
Sample Scenario
In this example, InTrust workflow is configured in the following way:
- There are 3 InTrust servers (IT01, IT02 & IT03) in the InTrust Organization
- One Workflow Task (WFT1) was configured, containing 3 Workflow Jobs (WFJ1, WFJ2, WFJ3)
- Workflow jobs (WFJ1, WFJ2, and WFJ3) are run by IT01, IT02, and IT03 InTrust Servers, respectively
- Jobs WFJ1 and WFJ2 have no job dependencies
- Job WFJ3 depends on both WFJ1 and WFJ2
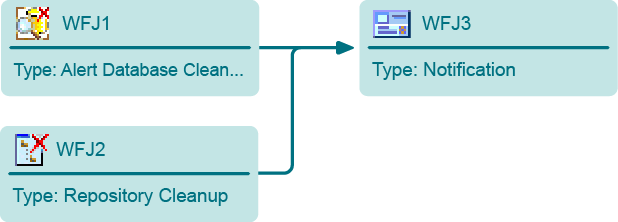
Workflow Communication During Task Processing
Workflow communication during task processing is described below:
- All 3 InTrust servers create their own instance of the WorkflowManager (WM) component and start the task.
- The WM components on InTrust Servers IT01 and IT02 start their respective jobs (WFJ1and WFJ2) as these jobs do not have any dependencies
- The WM component on InTrust Server IT03 communicates through port 8340 with InTrust Servers IT01 and IT02 to check the status of the WFJ1 andWFJ2 jobs, as WFJ3 depends on both of these jobs
- If IT03 cannot connect to all InTrust servers running predecessor jobs (IT01 & IT02 in this example), then it starts WFJ3.
- If IT03 can connect, but the predecessor job is not running, then it waits for 10 minutes
- If IT03 can connect, but the predecessor job is not running for more than 10 minutes, it logs an error and then starts WFJ3
- If IT03 can connect and the predecessor job is running, it waits for 10 minutes or until a notification is received (within the 10 minute period), then it again polls the InTrust servers (IT01 & IT02) for the status of the predecessor jobs.
- When a predecessor job is complete (WFJ1 for example), the WM on the InTrust server (IT01) notifies the other InTrust Servers that are responsible for jobs within the task (IT02 & IT03), that the job has been completed.
Gathering
Event data gathering runs in the GatheringEngine.exe executable; a separate instance of this executable is created for each gathering job.
If required, gathering pre-empts agent installation. In case of using agent-based gathering, the agent configuration is updated (via local agent), regardless of whether the configuration has changed. GatheringEngine receives data from the remote agent via local (server-side) agent.
Agentless gathering collects data directly from the remote computer. This type of gathering is only supported for logs from Windows based computers and custom text logs from non-Windows based computers using SAMBA shares.
The collected data is stored in the repository and/or audit database; data uniqueness is determined by combination of Date/Time, Record Number, Computer and Log (audit database only).
The GatheringEngine works, as follows:
- The GatheringEngine (GE) component reads the configuration from the configuration database, then it initiates the site enumeration process
- Next, it queries the InTrust Server Service for agent availability (if gathering with agent):
- If the remote agent is not installed, then it initiates agent installation
- Agents are only installed if the Prohibit automatic agent deployment on site computers option is not selected
- If the agent is already installed, and gathering job is configured to use agents, then the option takes no effect, and agent-based gathering takes place.
Agent-Based Gathering
In the case of agent-based gathering, the process runs in the following way:
- The GatheringEngine sends the configuration to the remote agent
- The GatheringEngine asks the remote agent for data and waits to receive it
- The remote agent reads the data either from the event log or the client-side cache (agent-side log backup) (depending on the caching settings)
- The remote agent applies filters and writes temporary files in the ‘Repository File’ format:
- At least 1 ‘Repository File’ for gathering to a repository
- At least 1 ‘Repository File’ for gathering to an audit database
- The number of ‘Repository Files’ is dependent on the size of the data (Max 8MB uncompressed - configurable)
- The temporary files are communicated to GatheringEngine:
- When a buffer size reaches 8MB (configurable) of event data, the 'Repository File' is ready to delivery
- The remote agent waits for acknowledgement from GatheringEngine (i.e., GatheringEngine is ready to receive new data)
- The remote agent sends data to GatheringEngine. Note that new data will not be written to a 'Repository File' if the previous file is not sent; also, the agent must be notified by GatheringEngine about data successfully put into a storage
- The GatheringEngine writes the temporary ‘Repository File’ into a temporary folder on the InTrust server
- If data is being gathered to a repository, the ‘Repository File’ is moved to the repository
- If data is being gathered to an audit database, the data is extracted from the ‘Repository File’ and imported into the audit database