A clustered index is critical to performance on any table. Not only does it dictate the logical storage of data for the entire table, but it also is the index that all others will reference when additional data is required. A poorly chosen clustered index can greatly hamper performance, causing latency, contention, and excessive IO. In this article, we will explore clustered indexes, and use ApexSQL Tools to assist in identifying those that could be improved upon.
Choosing a clustered index is an important decision on every table that we design and implement. The performance will be adversely affected if we do not implement a clustered index, or if we make a poor choice.
When initially designing a table, we need to understand its usage and how data will be inserted, updated, deleted, and read. As part of this process, we will need to choose indexes that best support any important reads against the table. Non-clustered indexes are added onto our table to support important/frequent queries and we can add many of these onto our table as time goes on. We can also remove unneeded non-clustered indexes when no longer needed.
The clustered index is not so easily changed, and therefore we want to choose it correctly the first time if at all possible. In the event that a table’s use changes greatly over time, or that poor decisions were made in its design, we need to figure out that a problem exists and respond to it as quickly as possible.
The clustered index should point to a unique, static key - that is, something that does not change over time and in which each row is unique. It should be the key that an application refers to most often when searching for, joining, or returning data. This likely will make the clustered index a good candidate for the primary key as well. Under the covers, SQL Server needs to logically organize data into pages based on how me implement our table. Duplicate values result in the need for SQL Server to create unique pointers in order to ensure that a query returns the correct value(s). It also means that we may have no good way to identify a single row using the clustered index alone.
In the event that a clustered index is not the primary key, I’d recommend that it at least be a unique clustered index, ensuring that there are no duplicated values. Typically, a well-designed table will have some sort of unique identifier built into it, either:
A clustered index should be static. Once a key is generated and inserted, it will not be updated over time. Deletes are acceptable as needed, but updates to the clustered index will result in additional latency. When a clustered key value is updated, all non-clustered indexes must also be updated, which will take additional time, CPU, network, and IO resources. Deletes are also expensive, so if we have any important archiving or mas-delete processes, they would best be managed during staggered/off-hours times, in order to ensure that there isn’t too much churn from the deletes at one time.
A performant clustered index will often be always-increasing over time. This means that, as new values are inserted, they are always greater than the previous value. In theory, an ever-decreasing key would also be valid (for a clustered index that is sorted in descending order), though this would likely be confusing to developers and other database professionals. A clustered index that increases over time will become less fragmented and experience far less page-splits during its regular usage. Imagine a new clustered index that has been built and is 100% in order with no gaps. When a value is inserted into the middle of the index, one of three things happens:
An index that increases over time will generally experience far fewer page splits (scenario #2 above) as a page will continue to be filled up until either it is full or reaches the limit that is set by an index’s fill factor.
Lastly, a good clustered index should be as narrow as possible. For a small metadata table that may never have more than a few hundred rows, a SMALLINT key is likely perfect for a numeric key. If a clustered index happens to be a composite key (made up of multiple columns), then each one should be as small as possible. We should not create extra work in the future, of course - if we know that a table will likely one day grow very large, then make sure that your key is as large as is necessary, whether SMALLINT, INT, or BIGINT. DATE, SMALLDATETIME, DATETIME, DATETIMEOFFSET, and other date/time-based columns can also make good clustered keys, assuming that values will not be duplicated. Date tables, numbers tables, warehouse time tables, and other reporting needs can make great use of date/time clustered indexes.
To summarize, a well-chosen clustered index will be:
A clustered index may also be the primary key, but it does not have to. Some tables may have multiple meaningful keys and choosing a different clustered index may make sense in these scenarios. Unique non-clustered indexes are also good choices, in the event that a good clustered index has already been chosen.
We can demonstrate the effects of a good vs. bad clustered index using pretty much any table that already has one that is reasonably well-chosen. For this example, we will use the Sales.SalesOrderHeader table in the AdventureWorks demo database. The copy that I have has been inflated from about 31,500 rows to 1,290,065 rows. Similarly, Sales.SalesOrderDetail, which is often joined with it, has been increased from 121,317 rows to 4,973,997 rows. This will magnify the problems associated with poorly chosen clustered indexes.
For our first example, we’ll illustrate the effects of a non-unique clustered index on the SalesOrderHeader table. Consider the following query:
SELECT * FROM Sales.SalesOrderHeader INNER JOIN Sales.SalesOrderDetail ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID WHERE OrderDate = '12/10/2015';
This pulls all header and detail data for any orders placed on 12/210/2015. Since there is no index on OrderDate, the resulting execution plan will require a clustered index scan in order to find the data it needs and return it. The current clustered index on the table is on SalesOrderID, a unique identity column. We will run the above query and then change the clustered index to a less-optimal column, such as DueDate:
ALTER TABLE Sales.SalesOrderHeader DROP CONSTRAINT PK_SalesOrderHeader_SalesOrderID; GO CREATE CLUSTERED INDEX CI_SalesOrderHeader ON Sales.SalesOrderHeader (DueDate ASC); GO
Once this change is made, we’ll run the query again and compare the before vs. after execution plan and IO statistics incurred by each execution:
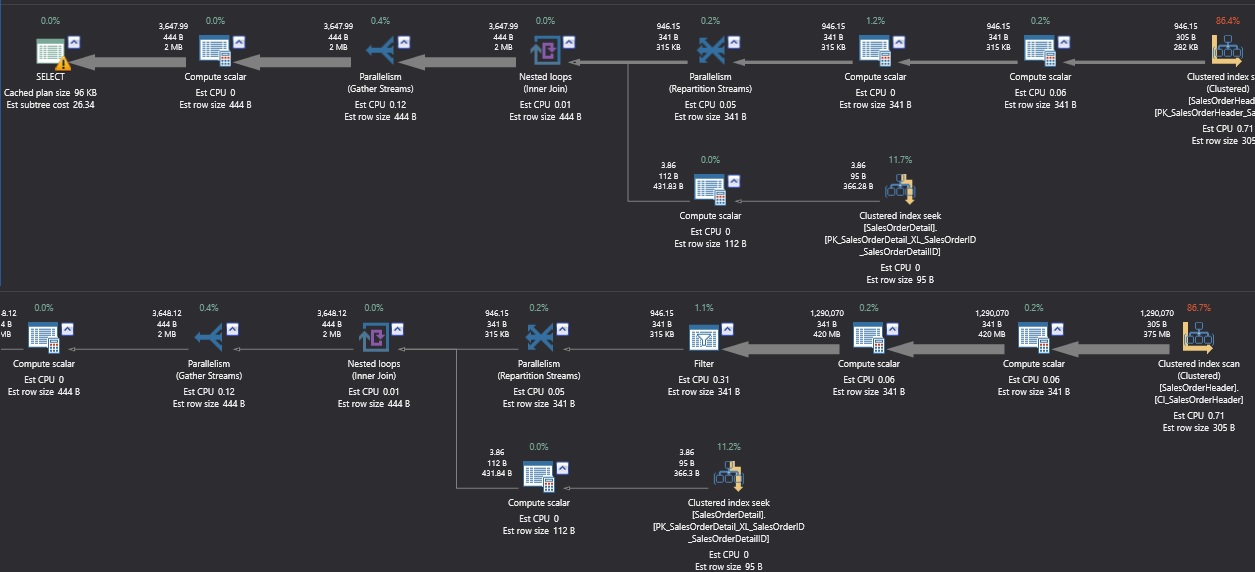
The execution plans are similar - with the greatest cost being the scan against SalesOrderHeader, which is required to satisfy our query, regardless of either of our clustered index choices. The statistics IO looks like this:
Table 'SalesOrderHeader'. Scan count 5, logical reads 30010, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetail'. Scan count 977, logical reads 3243, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderHeader'. Scan count 5, logical reads 31631, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetail'. Scan count 977, logical reads 3243, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Note that when we ran this query against the table with DueDate as the clustered index, an additional 1,621 reads were needed. Storing non-unique clustered indexes, as well as non-clustered indexes on these tables is less efficient, and the cost we pay is in IO, and subsequently in performance. On modern cloud-hosted systems, we directly pay for resource costs based on usage, so the more efficiently we can design our tables, the more money we can save and the better our queries will perform.
Let’s reconsider the above scenario, but this time with a non-clustered covering index on SalesOrderHeader.OrderDate, including a handful of other columns. This is a more realistic query scenario simulating an important, frequently run query that warrants its own index. This will allow us to judge the effects of a poorly chosen clustered index with reference to index seeks against the table. Here is the new index we will add:
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate ON Sales.SalesOrderHeader (OrderDate) INCLUDE ( SalesOrderID ,DueDate ,ShipDate ,STATUS );
Now we’ll run our query from earlier:
SELECT SalesOrderHeader.OrderDate ,SalesOrderHeader.DueDate ,SalesOrderHeader.ShipDate ,SalesOrderHeader.STATUS ,SalesOrderDetail.UnitPrice FROM Sales.SalesOrderHeader INNER JOIN Sales.SalesOrderDetail ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID WHERE OrderDate = '12/10/2015';
When executed, IO statistics and the execution plan look like this:
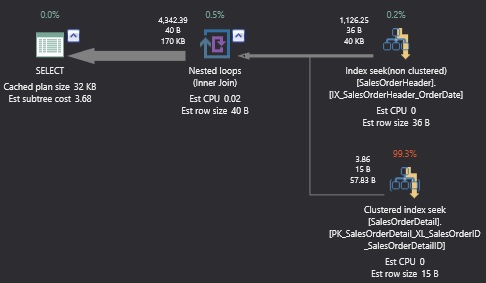
Table 'SalesOrderDetail'. Scan count 977, logical reads 3165, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderHeader'. Scan count 1, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Now, let’s adjust the clustered indexes on each table to be other columns that could, conceivably, be used instead:
ALTER TABLE Sales.SalesOrderHeader DROP CONSTRAINT PK_SalesOrderHeader_SalesOrderID; CREATE CLUSTERED INDEX CI_SalesOrderHeader ON Sales.SalesOrderHeader (RevisionNumber ASC); ALTER TABLE Sales.SalesOrderDetail DROP CONSTRAINT PK_SalesOrderDetail_XL_SalesOrderID_SalesOrderDetailID; CREATE CLUSTERED INDEX CI_SalesOrderDetail ON Sales.SalesOrderDetail (CarrierTrackingNumber ASC); CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_SalesOrderId ON dbo.SalesOrderDetail (SalesOrderId);
The additional index on SalesOrderId ensures that the INNER JOIN between tables is not trashed by our changes. We run our test query again and the results are as follows:
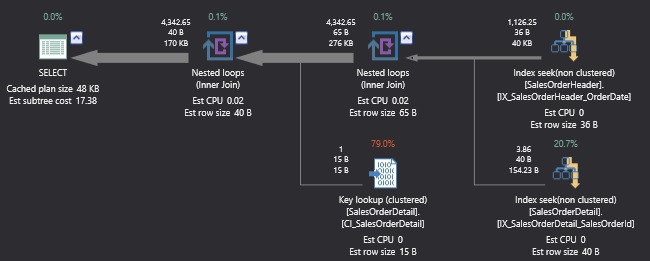
Table 'SalesOrderDetail'. Scan count 977, logical reads 12954, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderHeader'. Scan count 1, logical reads 9, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We can clearly see that, even though the execution plans and the basic operators are very similar, the reads are significantly higher against the table with a poorly chosen clustered index.
We can perform other demonstrations of INSERT, UPDATE, DELETE, as well as maintenance operations and show that all of them suffer as a result of our bad decision-making. I think we get the idea, though, and can now move onto solving problems!
Mocking up scenarios in which poorly chosen clustered indexes have been implemented is not too difficult, but our true goal here is to have a tool that can help us find these problems for us, before they become serious. We want to be able to detect design mistakes quickly, before performance problems impede an application’s ability to function.
A suboptimal clustered index will often manifest itself as a set of symptoms, rather than a distinct and obvious alert. Some possible symptoms may be:
ApexSQL Monitor allows for the creation of custom reports and alerts that can be used in order to measure metrics that can tell us about the issues above, and then let us know when a desired threshold has been exceeded. Once we know that an issue has been identified, we can use waits, query, and server metrics to justify any decisions we make based on the alert. As with all custom alerts that we create, there will be a need for tweaking to ensure that we are only alerted when an action truly is needed. Alert too often and we ignore it, while alerting too infrequently means that we respond late to legitimate problems.
The custom metrics we create can encompass ANY query, so long as that query returns a single numeric value. As with any opportunity to enter TSQL without bounds, I will choose to stretch that opportunity as far as humanly possible :-)
The first query we can run as a custom alert validates the uniqueness of a clustered index. It’s a very simple query that returns a 1 if any nonunique clustered indexes exist for which there are non-unique values:
SET NOCOUNT ON; SELECT indexes.NAME AS Index_Name ,schemas.NAME AS [Schema_Name] ,tables.NAME AS Table_Name ,columns.NAME AS Column_Name ,CAST(0 AS BIT) AS Has_Non_Unique_Clustered_Index_Values ,CAST(0 AS BIT) AS Is_Processed INTO #Non_Unique_Clustered_Indexes FROM sys.indexes INNER JOIN sys.tables ON indexes.object_id = tables.object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id INNER JOIN sys.index_columns ON index_columns.index_id = indexes.index_id AND index_columns.object_id = tables.object_id INNER JOIN sys.columns ON columns.object_id = index_columns.object_id AND columns.column_id = index_columns.column_id WHERE indexes.type_desc = 'CLUSTERED' AND indexes.is_unique = 0 ORDER BY tables.NAME; DECLARE @Clustered_Index NVARCHAR(MAX); DECLARE @Schema_Name NVARCHAR(MAX); DECLARE @Table_Name NVARCHAR(MAX); DECLARE @Results TABLE (Value_Count BIGINT); DECLARE @Has_Non_Unique_Clustered_Index_Values BIT; SELECT TOP 1 @Clustered_Index = Index_Name ,@Schema_Name = [Schema_Name] ,@Table_Name = [Table_Name] FROM #Non_Unique_Clustered_Indexes; WHILE EXISTS ( SELECT * FROM #Non_Unique_Clustered_Indexes WHERE Is_Processed = 0 ) BEGIN DECLARE @Sql_Command NVARCHAR(MAX) = 'SELECT TOP 1 '; SELECT @Sql_Command = @Sql_Command + ' COUNT(*)' SELECT @Sql_Command = @Sql_Command + ' FROM [' + @Schema_Name + '].[' + @Table_Name + '] GROUP BY '; SELECT @Sql_Command = @Sql_Command + ' [' + Column_Name + '],' FROM #Non_Unique_Clustered_Indexes WHERE Index_Name = @Clustered_Index; SELECT @Sql_Command = LEFT(@Sql_Command, LEN(@Sql_Command) - 1); SELECT @Sql_Command = @Sql_Command + ' HAVING COUNT(*) > 1;'; INSERT INTO @Results (Value_Count) EXEC sp_executesql @Sql_Command; IF EXISTS ( SELECT * FROM @Results WHERE Value_Count IS NOT NULL AND Value_Count > 0 ) BEGIN SELECT @Has_Non_Unique_Clustered_Index_Values = 1; END ELSE BEGIN SELECT @Has_Non_Unique_Clustered_Index_Values = 0; END UPDATE #Non_Unique_Clustered_Indexes SET Has_Non_Unique_Clustered_Index_Values = @Has_Non_Unique_Clustered_Index_Values ,Is_Processed = 1 WHERE Index_Name = @Clustered_Index; DELETE FROM @Results; SELECT TOP 1 @Clustered_Index = Index_Name ,@Schema_Name = [Schema_Name] ,@Table_Name = [Table_Name] FROM #Non_Unique_Clustered_Indexes WHERE Is_Processed = 0; END IF EXISTS ( SELECT * FROM #Non_Unique_Clustered_Indexes WHERE Has_Non_Unique_Clustered_Index_Values = 1 ) BEGIN SELECT 1; END ELSE BEGIN SELECT 0; END DROP TABLE #Non_Unique_Clustered_Indexes;
The TSQL above will check system views for any clustered indexes that happen to not be unique and will then select and group data from each of their corresponding tables to determine if there are any duplicate clustered index values. If you have very large tables in your database, then you could simply check for non-unique clustered indexes and not take the additional step to grind through each table searching for dupes. This allows us to determine if a clustered index is unique (which is good!) or not.
The result boils down to either a 0 or a 1:

Not terribly exciting. We could adjust the query to return details, but our goal is an infrequent check to validate that a clustered index isn’t duplicate. It will usually return 0 and we’ll know everything is OK. In ApexSQL Monitor, we can create a custom metric as follows:
From Configuration, choose Custom Metrics, and we can begin filling out the details for our query:
“%Database%” signifies that this is a database-specific query, though is not necessary if the “Database Performance” category is selected. I include it so that if it is needed, it’s there, and if not, there’s no harm done. Otherwise, the rest of the TSQL is the same as the query we introduced previously. We will use this same basic method of adding custom metrics later in this article. 86,400 seconds is a full day. It could run less frequently (or more) if needed. Schema typically changes infrequently, but it’s up to you as to how often to check. Once created, we could alert on this, or just check it every so often to see if it’s the acceptable value (0).
In the example above, we still have the index changes from earlier, in which SalesOrderHeader and SaleOrderDetail were given new clustered indexes. These were not unique, contain NULLs, not ever-increasing, and not static, making them lousy candidates for a clustered index.
