
-
Title
How to create Copy-Only backups in SQL Server -
Resolution
Creating a foolproof disaster recovery solution is imperative for every business. After the Recovery Point Objective (RPO) and Recovery Time Objective (RTO) are defined, a database backup plan should be created to match these objectives. Most DBAs tend to automate the majority of tasks related to database backup plans. Regular database backup schedules are set in order to create continuous backup chains, that can later be used to recover a database in the case of a disastrous event. By setting the backup schedule, the continuity of the backup process is ensured, and most of the job is performed automatically on a regular basis.
There are many situations when backup files need to be created outside of the regular backup schedule. These backup files can be created manually, in a regular way, with usual BACKUP DATABASE command. But using this approach can prove not always helpful, in the case of a disaster, if we need to restore a backup file that is created after this manual out-of-the-schedule backup operation. Let’s look at the few examples where manual database backup performed out of the regular schedule affects the daily routine:
Database uses simple recovery model
The full database backup is taken daily (at midnight for example) and regular differential backups are taken every hour. This way, the RPO of one hour is ensured. The disaster occurred around 7:30 AM, and DBAs reasonably decided to restore last differential database backup that was created at 7:00 AM. Unfortunately, the restore operation failed with the following message: “This differential backup cannot be restored because the database has not been restored to the correct earlier state”.
Further investigation of backup history showed that another full backup was taken that day at 6 AM. This manual database backup ended the backup chain that starts with the full backup file at 12 AM, and started the new chain. All differentials created before 6 AM use the 12 AM backup as their base. All differentials created after the manual backup at 6 AM use this backup file as a base. Therefore, the 12 AM full backup cannot be used to restore 7 AM differential backup.
In this case, if 6 AM manual full database backup got lost, all further differentials would be useless, and recovery would not be possible for the time up until the next full backup.

Picture 1: Effects of unscheduled full database backup on the differential log backup chain
Database uses full recovery model
One of the greatest advantages of full recovery model databases is the ability to recover a database to specified point in time, provided that all recovery resources are available. This also brings us to the main drawback of the full recovery model: it is necessary to perform regular transaction log backups to prevent uncontrolled growth of database’s transaction log. Storing and maintaining log backups requires additional resources, but once the process gets automated, the benefits often outweigh the effort.
Unlike in the previous case, taking a full database backup outside of the backup schedule won’t affect the transaction log backup chain. This is logical, since a full database backup operation doesn’t truncate transaction log of a database, and all transaction log backups contain transactions committed since previous transaction log backup only. The only exception to this rule is the first full database backup taken after the database is created. This doesn’t mean that we cannot use last full database backup as a starting point when performing point in time recovery. We can use any other available full backup, provided that we have available all transaction log backups created after that full backup, up to recovery point.
In the example, shown in picture 2, an unscheduled full database backup is taken at 9 AM. If the disaster occurred at 12 PM, both 12 AM and 9 AM backup files can be used as the starting point of the restore sequence. Restore sequence 2 would be much faster, but if manual backup file got lost, a restore would still be possible with the 12 AM backup file and subsequent log backups.

Picture 2: Effects of unscheduled full database backup on the transaction log backup chain
For databases in full recovery model, the problem might occur if someone took transaction log backup outside of the regular backup schedule, and misplaced it. The missing log backup creates a gap in the backup chain, and all transactions that were stored in this file will not be possible to recover.
For example, for the low traffic databases, the following backup schedule can be used:
- Full database backups are created daily at 12 AM
- Transaction log backups are created every 3 hoursIf someone took out-of-the-schedule transaction log backup at 10:30 AM, it will contain all transactions that were committed between 9 AM and 10:30 AM. If this file gets misplaced, these transactions will be lost indefinitely, and point in time restore will not be possible for this period.
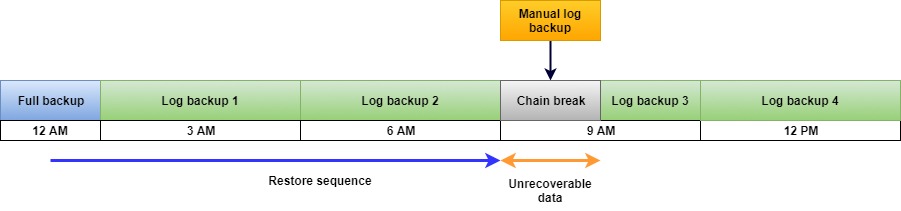
Picture 3: Effects of unscheduled transaction log backup on the transaction log backup chain
Solution
The best way to avoid described issues when taking backup files out of the scheduled time frame is to use copy-only backups. Copy-only backups are independent backup files that do not disrupt the regular Log Sequence Number (LSN) routine. This means that backup chains and restore sequences won’t be affected by the copy-only backup. There are two types of copy-only backups: full database backups, and transaction log database backups. Differential copy-only backups are not supported.
Copy-only full backups can be used with databases in any recovery model. When copy-only full backups are restored, the process and effects are the same as if the regular full backup is restored. The difference is that copy-only full backup cannot be used as the base for future differential backups as shown on picture 4.

Picture 4: Effects of copy-only full backup on differential log backup sequence
If used with the sequence of transaction log backups, copy-only full backup acts in the same way as regular backup. In that case, the situation is identical to the one described on picture 2.
Copy-only transaction log backups work in a same way, but can only be used with databases in full and bulk-logged recovery model. They contain all transactions that were committed since previous regular transaction log backup, and they never truncate the transaction log. This means that the next regular transaction log backup will be able to capture all transactions since previous regular transaction log backup. This way, there is no risk of potential data loss.

Picture 5: Effects of copy-only transaction log backup on the transaction log backup chain
Copy-only backup files can be easily created by using T-SQL scripts, through user interface in SSMS, or with a third-party solution like ApexSQL Backup.
Create copy-only backups with T-SQL scripts
The query that is used to create copy-only full database backup is similar to the usual backup query. The only difference is WITH COPY_ONLY parameter. For the AdventureWorks2014 database, the following query can be used:
-- Query 1: Copy-only full database backup BACKUP DATABASE AdventureWorks2014 TO DISK = 'E:\Backup\CopyOnly_AdventureWorks2014.bak' WITH COPY_ONLY;
Running the query produces the backup file at the specified location:
To create copy-only transaction log backup, use the BACKUP LOG command:
-- Query 2: Copy-only transaction log backup BACKUP LOG AdventureWorks2014 TO DISK = 'E:\Backup\CopyOnly_AdventureWorks2014.trn' WITH COPY_ONLY;
The backup file is created in the same way as in the previous example, but this time the TRN file type is used.

Create copy-only backups in SQL Server Management Studio
To create copy-only backup files by using SSMS GUI, perform the following steps:
Expand the Databases node in tree view of Object Explorer. Right click on the database that needs to be backed up, and click Tasks/Back up… in the context menu.

In the General tab of Back Up Database, specify the database and backup type of the copy-only file. Make sure to check the box for Copy-only backup. Note that selecting Differential backup type disables the Copy-only backup control.
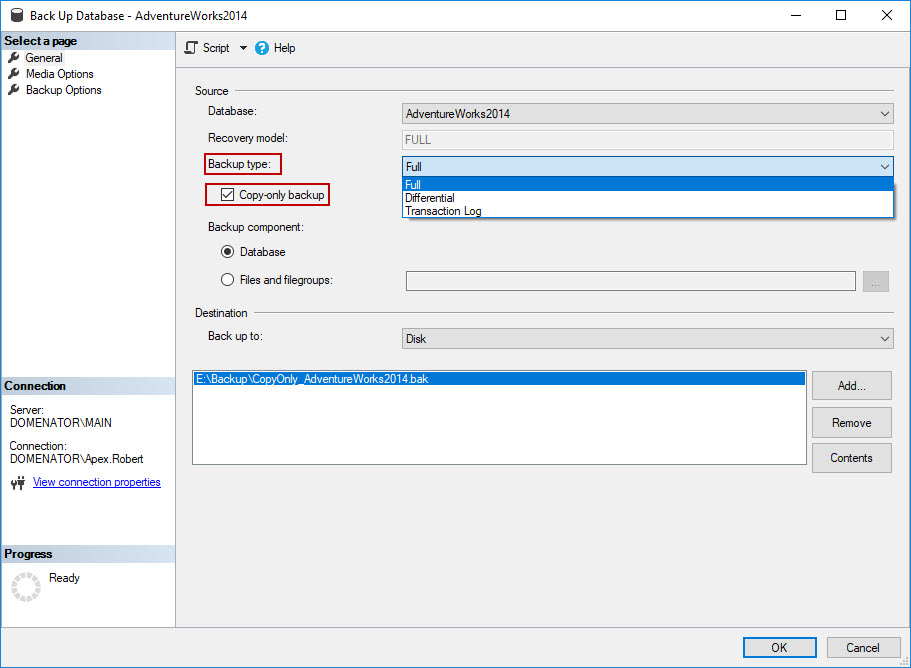
In the Destination section, the name of the last created backup file will be specified. To avoid overwriting this file, click on the Add button, and provide different file path for the backup. Make sure to include the proper name for the backup file in the file path. If needed, use the browse button to locate the backup destination manually.

Click OK button to complete the process with the default settings. The action completes with the success message:
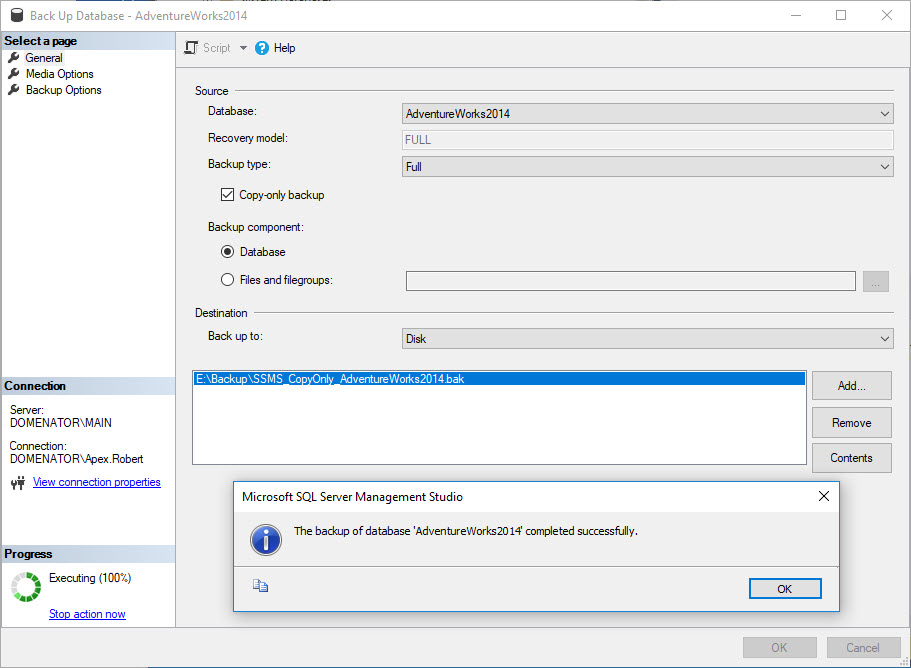
The backup file is located at the specified file path.

Navigate to Home tab, and click Backup button in the application ribbon.

In the main tab of the Backup wizard, specify the server, database and backup type for the backup job.
Optionally, set the network resilience. If the box is checked, the application will automatically rerun the job, in the case that it fails for any reason. This option can be useful if there is a high traffic on the network, and timeout errors are encountered frequently.

Click on Add destination button to specify backup destination. Type the file path in the Folder text box, or browse for the backup destination. In filename box, type the custom name of the backup file, or use tags to generate the filename automatically. By using the tags, the information such as server, instance and database names, as well as backup type, date and time can be automatically included in the file name. Click OK to confirm the selection.

This brings us back to the Backup wizard. If needed, set the schedule for this backup operation at the bottom of the page.
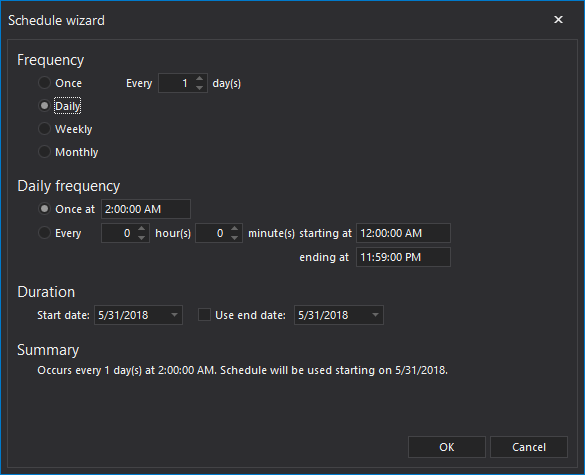
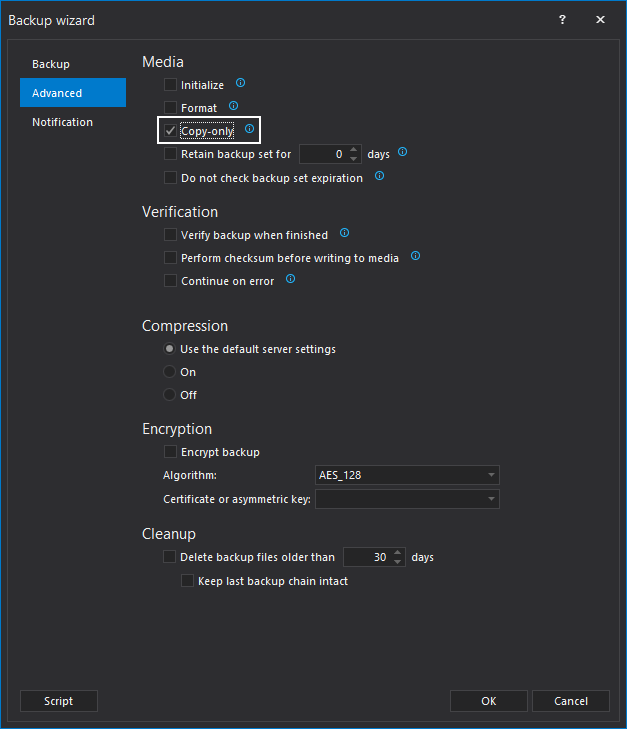
In Advanced tab of the backup wizard, check the Copy-only option. Optionally, check additional options regarding media sets, verification, compression and encryption.
If needed, set email notifications for the created task. Click OK button to execute the job. If a schedule was specified in step 5, the backup job with all defined parameters is created. If not, all commands are executed immediately. In this case, the backup schedule is created, so it could be reused at any time when the need arises.

To run the created schedule, navigate to Schedules tab. Check the box in front of the created schedule, and click Run now button.
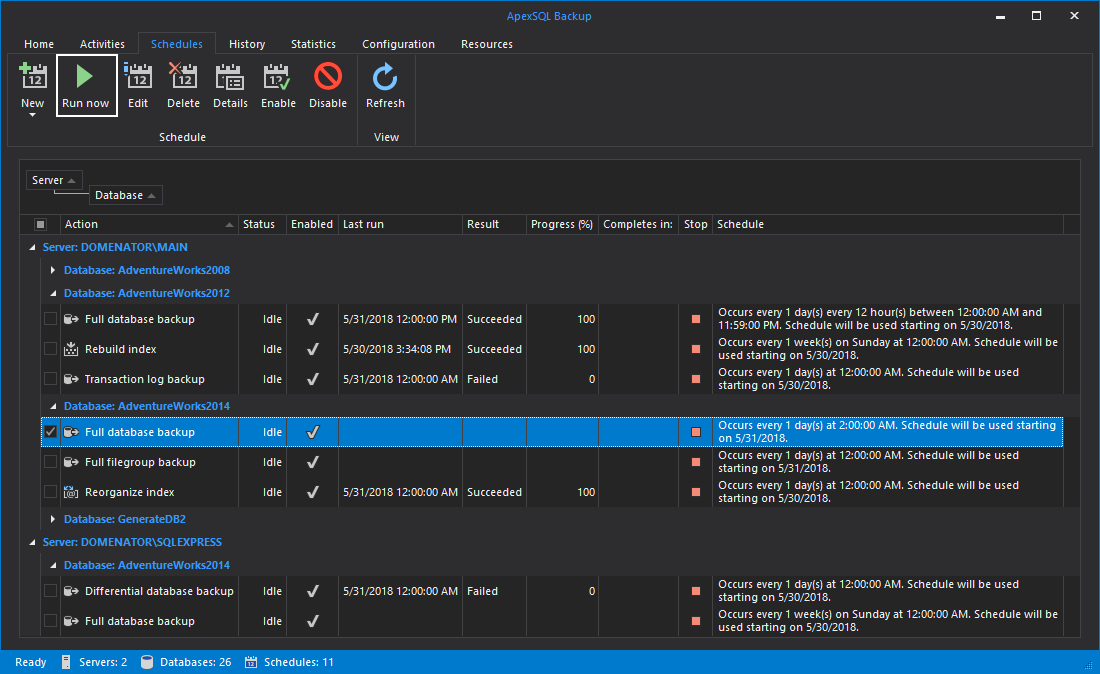
As soon as the schedule completes, Last run and Result columns are updated with corresponding data, and backup file is created on specified location.



Quick tip:
Copy-only backups are supported in all SQL Server versions, starting with SQL Server 2005. However, the copy-only backup files cannot be created through SSMS 2005 user interface, but only with T-SQL script. All later versions of SSMS have the copy-only option available.
Create copy-only backups with ApexSQL Backup
ApexSQL Backup is a 3rd party solution that also supports copy-only backups. The files are easily created and managed through GUI, even for the SQL 2005 databases. To create the copy-only backup file with ApexSQL Backup, perform the following steps:

One of the greatest advantages of ApexSQL Backup schedules is the reusability: the schedule can be disabled (to save hard disk space), and run manually only when there is a need for the copy-only backup. Parameters for the job can be reconfigured at any time with Edit button. Information on job status is available as soon as the job completes.
All actions performed through ApexSQL Backup, including the creation of copy-only backup is recorded in ApexSQL Backup central repository. Best way to check on these actions is through Activities tab, where all performed tasks are displayed in the grid.

Related pages: