For information on setting up the conflict resolution routines for Oracle to Oracle, see User defined conflict resolution routines for Oracle to Oracle.

