Part 1 of this series describes some basics about performance baselining, while Part 2 explains how to establish and use baselining for detecting SQL Server performance issues in SQL Server using user defined tables, scripts and baseline calculations. In this final article, we’ll demonstrate how to implement baselining with a 3rd party tool, including some value-added functionality
It is important to understand that the ability to establish proper baseline for different SQL Server performance metrics is not important just for the purpose of comparing the performance metrics data against the baselined “good” data in order to detect SQL Server performance anomalies. Using baselines, in general, is very important for troubleshooting and fixing SQL Server affected by performance issues
Making all that possible, in a robust and repeatable manner, with manual methods is out of reach for accidental and less experienced DBAs reach, while experienced DBAs may not have the time for establishing and maintaining the baselining manually
And this is where performance monitoring tool like ApexSQL Monitor can be of great help for any DBA regardless of the experience level. ApexSQL Monitor comes with built-in ability to baseline SQL Server performance metrics including wait statistic data, and to calculate standard deviations that will be used for alerts thresholds calculation, and finally to graphically convey the calculated baseline values and thresholds and present them directly in ApexSQL Monitor charts
When baselining performance metrics, it is important to know what the “good” period for SQL Server is, namely the continuous SQL Server period without performance issues or serious problems. Once the required period is determined, it should be used for calculating the baseline. The longer the period that will be used for calculation is, the more relevant and more precise the baseline calculation will be since more data will be used for calculations (larger and more representative statistical data sample will be used for baselining)
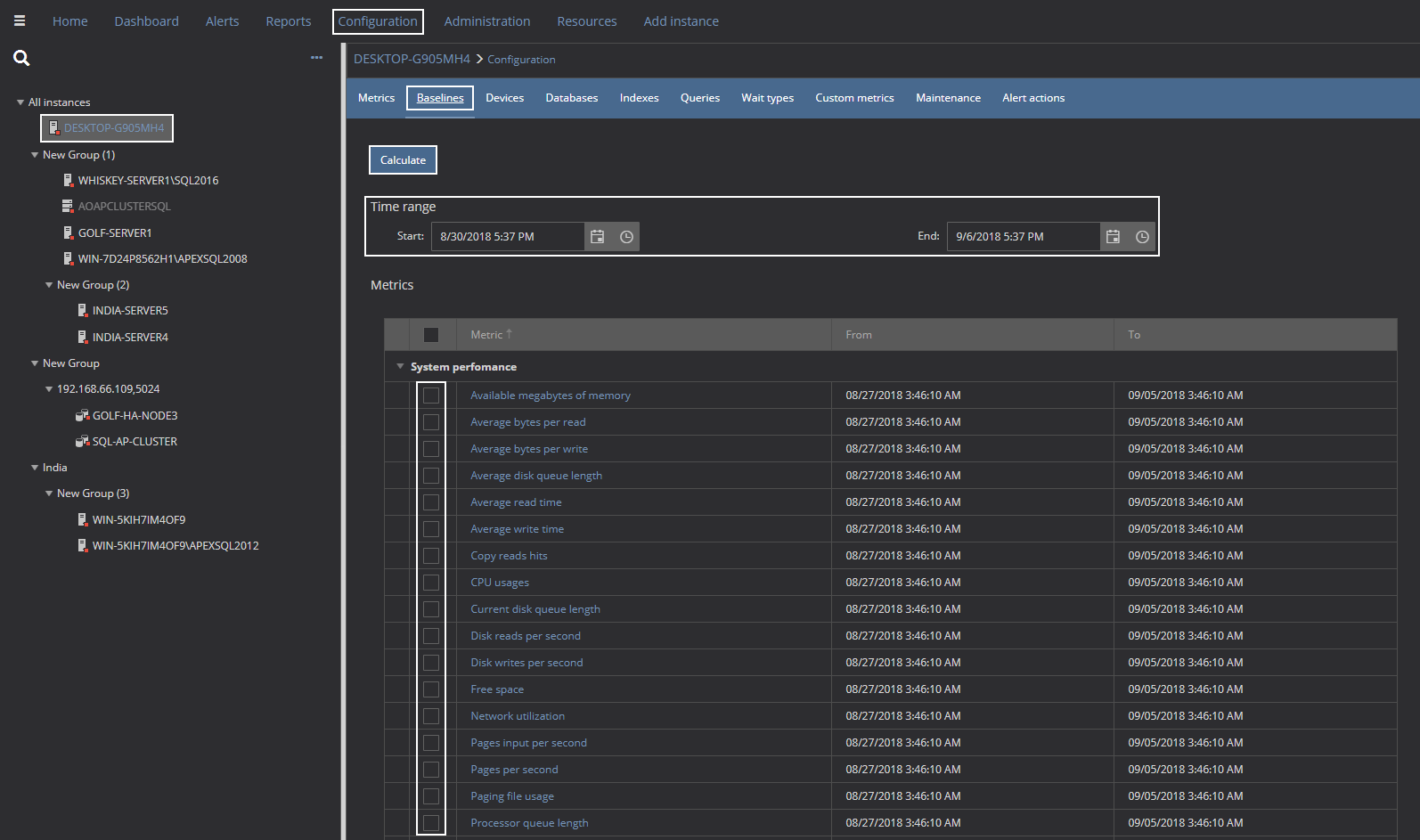
In the left SQL Server instances list pane select the SQL Server instance for which the baseline calculation should be performed
Click Configuration button in the main menu bar
The metrics configuration screen will be displayed and then click on the Baselines link
In the Baselines pane, select the period for which the baseline calculation should be performed. At least 7 days of data is required for calculating baselines
By default, none of the metrics are selected for baseline calculation. Check the metrics that should be included in calculation
After pressing OK, ApexSQL Monitor will calculate baselines for defined period and metrics
Now after the baseline is calculated, the user can decide whether to utilize the alerting system to trigger alerts based on predefined thresholds or based on the calculated baseline thresholds
In the Metrics screen, check the Baseline threshold check boxes for the metric that should trigger alerts based on the calculated baseline and hit Save to apply changes
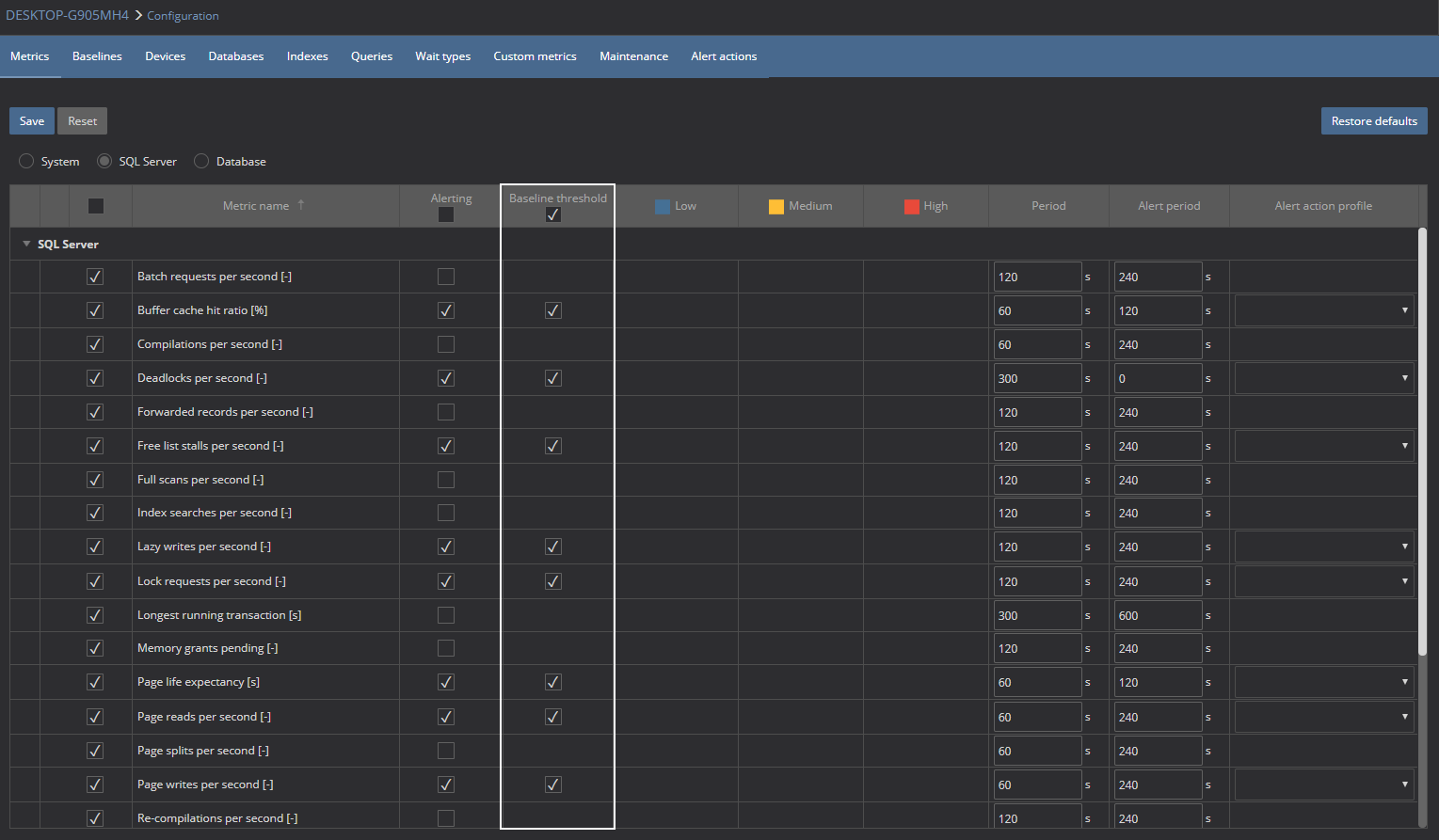
Once this is set, the user is ready to use baselines for SQL Server metrics analysis and troubleshooting
The best way to explain how the baselining could be of great help for investigating SQL Server performances is with some practical examples that will be presented in this article
Let’s take a single performance metric as an example, namely the Utilization of processor time counter. If there are complaints from users that SQL Server is running slow, let’s assume that this metric is what an DBA is going to look for and to check whether there are any abnormal behavior and readings. By looking at the metric itself, it is not easy to determine whether the displayed data in the chart are good or not. Having the raw data does not provide any insight in the system or SQL Server behavior that should be considered normal and what are the values that are not expected and that should be treated as abnormal. Most of the performance metrics are not comply to the established opinions about what the “normal” value boundaries should be. If SQL Server is running normal even when the Utilization of processor time is beyond 90% for example, then this should not be treated as an alert state

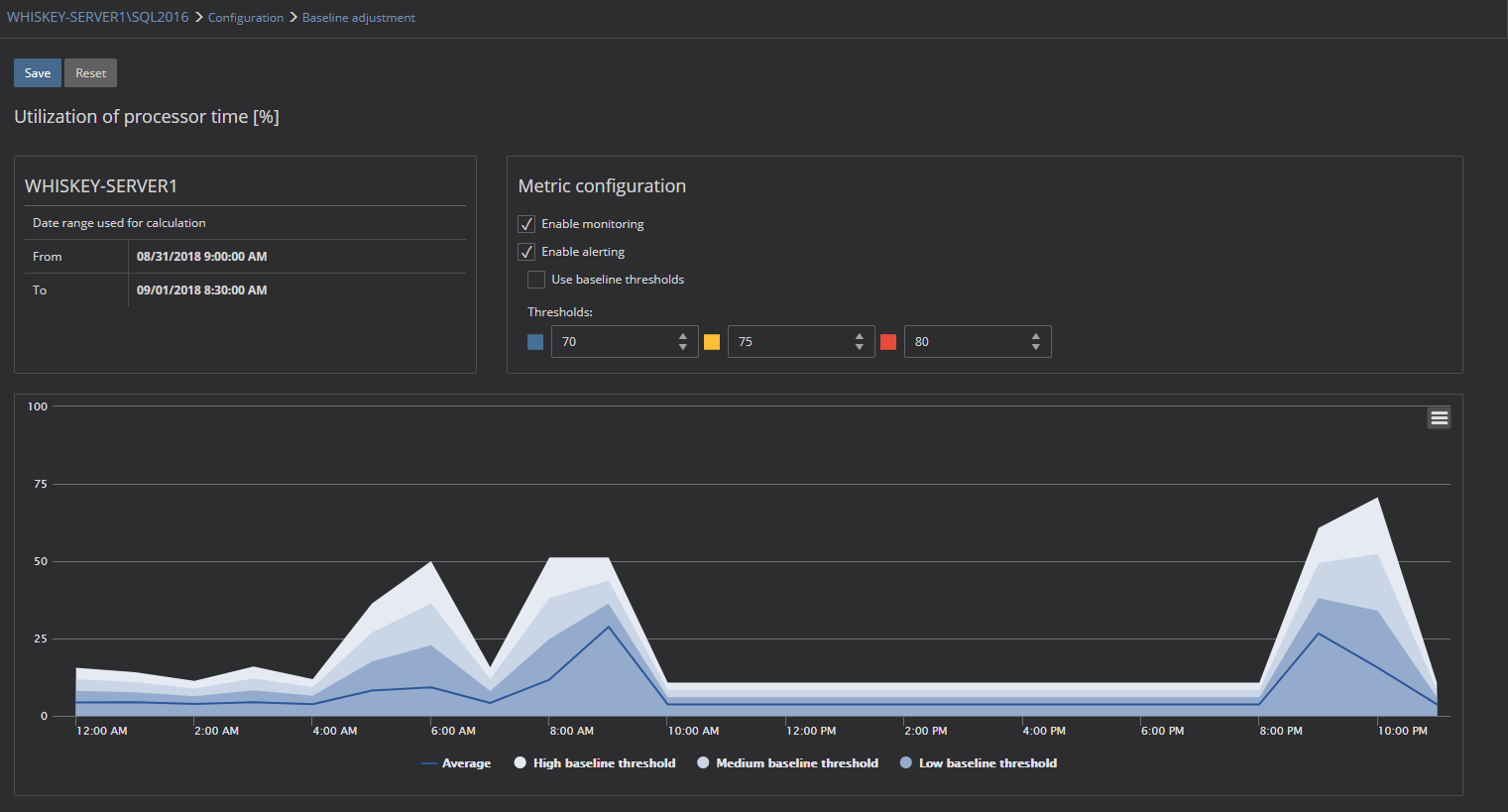
Above is an example of a chart for a one-day period for the Utilization of the processor time metric. As it can be seen, in one part of the day, there is increased activity with high utilization time. The first reaction of a less experienced DBA might be that this is a period where processor utilization time is beyond the established threshold mean and therefor SQL Server performance has degraded. But jumping into such conclusion without all information could be premature
The first thing that must be checked is whether these are the normal values for this specific metric in that specific period of day and whether this could be the cause of the problem, notwithstanding the fact that the metric has higher values. Knowing the regular behavior for a metric, in your environment, that is important, thus it is always advisable to compare metric behavior with a previous “optimal” period. If we assume that this chart shows Monday, then a DBA might need to compare the behavior of the metric for a previous Monday (or even for a few Mondays before the previous just to be sure) as well when the reported SQL Server performance issue didn’t exist. If the metrics behaves regularly like this, then it is highly unlikely that it can be the cause of any current performance issues, if those issues weren’t present in similar periods
The easiest way to check whether the metric behavior should be considered “normal” is to compare to already calculated baseline which will take in consideration such higher or “expected” metric values that didn’t negatively affect SQL Server performance in the past
By looking at the chart it is easy to make valid conclusion now as it is obvious that the high values of the metric are quite normal and within the normal baselined area. Now the DBA can easily conclude that such high values in that period are normal and occurs regularly on Friday probably due to increased activity, and the DBA can start to look at some other causes for the reported performance issue
In contrast to the chart presented above, here is an example where a DBA may want to investigate the metrics values that he can see in this chart. It can be seen that at specific part of the day, there is an unusual activity which caused the metrics values to breach the baseline high threshold even the values are lower than in period displayed in the previous chart
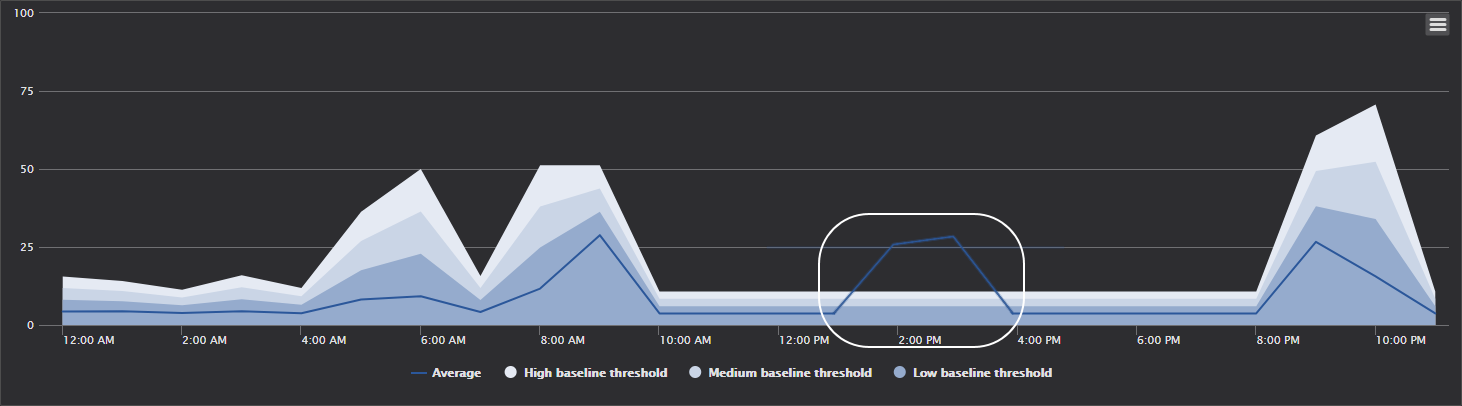
But in this case, thanks to the calculated baseline the DBA can easily notice that this is not metric activity that is usual for that part of the day. This is something that is serious indication that DBA should investigate why such unexpected and obviously non-standard increase in metrics reading occurred in that specific period of day and what could be the cause
An even more evident use case, where baseline use is almost essential is for SQL Server wait statistics. Wait statistic are not something that is straight forward when it comes to measuring and very often, what can be considered as the normal wait time, depends on the specific system used. This can be significantly different between the various systems. Some of the Wait stats types like CXPACKET are almost impossible to troubleshoot without establishing a baseline due to its nature. More about CXPACKET can be found in the Troubleshooting the CXPACKET wait type in SQL Server article
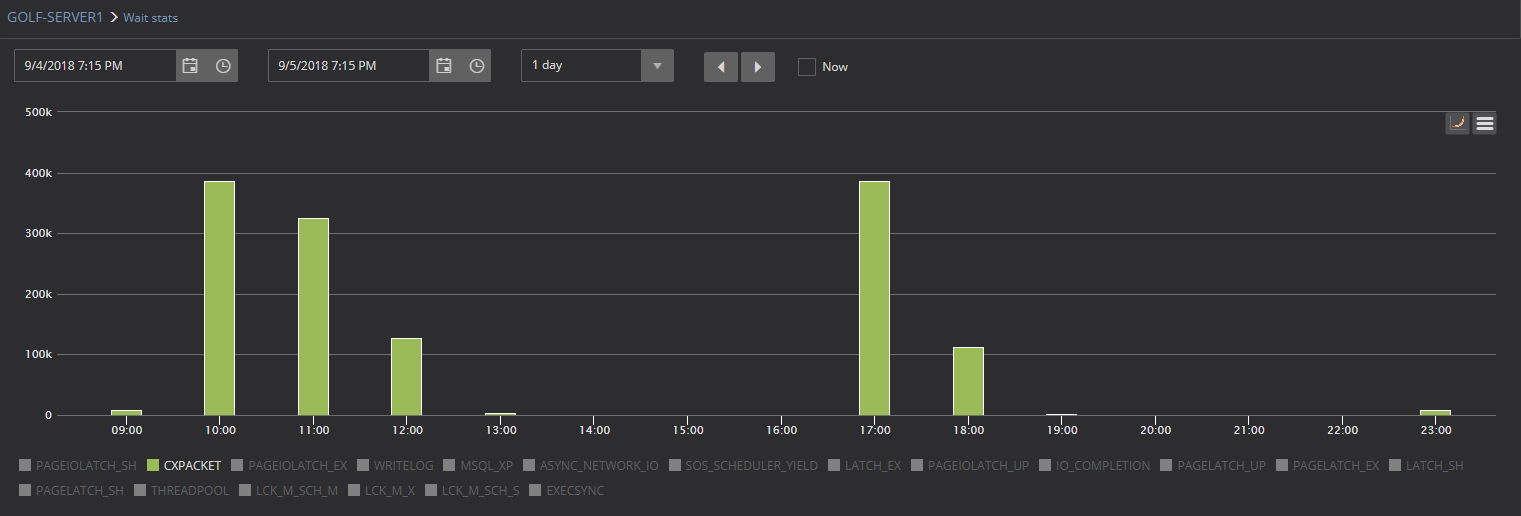
Here is an example of a chart showing the CXPACKET wait statistic, and what can be noticed immediately is that there is a significant increase of the CXPACKET wait stats values in one period of the day. By default, the reaction would be that something wrong occurred and that CXPAXKET is the probable cause of the SQL Server performance issues being experienced. While this could be true, it is not advisable to immediately jump in such conclusion just because of the fact that some higher CXPACKET wait times are measured. As explained in the article, CXPACKET is just possible indication that some SQL Server performance issue might exist, but CXPACKET is also the natural way or SQL Server to record when process is executing in parallel threads, so having a lot of parallel processes could be a good thing, despite early indications to the contrary. And this is the exact reason why wait statistics should be baselined in order to allow proper interpretation and handling
In the chart below the same CXPACKET chart is now displayed with the baseline area to help in better understand the measured CXPACKET wait times displayed. It is now more than evident that the measured CXPACKET values are within the standard SQL Server behavior and that there is no reason for consideration otherwise. Again, we see that baselines represent what is normal SQL Server behavior and even if there are some higher values of CXPACKET visible in the chart, there is nothing that should be investigates, as the similar values were standard for that part of the day. In other words, the variances were in fact normal
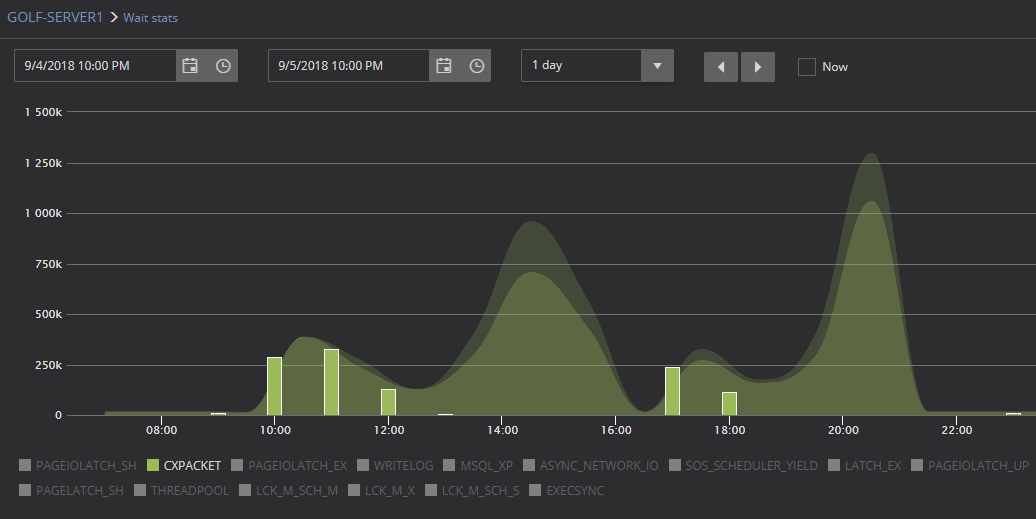
The next chart represents the behavior of the CXPACKET wait type in the same time frame but this time there are a significant spike of CXPACKET waits during one part of the day, and when compared to the baseline, as it is shown below, it is obvious that CXPACKET wait time have much higher values that usually and bars are way above the baseline threshold

Now it is clear that CXPACKET wait time value is way beyond what is the normal behavior and the DBA should review those values to determine the root cause of such behavior; and if necessary to perform actions to bring those values to a normal state
At the end, it is important to understand that systems which have “monolithic” behavior during a period of time, without big difference in high and low usage of SQL Server, fixed predefined thresholds could work quite well when properly determined, and with such servers baselining is not necessary and will not bring some significant benefits
At the other hand, real world scenarios are rarely monolithic when it comes to SQL Server usage, and such predefined threshold systems provide data without actionable information. All this is particularly evident for dynamic systems with significant variance across different periods of time. For them, the only proper way for determining whether the performance metrics values are “good” or “bad” is establishing a baseline of performance counters and predicating investigation and troubleshooting of SQL Server performance issues on that
Another very important aspect of using baselining is in troubleshooting of existing SQL Server performance issues.
When a SQL Server has performance issues, it could be affected by multiple causes and for a DBA it is not necessarily easy to track and understand how the investigation of one potential issue could affect the other.. In this case, baseline calculations of metrics should be performed to actually give the DBA a perception of how bad the situation is and whether the potential performance fix helped and at what level it helped in reducing the performance pressure
In exactly one week after ApexSQL Monitor is installed, a DBA can perform baseline calculations over the collected metrics for that “bad” SQL Server period. Now, it is important to understand that baseline calculated in this way should not be used for alerting as it will actually prevent application from raising the alerts. The only purpose of this should be to track the success of the previous troubleshooting efforts
Here is an example of a SQL Server that is baselined for the period when when performance issues were experienced (in this example the high value of CXPACKET waits)
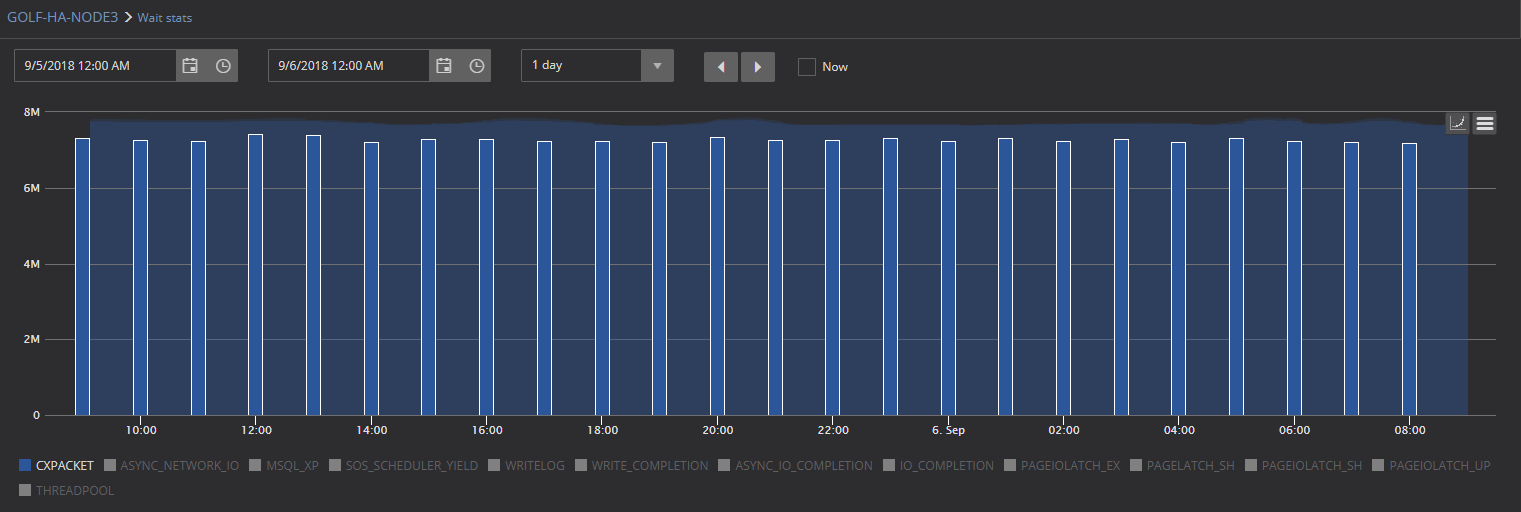
As it can be seen on the screenshot, this is example of how the chart could look like if no troubleshooting and no performance fixes were applied
And now let’s see how this can be used for tracking the effects of performance fixes applied by the DBA
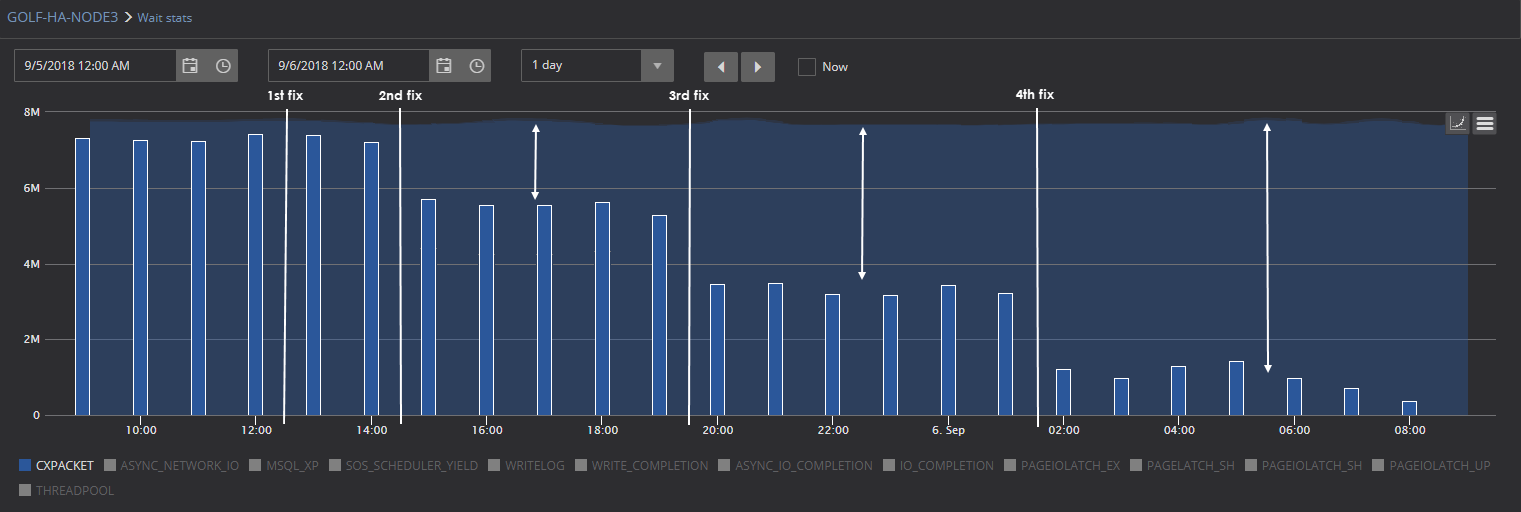
This screenshot shows how the DBA can track the effect of fixes applied to SQL Server vs the problematic baseline. As it can be seen, the first fix applied by DBA didn’t have any effect on the given CXPACKET wait stats metric, but it is obvious that second, third and fourth fix are actually efficient and each fix affected the CCPACKET wait time significantly comparing to calculated baseline, which mean that the DBA has found the way or is on the right track to resolve this particular problem
Of course, it is possible that some fixes, can fail to work as intended and even be counter productive
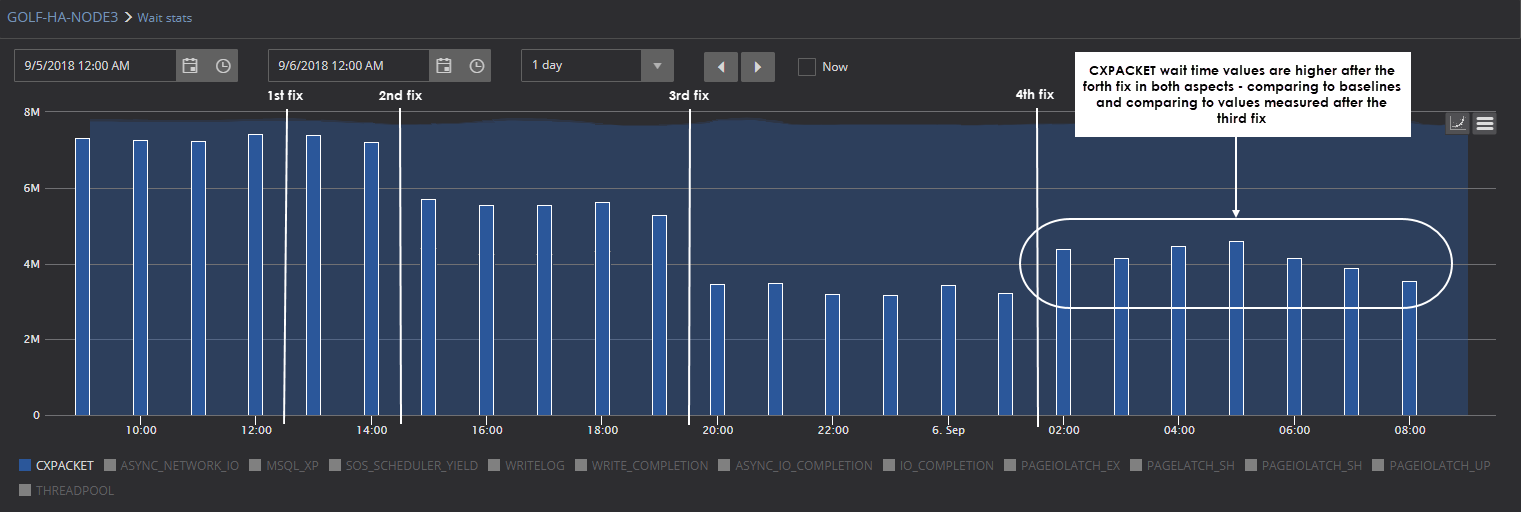
By checking the chart in this particular case, the DBA can spot that the last fix has actually worsened the situation with CXPACKET, because not only are the values higher comparing to the values measured after the 3rd fix, but also comparing to the baselines, so changes applied with the last fix, may need to be reverted and other solutions attempted
Finally, the user must understand that calculated baseline in ApexSQL Monitor is not something that is written in the stone and it serves just as a guide for the DBA to understand what is the “normal” behavior of SQL Server and to help DBA to minimize false positive alerts to allow focus and attention on more likely causes of the issue, faster and more efficiently
A properly calculated baseline is a very helpful tool for DBAs, but when not used as it should (i.e. if used for alerting when baseline is calculated for a period when SQL Server was affected with performance issues) it can actually be misleading, so it is important to use the baseline feature properly
Here are the things that have to be considered when working with baselines feature in ApexSQL Monitor:
When used for alerting, baselines have to be calculated for the time period when SQL Server was not affected by performance issues
Calculated baselines and baseline thresholds serve only as an indication of metrics breaching baseline threshold, but it doesn’t necessary mean that this is the automatically a performance issue. It is rather indication that this discrepancy from the regular behavior, is statistically less likely to be “normal” especially when coupled with other empirical evidence of performance issues, and should be potentially investigated accordingly
If there is the regular breach of baseline thresholds for some metrics in some specific period of time, and if the conclusion after investigating these alerts is that the SQL Server performance is not affected, perform a new baseline calculation, as it will take in account those increased metrics values and will prevent false positive alerts
Baselines should be recalculated when some changes in hardware and software were made that might affect the baseline performance. For example, if circumstances of external factors are changed and instead of having peaks on Monday and Friday, now the peaks are shifted to Wednesday and Thursday and SQL Server performance is still within the normal boundaries and is working without performance issues, the new baseline calculation must be performed. If not, the DBA could expect the excessive amounts of false positive alerts on Wednesday and Thursday, which will likely obscure any “real” alerts
Baseline calculations for the period when the server does have performance issues for the purpose of troubleshooting and tracking the effects of changes is recommended, but it shouldn’t be used for alerting. It is important that after the troubleshooting and resolution, a new baseline calculation should be performed for the “good” SQL Server period, and this new calculation should be then used for alerting
